What is Cassandra in Kubernetes?
As a developer, you need a large-scale cloud application. Cassandra clusters are the databases of choice for these applications. When used together with Kubernetes, you are taking advantage of the leading orchestration platform for the deployment and management of containerized systems held within the cloud.
Understanding Cassandra Kubernetes is the first step to utilizing two extremely powerful tools for your organization.
These two applications work in tandem for better outcomes. First, what is Cassandra, what is Kubernetes, and how does Cassandra Kubernetes work together?
What is Cassandra?
Cassandra is an open-source and free wide-column store. At its heart, it offers users a NoSQL database management system with the power to handle large amounts of data contained across several commodity servers. There is no single failure point in Cassandra deployment and high availability.
There is even support for clusters and nodes across multiple data centers, allowing you to tackle any project, no matter how big or small.
Enjoy asynchronous masterless replication to guarantee low latency for every client. The easiest way to view Cassandra, or k8ssandra, is a combination of the Bigtable storage engine and data model from Google and the distributed storage and replication techniques of Dynamo from Amazon.
The origin of Cassandra comes from Avinash Lakshman, one of the authors who worked on Dynamo. Another of its authors is Prashant Malik, who worked on the development of Cassandra for Facebook. Today, it powers Facebook inbox search, and in July 2008, it was released to the wider community as an open-source project.
But why the name Cassandra? The Facebook development team dubbed their new project “Cassandra” due to the name’s allusions to an oracle’s curse.
What is Kubernetes?
On the other hand, Kubernetes is there to automate software development, improve scaling, and make managing such projects simple. It was designed by Google before being passed onto the Cloud Native Foundation to oversee the project’s future.
Kubernetes is compatible with other platforms and programs like Containerd, CRI-O, and Docker. Organizations across the world offer platforms based on the Kubernetes model in the form of Infrastructure as a Service (IaaS) packages.
The name Kubernetes comes from the word “helmsman” and was announced in mid-2014 by Google. The founders of the project were Beda, Burns, and McLuckie. Since its founding, other Google developers joined the project to expand its capabilities and make it into what it is today.
Cassandra on Kubernetes for a More Powerful Approach to Technology
Major companies ranging from Netflix to Uber have used Kubernetes Cassandra to grow their tech stacks.
When you deploy or manage an application on Kubernetes, it is easy to miss the complex orchestration that occurs. The scale and size of modern cloud applications mean that it can be challenging to find a dependable partner for the Kubernetes system.
View a Cassandra YAML example, and you will see why it is the most logical pairing around. There is no doubt that Kubernetes is the ultimate orchestration platform for launching cloud-based distributed applications, but you need a dependable distributed database environment to maximize the benefits.
Cassandra is that partner.
Cassandra has proudly grown the tech stacks of major companies across the world for many years. Executive development teams favor it for its scalability and strength. Any company using large-scale cloud applications relies on Cassandra to ensure their services never stop running.
A Cassandra Kubernetes operator knows that bringing these two platforms together keeps their data and operations closer. It all adds up to a dream team driving for superior performance.
Why Run Cassandra with Kubernetes?
Cassandra Kubernetes is no more than the classic story of modern infrastructure repeated again and again. Before “cloud native” became a thing, the development team behind Cassandra was inspired by the modern distributed storage features and replication methodologies of Amazon’s Dynamo and the model of Bigtable from Google.
This team asked about the potential of bringing the benefits of these platforms into a single package. The result was more resiliency and availability for those complex large-scale cloud applications.
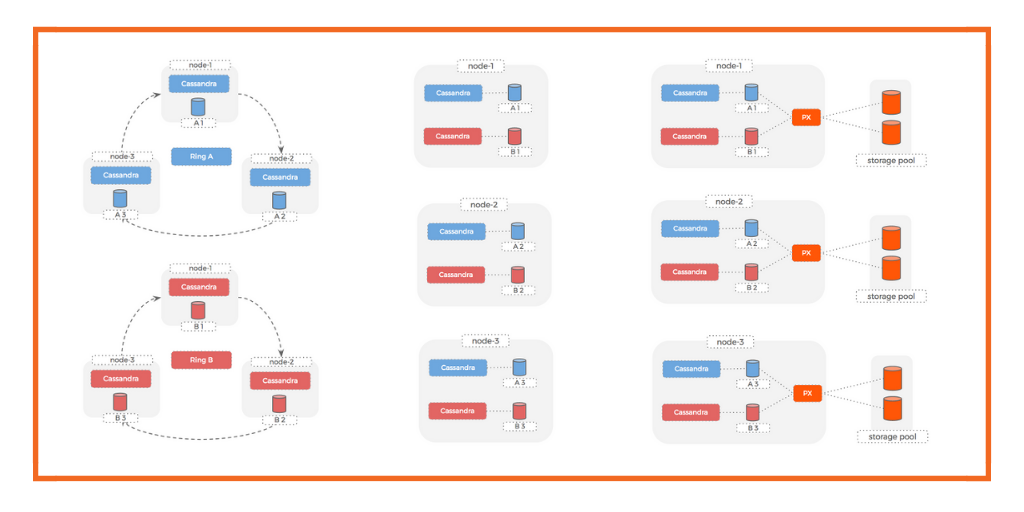
The main difference between Cassandra and Kubernetes is that Cassandra shares nothing within its architecture. Its nodes share no storage capacity or memory with other nodes. In contrast, Kubernetes is centered around the control plane, the primary node.
The purpose of this primary node is to offer additional fault-tolerance, hence where the resiliency for large-scale cloud applications originates.
You can argue that Kubernetes and Cassandra are both distributed systems, and that is because they are. They recognize that the requirements of apps operating on a global basis continue to snowball. Handling the mammoth amounts of data produced today means that multinationals need the infrastructure to support that data.
Scaling
Horizontal and vertical scaling are essential facets of handling data within the cloud in the modern business landscape. Kubernetes does provide horizontal and vertical scaling in the same way that Cassandra does.
Both are node-based systems. The benefit of using nodes is that developers can scale both ways. They may expand their infrastructures or shrink their infrastructures as and when required.
The key to scaling up and down is that no downtime is required, and no third-party solutions are required to make it happen.
It is a simple matter of telling K8s how much resizing needs to happen and allowing it to happen without impacting your storage databases or public-facing services.
The power of scaling makes businesses better able to pivot and confront the challenges facing them on the cutting-edge of data ecosystems.
Elasticity
Nodes are not centered nor permanent. Developers can add or remove nodes dynamically. Developers can build applications that automatically scale based on spikes in demand. It is why well-known services like Uber and Netflix do not simply crash whenever new code is released.
Dynamic additions and removals of nodes allow distributed applications to take advantage of additional resources to continue to operate during periods of peak load.
The elasticity of Cassandra Kubernetes enables businesses to only pay for the resources they use, rather than maintaining idle resources on the books.
Self-Healing
Problems are bound to happen when developing and deploying cloud-based distributed applications. The advantage of using these Kubernetes is it will redeploy failed apps instantly. Cassandra also simplifies the process of recovering failed nodes without risking data loss.
Spotify already uses Cassandra to replicate data between its U.S. and EU data centers. The power of this function is found within the music personalization system operated by the platform. Should any single center experience some form of failure, healing happens without any concerns over disruption to customers.
Self-healing means that development teams can continue to produce apps that have a high degree of reliability, making it a function that is extremely valuable to companies across the globe.
The Logical Dream Team
Look to the standard architecture found within distributed systems for why Kubernetes and Cassandra work so well together and perform similar things.
These systems act as a team because they both have basic similarities. Yet, at the same time, nodes act independently and communicate via an entire network for superior coordination and data exchange.
Nodes are the heart and soul of this logical dream team because of how they work within the field of distributed computing. As a basic unit of scale, Cassandra overlays on a Kubernetes cluster. The concerns of storage, network, and independent computing allow these two platforms to co-exist without experiencing too much friction.
The only difference is the K8 central control plane.
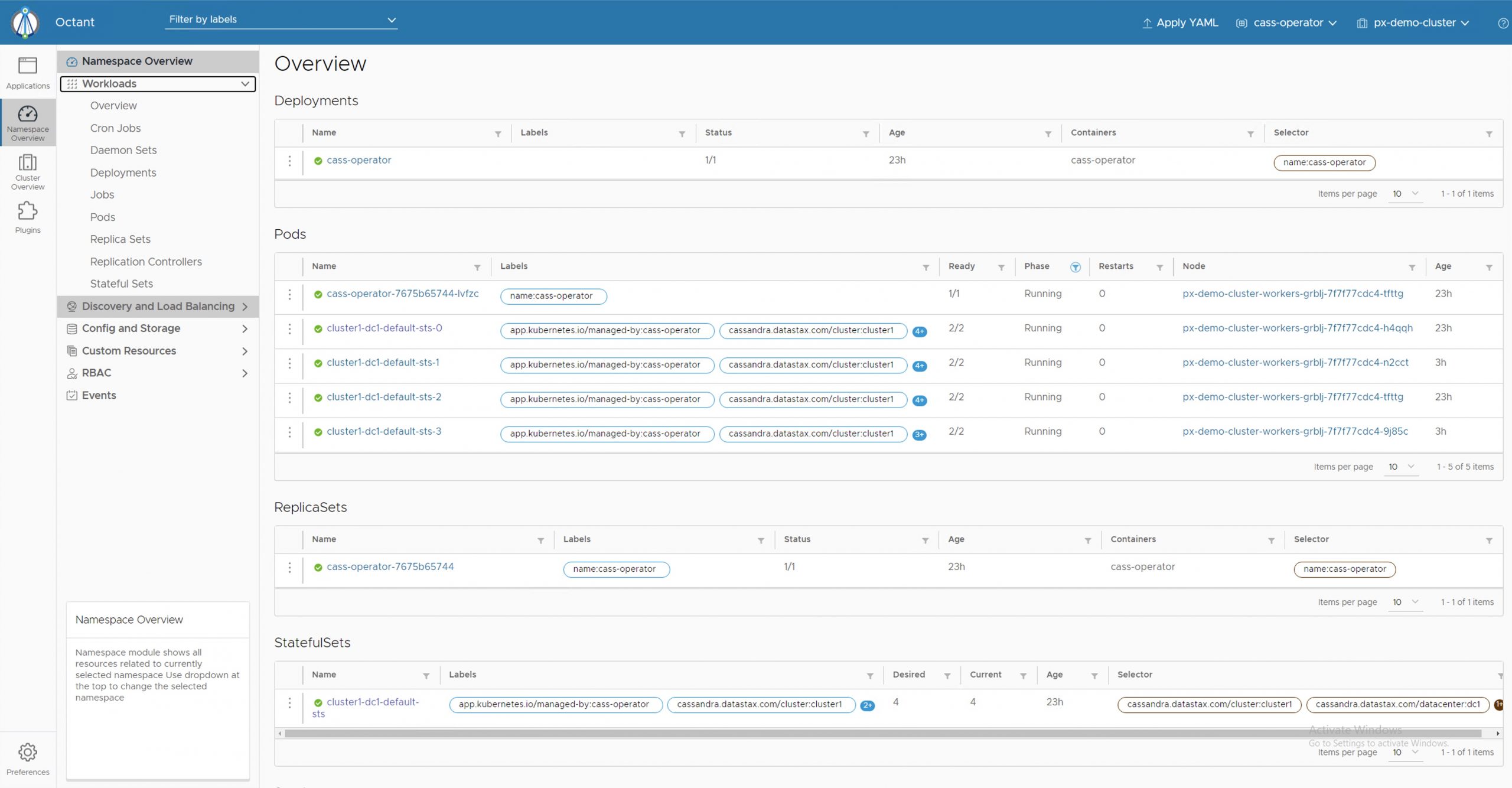
How to Run Apache Cassandra on Kubernetes
Viewing aspects of the deployment process, such as a Kubernetes StatefulSet example, makes running Apache Cassandra on Kubernetes more complex than it needs to be.
Even though there are complexities involved in running them simultaneously for the first time, the Cassandra community has produced several tools to simplify the process.
Identifying the chief challenges associated with the process and the current solutions as part of your plan can streamline the overall process.
The Challenge
Kubernetes has a limited understanding of how databases function. It is blind to the operating system requirements of whatever database you have in use. If you want to script or take advantage of the existing functionality of Kubernetes in running Cassandra, you must put in a significant amount of effort.
Kubernetes is known for increasing the complexity of a system, making it harder to manage. Without careful management, you risk missing your target of managing loads, containers, and mitigating complexity.
The Solution
Install Cass Operator (via Helm) to reduce those complexities. This was developed by the open-source following attached to Cassandra. Operators using Cass Operator create a more logical interface, making describing the lower-level components of Kubernetes simpler. Cass Operator gives you a translation layer pairing what Kubernetes needs to function and the required implementation of the database.
Several operators have attempted to solve the same problem, including Sky UK and Instaclustr. Cass Operator was the final result, with several merged features from various contenders.
Bear in mind that the goal of any operator using Kubernetes is to make it easier to set up, scale, and maintain the complex configurations involved with Kubernetes containers.
By using Cass Operator, you have already taken a great leap forward to creating a simplified, logical interface.
How to Simplify Deployment
Helm is pivotal to making Cass Operator work. The best way to view Helm is that it is the equivalent of apt or yum.
The purpose of Helm is to deploy charts in a similar manner to a packaged application. It is the total collection of your pre-configured and versioned application resources. Helm allows you to deploy them as part of a singular, unified unit.
Your goal when bringing Kubernetes and Cassandra together is to deploy everything as part of a single Helm chart. Thankfully, there are so many options available for you to take advantage of.
Many veteran Kubernetes users have their go-to options for this process. Discover the one that is best for your organization. Every company has its own needs. Take the time to identify them and experiment with various options until you find the one that works for you.