


Having a resilient data pipeline for your business is becoming a necessity to stay competitive in these times where vast amounts of data are being generated and consumed. Data is not only being generated by financial and other business-related systems, but also by a whole new realm of applications built for the Internet of Things (IoT) and edge devices. The data being generated can be structured, unstructured, time series data and or, streams. Data should be captured using one system and data analysis should be performed using another system in order to maintain separation of concerns. Data pipelines can be defined as building and operating a set of data systems arranged in a composable manner for capturing, processing, analyzing, and storing business data.
Containers allow you to focus on a single area of concern, whether application-data capture, application-data storage, and/or application-data analysis. Container orchestrators like Kubernetes can help deploy, manage, and scale containerized components of modern cloud-native data pipelines. In order to create an end-to-end resilient data pipeline in Kubernetes, you have to compose a set of systems that are scalable, auto-healing, easy to observe, and easy to operate using Kubernetes orchestration.
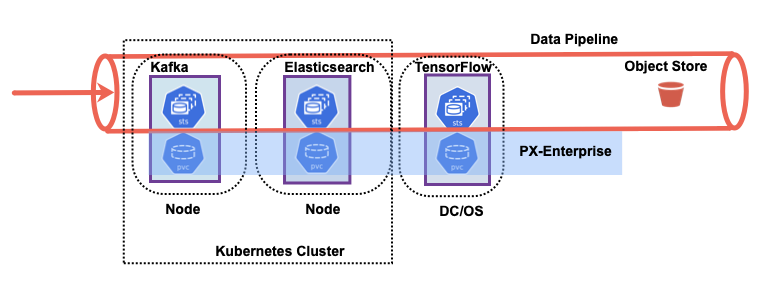
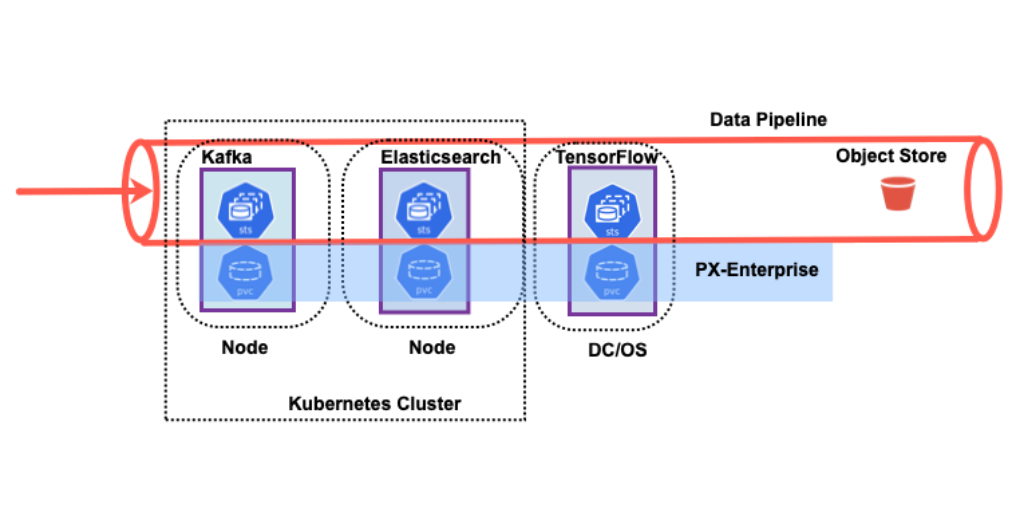
A data pipeline can be composed of many systems, with varying scale and dimension. We will walk through a particular data pipeline composition and discuss the data pipeline elements:

In the example above, you will notice that each stateful application in the data pipeline has its own architecture for high availability. Each application can also have varying levels of replication factors and self-recovery mechanisms. Managing data recovery at only the application layer can potentially increase the end-to-end latency of your data pipeline. Because the Portworx platform is application lifecycle aware, your end-to-end pipeline latency will remain relatively constant during application pod restarts or reschedules in a Kubernetes cluster.
The Portworx data platform can help your composed data pipeline reduce end-to-end latency by understanding the lifecycle of the application elements in the pipeline. For instance, Portworx with PX-Motion, can help you migrate an existing pipeline element to a new Kubernetes cluster when you need additional capacity. Portworx can help the data pipeline elements with:
If you have questions about how the Portworx platform can help your organization with data protection and data portability when running on cloud native container orchestrators, please reach out to one of our Portworx experts and request a demo.



