According to a recent survey, 55% of respondents noted backup and restore as a top requirement for stateful applications running on Kubernetes. In addition to this, organizations also want a unified backup and restore solution that can help them protect containerized applications running anywhere (public cloud and on-premises). Backup and recovery is no longer a “nice to have”—it is now a “must have” requirement for customers who want to run Kubernetes in production. Portworx understands these requirements, and PX-Backup 2.1 allows organizations to protect their applications regardless of the type of storage they consume (block or file) or the underlying infrastructure that they run on. Prior to the introduction of PX-Backup 2.1, Portworx supported Kubernetes backup and restore for applications consuming block storage from major cloud providers like Amazon EBS, Google Persistent Disk, and Azure Managed Disk. This was in addition to the block and file support for applications running on Portworx PX-Store and CSI-based local snapshots. With PX-Backup 2.1, Portworx can now support backup and restore operations for applications running on ReadWriteMany (RWX) persistent volumes provisioned from file shares like Amazon EFS, Pure Storage FlashBlade, or any NFS server.
In this blog, we will focus on how users running applications on Amazon EKS with an Amazon EFS-backed storage class can leverage PX-Backup as their Kubernetes data protection tool, without the need to migrate from Amazon EFS to Portworx PX-Store for their Kubernetes storage.
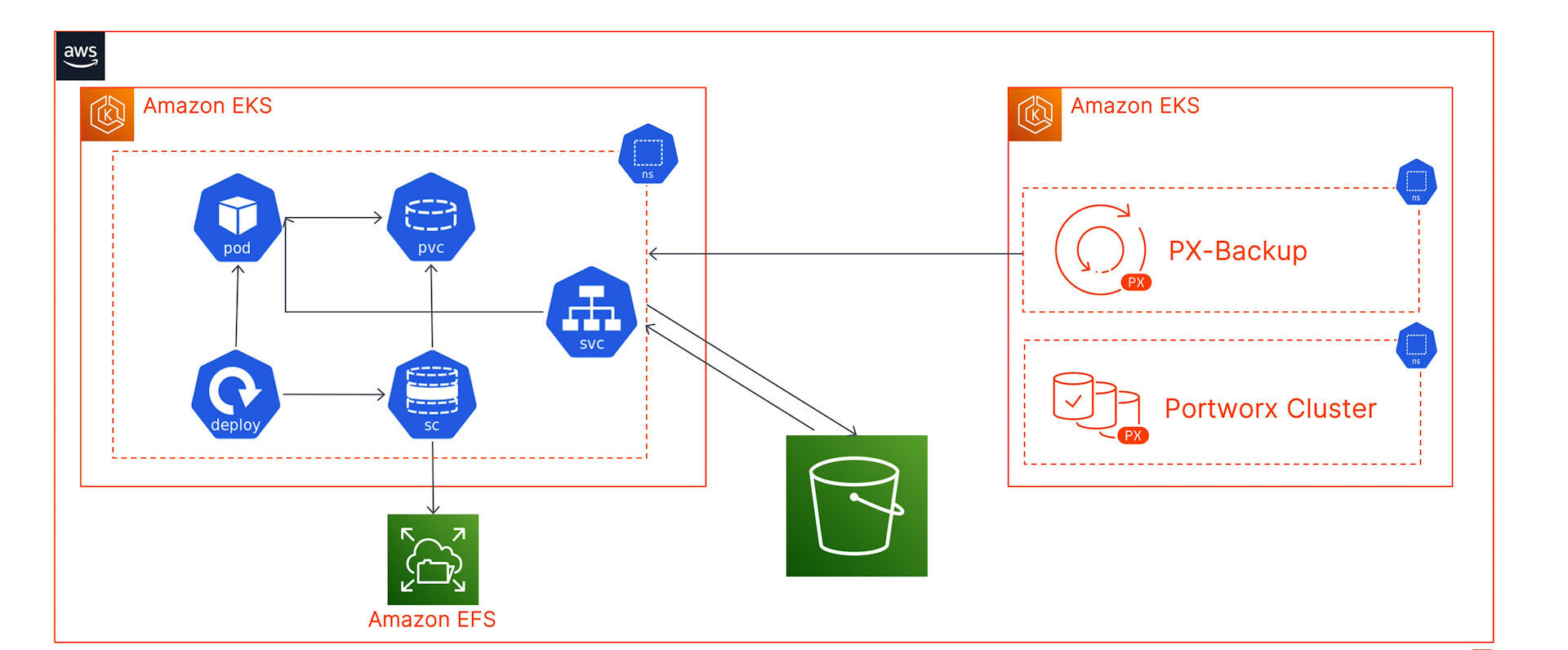
For this blog, we have deployed an Amazon EKS cluster (target cluster) in the us-east-1 region and have configured the EFS CSI driver to dynamically provision ReadWriteMany persistent volumes for our Jenkins installation. Jenkins stores all its logs, cloned repos, plugin configurations, and build artifacts into a Jenkins Home folder. In this blog, we will look at how we can protect this Jenkins Home folder backed by an RWX persistent volume running on your target cluster using PX-Backup.
We have also installed PX-Backup 2.1 on a second dedicated Amazon EKS cluster, configured our AWS cloud account, and added an AWS S3 bucket as our backup repository.
Next, let’s walk through the process of adding your target cluster to PX-Backup and back up our Jenkins installation:
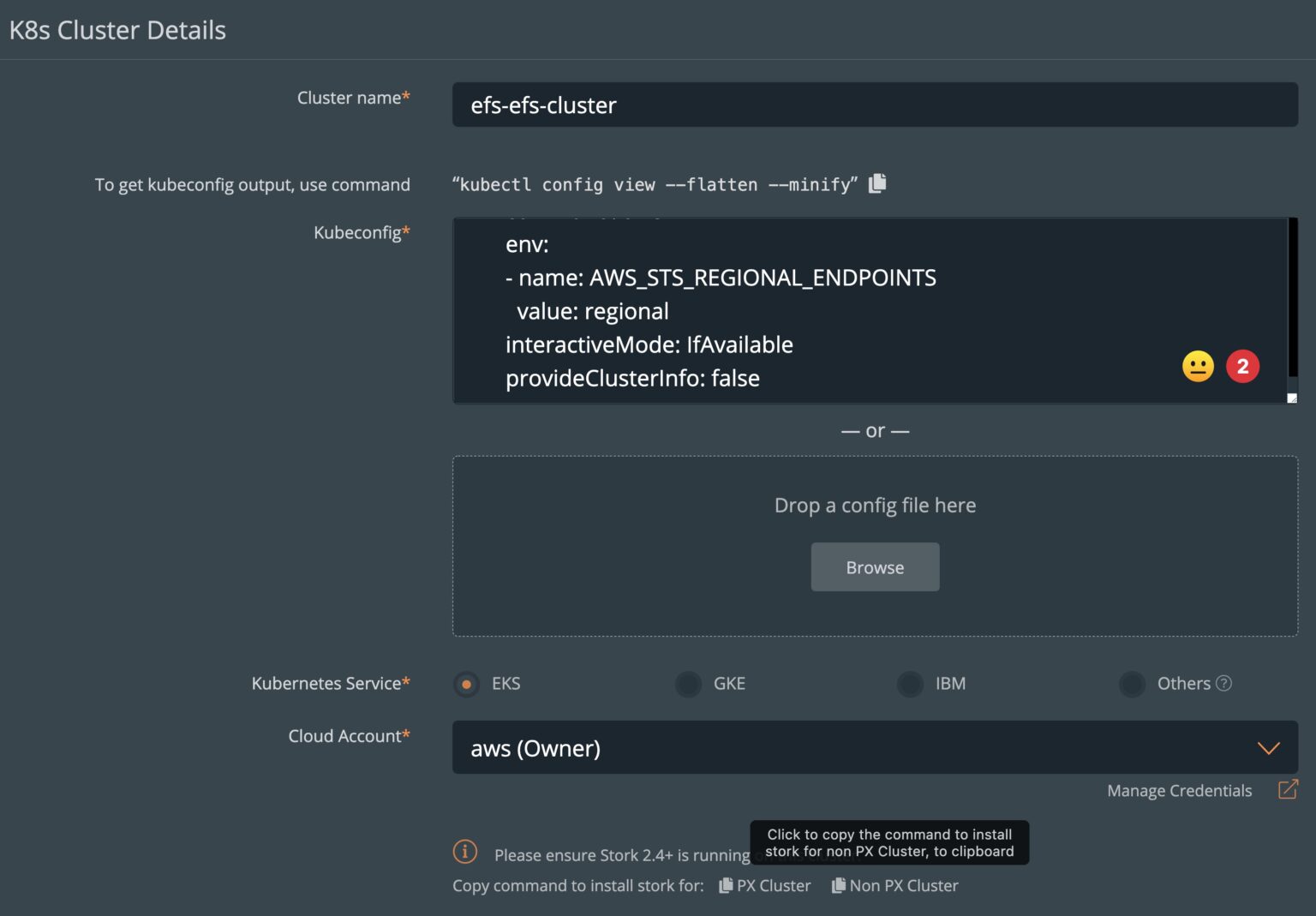
Navigate to the PX-Backup UI and click on Add Clusters in the top right from the dashboard.
Here, you can enter the name of the cluster, the output of the “kubectl config view –flatten –minify” command, and select EKS and the AWS Cloud account that we have preconfigured.
Since we don’t have Portworx running on the target cluster, we will install Stork version 2.8 on our cluster. You can copy the command from the PX-Backup UI or use the one below:
Stork deploys pods on your Amazon EKS cluster using a deployment object, and it is the only component you need to install on your Amazon EKS cluster to use PX-Backup. Stork acts as an abstraction layer between the underlying EFS CSI storage provisioner and PX-Backup. Stork enables PX-Backup to perform the following tasks:
Install the required CRDs on your target cluster
Execute backup and restores on the target cluster
Use data movers to push Kubernetes resources and data to the configured object storage location
Once you add your target cluster, you can navigate to the dashboard and select the target cluster. PX-Backup will automatically inventory your cluster and identify all the different namespaces configured.
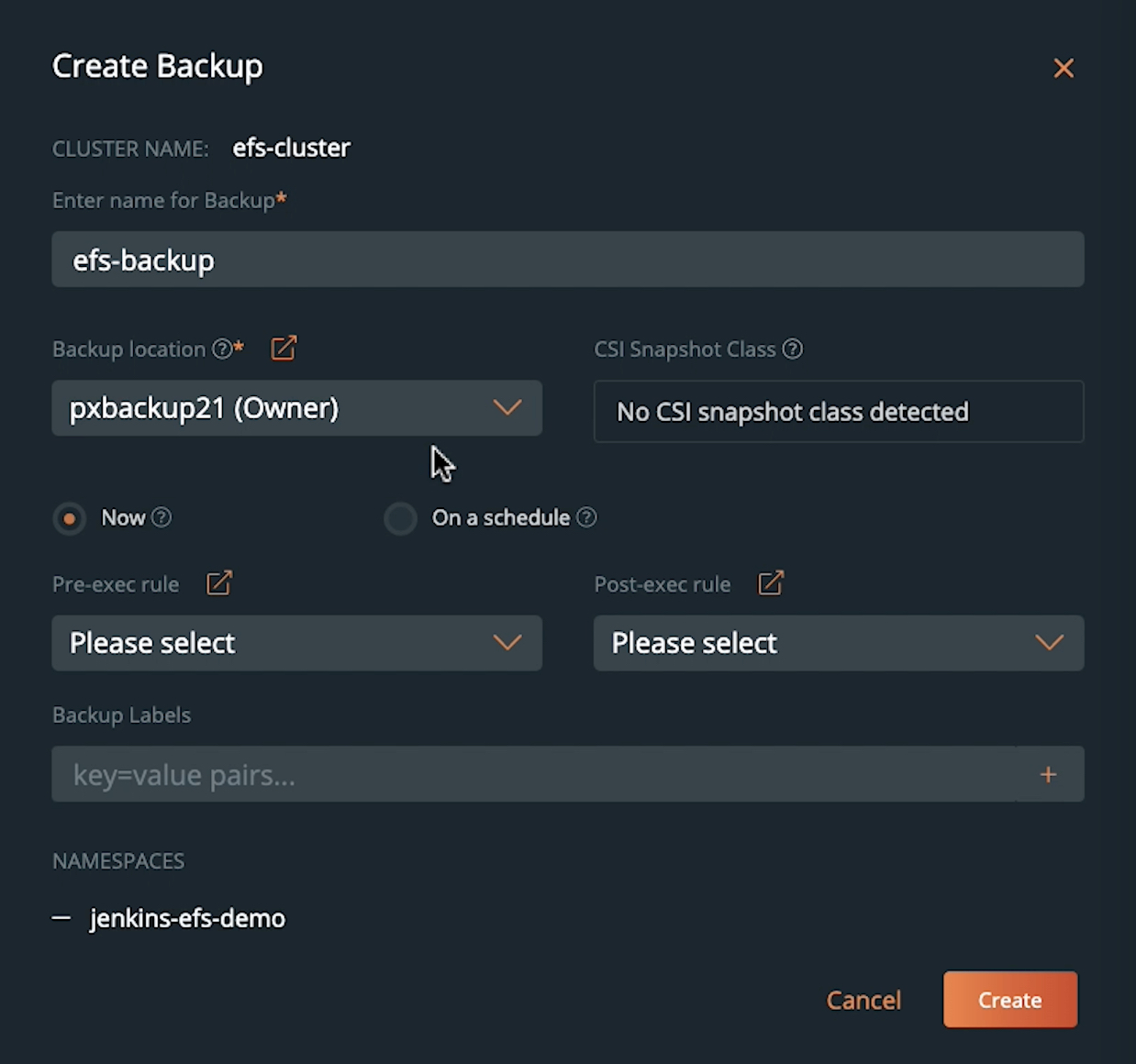
Let’s select the jenkins-efs-demo namespace and create a new on-demand backup job. We will give the backup job a name, select our S3-bucket as the backup repository, and select Now for an on-demand backup job. Optionally, you can also configure this backup on a periodic, daily, weekly, or monthly schedule with pre- and post-backup rules for application consistency.
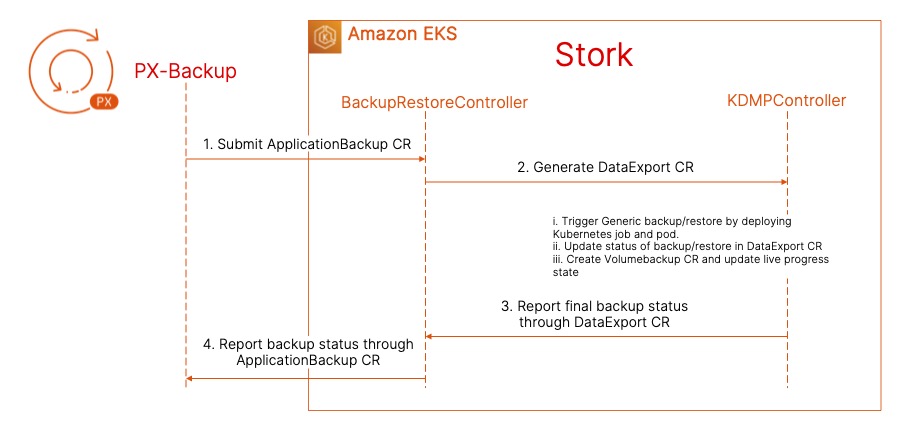
Once you hit Create, PX-Backup will talk to Stork running on your target cluster and initiate the backup operation by creating an ApplicationBackup custom resource (CR). At this point, Stork will run a check to see if the persistent volume in the jenkins-efs-demo namespace is backed by Portworx PX-Store, Amazon EBS, Azure Managed Disk, or Google Persistent Disk. Since we are using an EFS-backed persistent volume, Stork will default to a generic data mover to copy your persistent volume and store it in the backup repository. The ApplicationBackup CR will create a DataExport CR, which creates a new Kubernetes job and a pod to perform the backup operation. The EFS-backed PVC will be mounted inside the backup pod, which copies the data to an S3-backed backup repository. Once the persistent volume is copied successfully, Stork will back up all the Kubernetes objects and application config and report a backup successful status to PX-Backup.
Now that you have a successful backup operation, you can use this snapshot to restore your Jenkins deployment to the same cluster and same namespace, to the same cluster and different namespace, or to a completely different cluster backed by Portworx as well.
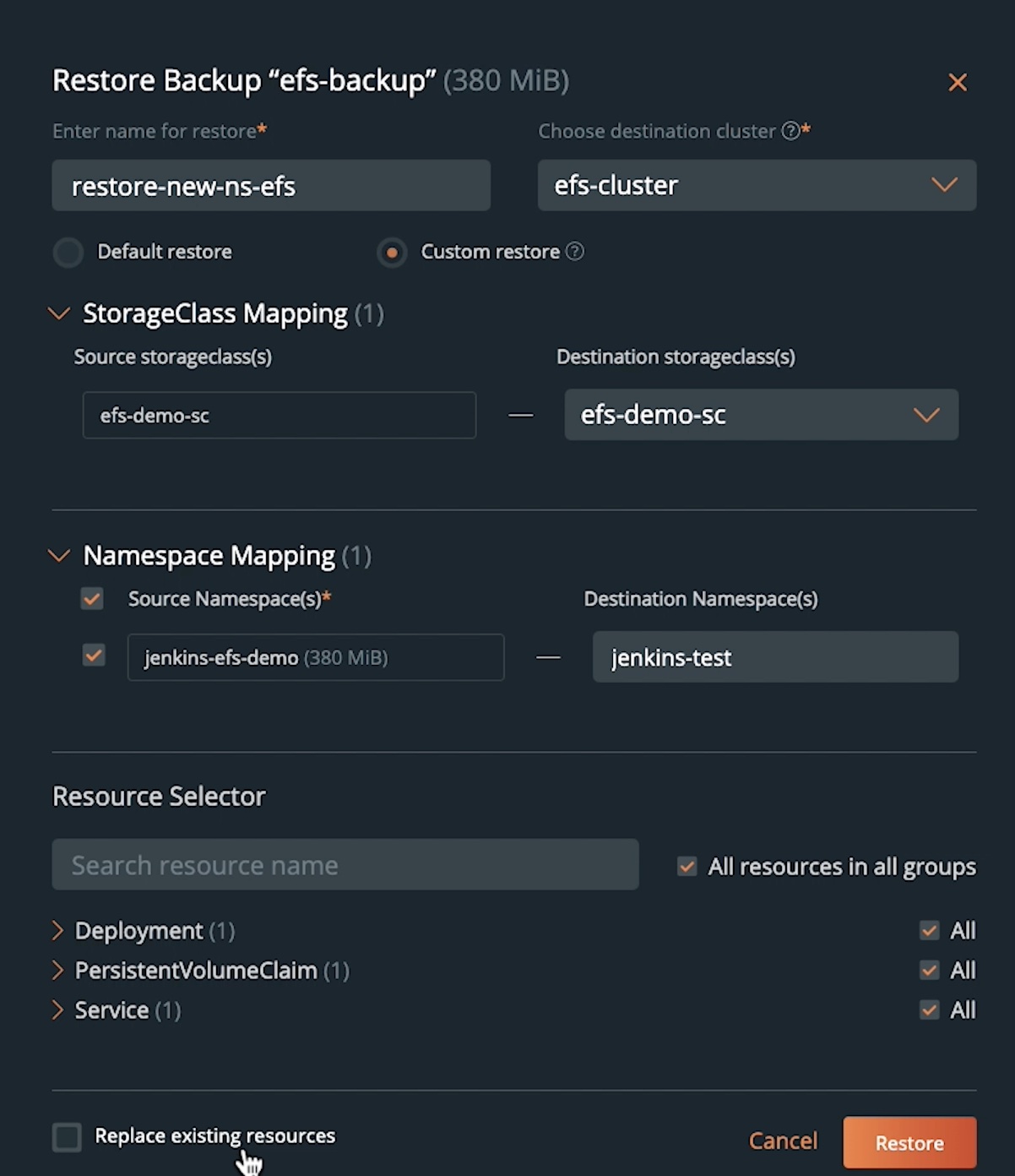
To perform a restore operation, select the backup snapshot, and click the button on the right and hit Restore. You can enter a name for a restore operation and select your destination cluster. For our first restore, we will restore our Jenkins deployment to the same cluster but a new namespace to highlight an EFS-backed persistent volume backup to an EFS-backed persistent volume restore.
We will select a custom restore, and under StorageClass Mapping, we will select the original efs-demo-sc storage class, which dynamically provisions an EFS-backed persistent volume. For the namespace, we will select a new namespace called Jenkins-test. For the resource selector, we will select All resources in all groups to restore everything from deployments to persistent volumes in our target namespace. Once you hit Restore, PX-Backup will create an ApplicationRestore CR using Stork on the target cluster, which creates a DataImport CR with a restore Kubernetes job and a pod. Stork will create a new persistent volume using the efs-demo-sc storage class, and once the PV is up and running, we will restore the Jenkins deployment, pod, and service objects to restore our Jenkins application.
Once the restore is successful, you can navigate to the Jenkins dashboard using the new load balancer endpoint, log in using the same credentials, and verify the artifacts and plugins that were configured on our original Jenkins setup.
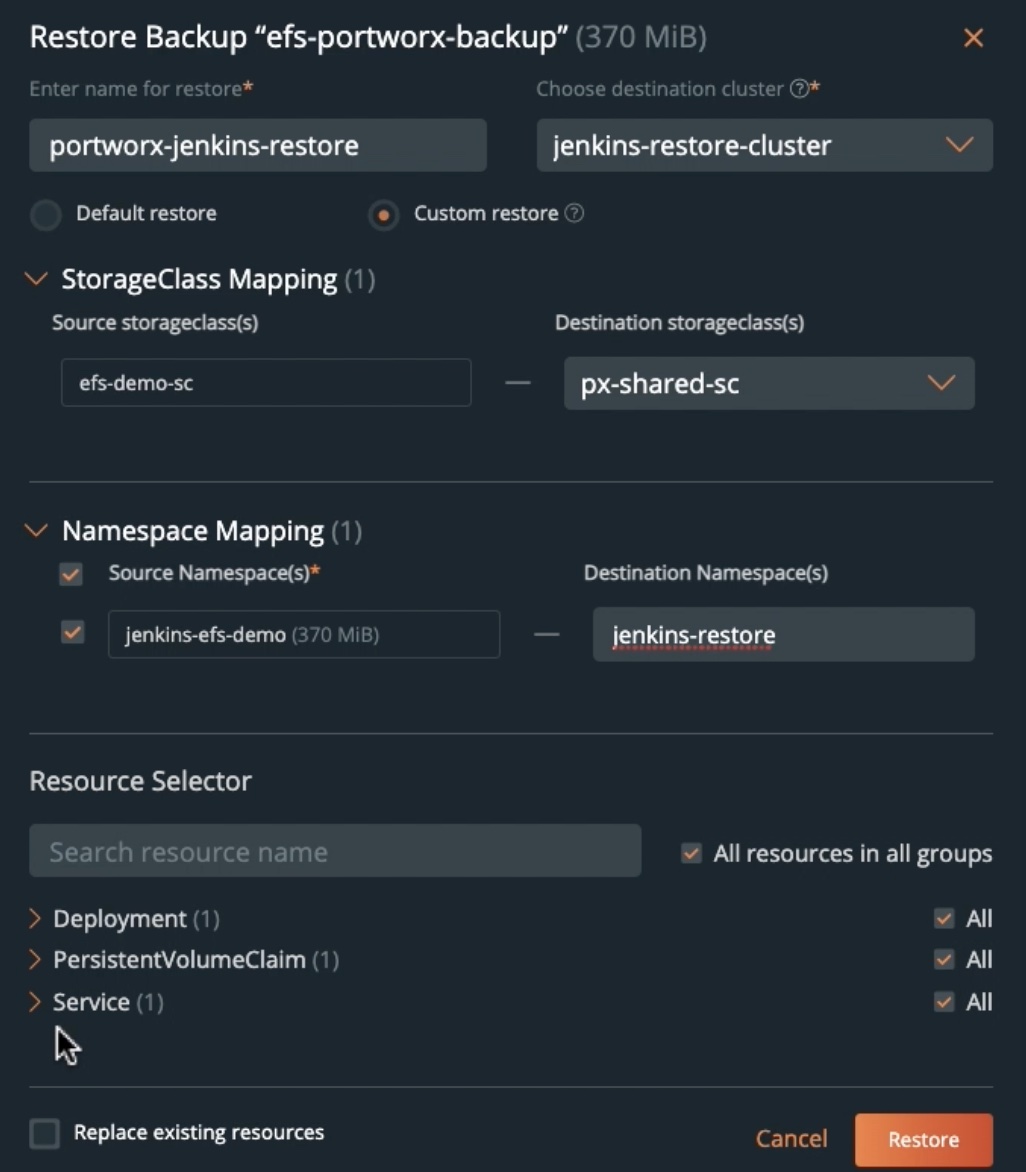
With PX-Backup 2.1, you can back up an application running on an EFS-backed storage class and restore it to a Portworx-backed storage class. This helps you migrate from using different CSI-based solutions for block (EBS) and file (EFS) to a single unified enterprise-grade solution for your Kubernetes clusters.
To restore our Jenkins deployment to a Portworx-backed cluster, you can navigate to the backup snapshot that you want to restore from and click Restore. You can give the restore operation a name, select an Amazon EKS cluster that is backed by Portworx, and then under Custom restore, we will select a new Portworx storage class that will dynamically provision ReadWriteMany persistent volumes for your application.
You can select an existing namespace that you want to restore to and select All resources in all groups to restore the entire application.
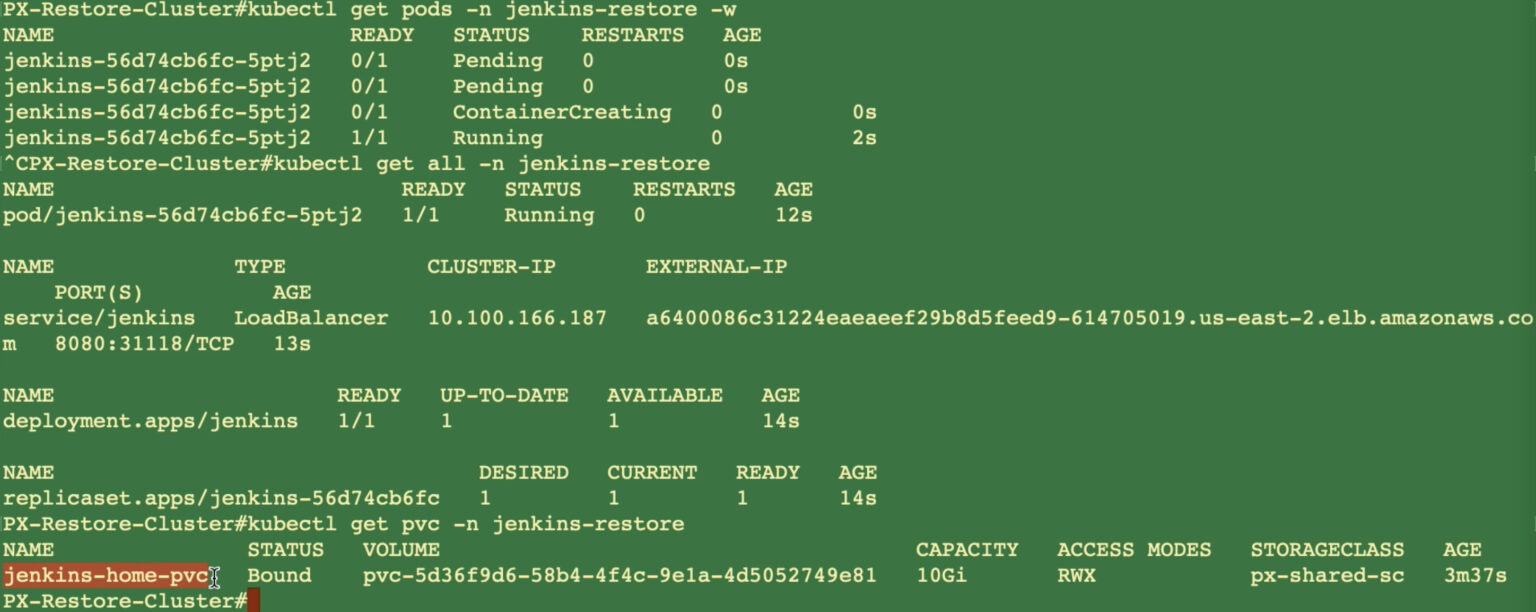
Once you click Restore, PX-Backup will work with Stork on the new Portworx-backed EKS cluster and perform the application restore for you. Upon successful completion of the restore operation, you can use the CLI to verify that your application is successfully restored and your persistent volume is backed by a Portworx StorageClass.
You can also navigate to the new load balancer endpoint and verify that all the different Jenkins artifacts and plugins are restored successfully as well.
This is how easy it is to use PX-Backup to perform backup and restore operations for your Amazon EKS clusters backed by an Amazon EFS filesystem. You can also check out a couple of demonstrations below, where we walk through the two scenarios we discussed in this blog.