




This post will answer the question “How can I reduce Cassandra recovery time?” by investigating the Cassandra bootstrapping process and demonstrating how Portworx replication avoids this costly operation.
Cassandra is a capable, cluster-aware database. It can partition and replicate your data across multiple nodes. Originally developed by Facebook in 2008, it became a top-level Apache project in 2010.
By increasing the replication factor for a keyspace, there are a few advantages:
The second point is the focus of this blog post: By using a Portworx volume for your Cassandra container, you can further increase fault tolerance and speed up recovery time beyond what Cassandra replication is able to provide alone.
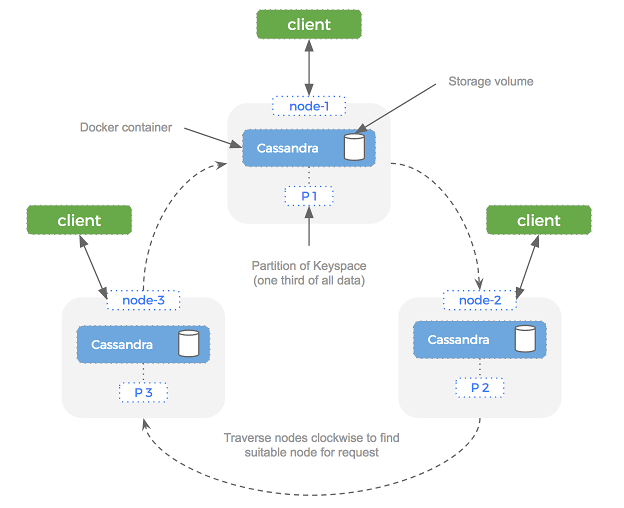
Cassandra clusters consist of multiple nodes in a collection called a ring. No node in the cluster is deemed more important than the rest — there are no master and slaves.
This vastly simplifies operations because nodes can simply be added and removed to the cluster, and there is no single point of failure. The term ring comes from the way Cassandra traverses nodes in a clockwise order until it finds a node suitable for the current operation.
Most Cassandra users agree that its replication model is one of the features that makes the database stand out from other relational or NoSQL options (source).
To simplify access to data in a Cassandra cluster, you can make reads and writes to any node in the cluster. Cassandra will route this request to the correct node, meaning you don’t need to worry about what node you are connected to versus which node actually has the data.
To control replication in Cassandra, you alter the replication factor.
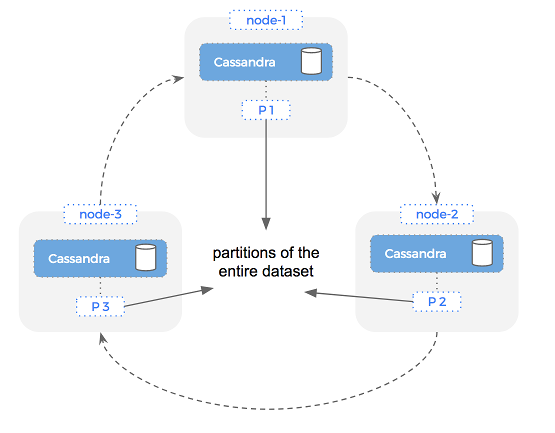
The replication factor is set per keyspace (equivalent to a database in MySQL) and controls how many copies of the data reside across the cluster. For example, let’s say we have a single keyspace on a 3 node Cassandra ring.
With a replication factor of 1, we would expect that there are no extra copies made of the data. Cassandra will still distribute the data for a single keyspace across the three nodes, meaning each volume has roughly one third of the entire data set.
The obvious downside here is that we are prone to data loss if one of the nodes has a problem. If we increase the replication factor to 2 – it means there are two copies of the entire data set across the cluster. Cassandra is smart about how it places each partition, so we can now lose one node and still have our entire dataset:
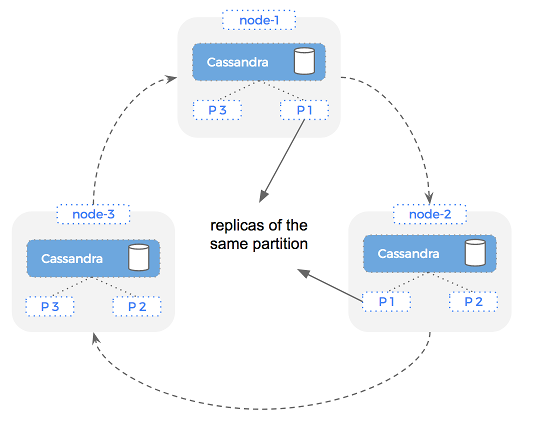
This is important because it means if a node fails it means we still have a copy of our dataset (albeit less copies). Because any node in the cluster can serve a request – it means we are highly available and should have no downtime.
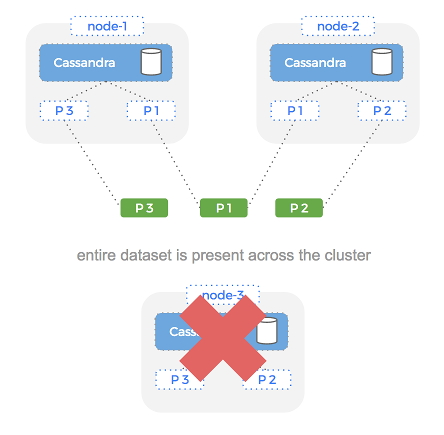
With that background out of the way, let’s take a look at what happens when a node in our Cassandra cluster fails.
Let’s assume that we have a readily available pool of brand-new nodes that are happy to take the place of our unfortunate failed node. The issue is that this new and willing replacement has no data — its disks are blank, as we would hope if we are practicing immutable infrastructure.
This is where Cassandra replication can do a cool trick using the bootstrap and repair operations.
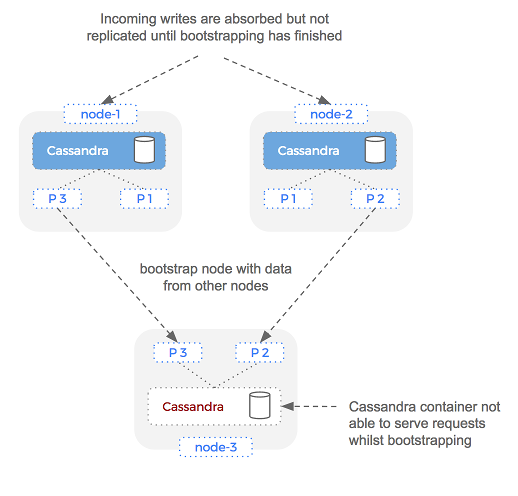
Bringing a new node into the cluster requires two steps: bootstrapping and repair. The bootstrapping stage is where a new node joins a Cassandra cluster and needs to catch up on all the data it should have. During this process, we are unable to absorb new writes on the bootstrapping node.
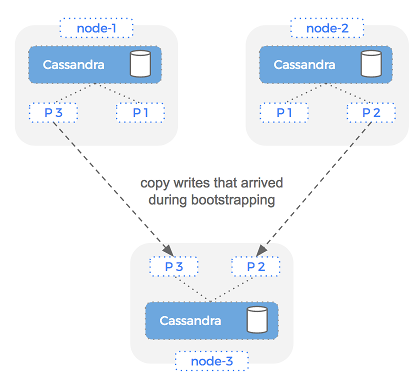
Once a node has been bootstrapped, there is a second operation that must take place: repair.
Imagine that the bootstrap operation starts at Time n and ends at Time n+5. Since writes can happen between n and n+5, a second operation is required once bootstrap is complete. This is called node repair and is accomplished using “nodetool repair”.
Importantly, bootstrap and repair must happen serially. This means that we have to wait until all data has been copied to the new node before we can confidently say that our cluster is working at full capacity.
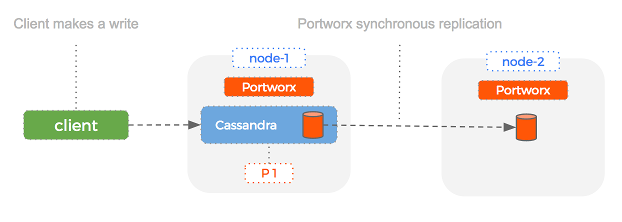
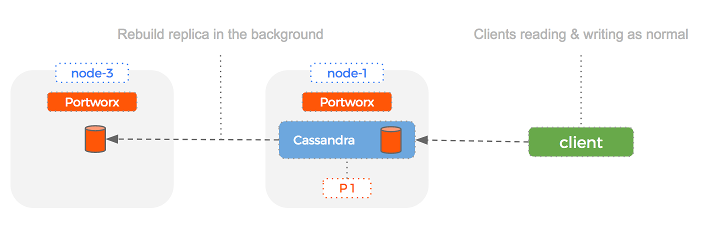
Let’s take a look at how Portworx replication works and how we might use it to reduce the failover time taken in the example above. Portworx replication is synchronous and done at the block layer. This means that we can transparently replicate a single Cassandra volume multiple times, giving us a backup to use if something fails.
Here is a setup of a simple Cassandra and Portworx cluster with Cassandra replication set to 1 and Portworx replication set to 2:
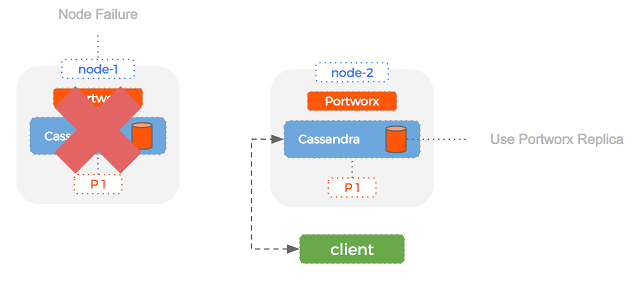
Because Portworx uses block layer replication, the Portworx replica of the Cassandra volume is identical. This means that if the node with our Cassandra volume fails, we can immediately switch over to our Portworx replica. Essentially – Portworx is creating a backup volume that we can use to slide and replace in the event of a node failure. This bypasses the bootstrapping phase completely and drastically reduces the amount of time taken to failover a Cassandra node.
How does this work? Let’s image the same scenario as above where we have lost a node which is replaced by a new empty node. With Cassandra only, we’ve seen that we’d need to bootstrap and then repair the new node before we can serve reads and writes and that this might take some time.
With Portworx however, we can immediately use one of the Portworx replicas for the new Cassandra container and start absorbing writes. This will happen much faster than the bootstrap operation of Cassandra alone. We can serve reads for data up until the failure and once we have run the “nodetool repair” command, our cluster is up and operational again.
Basically the new Cassandra node will come up with the same identity as the node that died because Portworx is replicating the data at the block layer.
Then, all the Cassandra admin will need to do is run nodetool repair to resync any changes that were lost while the node was failing over and the cluster will be functioning at full capacity.
In this scenario, where we have just lost a node from our cluster – Portworx has helped us to recover quickly by allowing the replica of the volume to be used right away.
In the background, whilst serving requests immediately, Portworx will be busy using block layer replication to create another replica in the case of another node failure.
The key to this process is to use the lower layer Portworx replication to add resiliency and failover to a single Cassandra volume. This helps us reduce recovery time but what if we wanted to increase our read/write throughput at the same time?
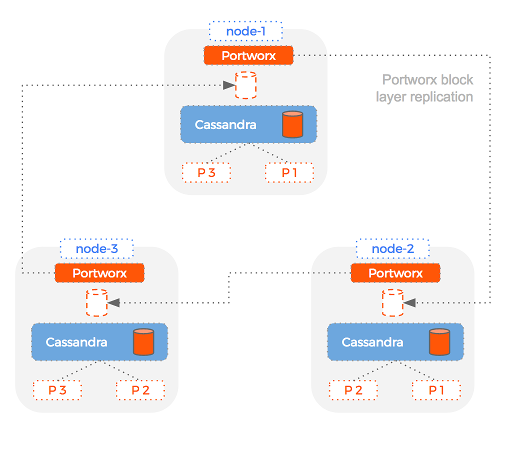
What if we combined the two types of replication in a single cluster? We could get the best of both worlds:
Essentially, Portworx offers a backup volume for each Cassandra volume enabling a slide and replace operation in the event of failover. Compare this to the bootstrap operation and you can see how Portworx can reduce recovery time.
By using a replicated Portworx volume for your Cassandra container and then turning up Cassandra replication, you get the best of both worlds: high query throughput and reduced time to recovery.
To summarize, the key to reducing Cassandra recovery time is:
Take Portworx for a spin today or check out these additional links:



