

PostgreSQL on Kubernetes: Step-By-Step Guide for running PostgreSQL on the Most Popular K8s Platforms
Kubernetes provides container orchestration capabilities that enable deploying and managing applications in a distributed platform, including complex databases such as PostgreSQL.
This post will walk you through deploying PostgreSQL on Kubernetes platforms, including a detailed step-by-step guide, deployment strategies, benefits, configurations for monitoring, backup, and restore, and best practices.
What is PostgreSQL?
PostgreSQL is a popular open source relational database system with a strong reputation for data integrity, flexibility, and SQL compliance. Small and large enterprises commonly use it to manage complex data-intensive applications.
What are the benefits of PostgreSQL
PostgreSQL offers several distinct advantages that set it apart from other database systems, making it a popular choice among developers and enterprises worldwide. Here’s what makes PostgreSQL stand out:
- Free and Open Source: PostgreSQL’s open source solution provides significant cost savings and does not require licensing. It enables you to customize and expand the database to meet specific needs.
- Advanced Features: PostgreSQL’s advanced features make it a highly flexible database system that can manage complex and diverse data requirements. It supports advanced data types like arrays, vector, key-value pairs, XML, and JSON/JSONB, for semi-structured data. It also has built-in full-text search capabilities that enable users to search and retrieve data easily.
- Extensibility: PostgreSQL allows users to tailor the database to their specific needs beyond what most traditional databases provide.
- High Performance and Scalability: PostgreSQL is designed to conveniently manage huge volumes of data. Its features, such as indexing, partitioning, and parallel processing, improve performance for complex, data-intensive applications.
- Strong Security Features: PostgreSQL has strong security features such as row-level security, data encryption, and fine-grained access control. These features help businesses manage data access and protect sensitive information more effectively.
What is Kubernetes?
Kubernetes is an open source container orchestration engine hosted by the Cloud Native Computing Foundation. It automates containerized application deployment, scaling, and management.
At its core, Kubernetes helps you manage and run your applications by maintaining their desired state. You configure how you want to run your application (resource requirements, networking rules, number of replicas), and Kubernetes handles the complexity of scheduling it across clusters. So, if a container crashes, Kubernetes automatically restarts it and reschedules all affected containers.
This automatic orchestration allows running large-scale distributed systems with minimal manual intervention, making it the de facto standard for running cloud native applications.
What are the benefits of Kubernetes?
Kubernetes offers multiple key benefits that improve application deployment and management. Here are some key advantages of Kubernetes that distinguish it from other orchestration tools:
- Intelligent Auto Scaling: It implements both Horizontal Pod Autoscaling (HPA) based on resource metrics and Vertical Pod Autoscaling (VPA) for dynamic resource allocation. It scales pods automatically based on CPU utilization, custom metrics, or application-specific KPIs.
- Self-Healing: Leverages ReplicaSets and health probes (liveness, readiness, startup) to maintain the desired state. Implements automatic pod rescheduling and container restarts based on defined health checks and resource constraints.
- Load Balancing: This feature offers sophisticated load balancing through Services and Ingress controllers. It supports service discovery patterns and traffic routing strategies and integrates with service meshes to offer greater control.
- Infrastructure Agnostic: Provides consistent container orchestration across CNCF-compliant infrastructure through standardized CRI (Container Runtime Interface) and CNI (Container Network Interface) implementations.
- High Availability: Ensures fault tolerance through pod distribution strategies, anti-affinity rules, and multi-zone deployment capabilities. Uses etcd for distributed state management and leader election.
Why deploy PostgreSQL Database on Kubernetes?
While PostgreSQL has traditionally thrived in VM and bare-metal environments due to their predictable I/O performance and resource isolation, Kubernetes offers compelling advantages for modern database deployments. With the StatefulSets, persistent volumes, and storage classes, K8s now provides robust primitives for managing stateful workloads.
Benefits of Running PostgreSQL on Kubernetes
Using Kubernetes to run PostgreSQL allows teams to leverage cloud-native infrastructures’ capabilities fully. These include scalability, high availability, and resource efficiency, all while reducing operational costs and enhancing resilience.
Scalability
- Dynamic Scaling: Kubernetes allows for real-time adjustments to the number of PostgreSQL instances based on workload demands, enabling efficient resource allocation.
- Resource Optimization: Efficient resource management in Kubernetes leads to better infrastructure utilization, allowing PostgreSQL to scale horizontally and vertically as needed.
High Availability
- Automated Failover: Using operators like Patroni, Kubernetes can automatically switch roles between primary and replica nodes in case of failures, ensuring minimal downtime.
- Multi-AZ Deployment: Kubernetes supports deploying PostgreSQL across multiple availability zones (AZs), improving protection against regional outages.
Automated Management
- Operators for Automation: Tools like Patroni automate routine tasks such as deployment and backups, significantly reducing manual intervention and operational complexity.
- Declarative Configuration: Operators facilitate declarative management of PostgreSQL clusters, simplifying configuration changes and enabling Infrastructure as Code practices.
Disaster Recovery
- Robust Backup Strategies: Kubernetes supports automated backups and point-in-time recovery options, minimizing data loss and ensuring quick service restoration in case of failures.
- Continuous Restoration: Solutions like pgBackrest enable continuous synchronization between clusters, allowing for rapid failover to a disaster recovery site.
- Monitoring and Autoscaling: Integrating tools like Prometheus allows for effective tracking of database performance metrics, which can trigger the automatic scaling of resources based on demand.
How to Set Up PostgreSQL on Kubernetes
Deploying PostgreSQL on Kubernetes involves creating several resources, such as StatefulSets, PersistentVolumes, and services. Let’s look at the various prerequisites that you should have to set up PostgreSQL on Kubernetes.
Prerequisites
- A running Kubernetes cluster – can be a local or cloud-managed cluster.
- kubectl CLI configured with cluster access
- Persistent storage provider configured (e.g., Portworx or another CSI driver)
- Helm
With these prerequisites, you are ready to deploy PostgreSQL on Kubernetes.
Choosing the Right Kubernetes Distribution
PostgreSQL can run on any CNCF-certified Kubernetes distribution, but its deployment depends on our infrastructure and business requirements. Operators can help you configure and deploy it, and one recommended operator is the CloudNativeDB Operator. Designed specifically for PostgreSQL workloads, it supports major distributions, including EKS, GKE, AKS, and self-managed Kubernetes clusters.
Running Postgres on Kubernetes with Portworx
Kubernetes is a great place to run many workloads requiring automation and scale. Due to the particular requirements of stateful services–security, reliability, performance– they benefit in particular from this automation, enabling teams to move faster to market without sacrificing reliability. Because they house data, stateful workloads like Postgres running on Kubernetes must be able to meet particular business requirements outlined below to meet compliance, security, availability, and performance demands of mission-critical applications.
Proper Worker Configuration
When configuring PostgreSQL on Kubernetes, you must ensure proper worker configuration for optimal performance. Provision nodes with adequate CPU, memory, and I/O capabilities to handle PostgreSQL’s workload. Configure node taints and tolerations to ensure PostgreSQL pods are scheduled on appropriately sized nodes. You should also use pod affinity rules to distribute its instances across different fault domains.
Reliable Container Storage and Data Management
PostgreSQL’s performance on Kubernetes relies heavily on the underlying storage infrastructure. Portworx offers container-native storage solutions designed specifically for stateful workloads like PostgreSQL. With features like dynamic storage provisioning and database-optimized storage classes, Portworx offers a reliable storage solution.
Data Security
PostgreSQL comes with some security features out-of-the-box, like encryption, TLS, and basic access control. However, running PostgreSQL on Kubernetes requires additional security, especially in a multi-tenant setup. Portworx enhances this by providing volume-level encryption, granular RBAC for storage operations, and integration with key management systems for additional security.
Data Protection & Disaster Recovery
Running production PostgreSQL workloads requires a robust data protection and disaster recovery plan. Portworx ensures this by enabling cross-cluster data replication, scheduled and on-demand backups with support for Kubernetes native backup and restore operations. It also supports Zero RPO disaster recovery to ensure business continuity.
PostgreSQL Deployment Strategies on Kubernetes
Deploying PostgreSQL on Kubernetes opens up new avenues for managing databases at scale. Kubernetes’ orchestration and resource management capabilities can be leveraged to create resilient, scalable deployments. However, choosing the right deployment strategy for you is key to maximizing PostgreSQL’s potential in such a dynamic environment.
Single-node PostgreSQL Deployment
A single-node PostgreSQL setup is ideal for development or low-demand environments. It offers simplicity with minimal resource and configuration overhead. This approach is suitable for development, testing, or low-traffic applications. It involves creating a single pod that runs the PostgreSQL container along with a persistent volume to store data. This method allows for easy management and quick setup but lacks high availability and redundancy.
Multi-node PostgreSQL Clusters
Multi-node clusters are essential for production environments requiring high availability. Utilizing a leader-follower replication model, this setup distributes data across multiple instances, ensuring that secondary nodes have copies of the primary data. If the primary node fails, a failover mechanism promotes a follower to minimize downtime. This configuration provides resilience against node or pod failures, enabling uninterrupted service with automatic recovery.
Using StatefulSets for PostgreSQL
StatefulSets manage PostgreSQL pods by preserving their stable network identities and persistent storage, which is crucial for database applications. Each pod maintains a consistent identifier and data across rescheduling or restarts, ensuring continuity of service and data integrity. This setup is essential for PostgreSQL, where each instance must reliably retain its data and identity to function correctly in a clustered environment.
Configuring Persistent Storage
Persistent Volumes (PVs) and Persistent Volume Claims (PVCs) are foundational for PostgreSQL’s data persistence in Kubernetes. PVs provide long-term storage for PostgreSQL data, independent of the pod lifecycle, retaining data across pod rescheduling or failures. PVCs link these volumes to PostgreSQL pods, ensuring that each instance can access its storage consistently and maintaining data reliability and durability in dynamic environments.
Pod Affinity and Anti-Affinity Rules
Affinity and anti-affinity rules optimize performance and resilience by influencing where PostgreSQL pods are scheduled. Affinity rules place pods in close proximity, facilitating efficient data replication and low-latency communication within clusters. Anti-affinity rules, by contrast, distribute pods across different nodes, reducing the risk of a single point of failure. This balance ensures high availability and minimizes the impact of node failures while promoting efficient resource usage.
How to Configure PostgreSQL on Kubernetes
To deploy PostgreSQL on Kubernetes, you must carefully configure various Kubernetes resources to ensure proper operations. This section shares some configurations to help you optimize your PostgreSQL instance on Kubernetes.
PostgreSQL Configuration Options
We will use the CloudNativePG operator to deploy PostgreSQL on a Kubernetes cluster describing configurations for networking, security, performance, and replication.
We have a pre-configured storage class that will be utilized to create PVCs, which is required for PostgreSQL. Here is the manifest for the default storage class.
```yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: default
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: disk.csi.azure.com
allowVolumeExpansion: true
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer
parameters:
skuname: StandardSSD_ZRS
```
We can validate the default storage class using the following command. The output may differ based on the environment you use.
```sh kubectl get sc default NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE default (default) disk.csi.azure.com Delete WaitForFirstConsumer true 14m ```
Once the Kubernetes cluster has been configured, you can install the CloudNativePG operator using the following command.
```sh kubectl apply --server-side -f https://raw.githubusercontent.com/cloudnative-pg/cloudnative-pg/release-1.24/releases/cnpg-1.24.1.yaml ```
You can verify the installation by validating the deployment with the following command.
```sh kubectl get deployment -n cnpg-system cnpg-controller-manager``` NAME READY UP-TO-DATE AVAILABLE AGE cnpg-controller-manager 1/1 1 1 21s ```
The following cluster-example.yaml file defines a simple PostgreSQL cluster with the default storage class that allocates disk space.
```yaml
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cluster-example
spec:
storage:
size: 1Gi
```
The above configuration will create PostgreSQL without credentials. However, that is not the best practice for deploying it in production. Hence, the following section will explain how to configure the credentials.
Setting Up PostgreSQL Credentials
Configuring credentials and authentication is essential for secure access, and it can be customized using the ClouNativePG operator. In PostgreSQL, pg_hba (postgres host_based_authentication) controls the authentication. The rules can be defined under the pg_hba section in the cluster configuration.
To set up credentials, define a Kubernetes Secret for credentials and configure pg_hba.conf rules, and reference the secret in your cluster configuration.
Create a Secret for credentials to store the PostgreSQL username and password:
``` kubectl create secret generic postgres-auth \ --from-literal=username=myuser \ --from-literal=password=mypassword \ -n default ```
Configure the PostgreSQL Cluster and use the secret created above, and set pg_hba rules to require password authentication:
```yaml
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: postgresql-instance
namespace: default
spec:
storage:
size: 1Gi
instances: 1
replicationSlots:
highAvailability: true
bootstrap:
initdb:
database: "mydatabase" # Initial database name
owner: "myuser" # Database owner (matches secret's username)
secret:
name: postgres-auth # Reference to credentials secret
postgresql:
parameters:
shared_buffers: "2GB"
pg_hba:
- local all all scram-sha-256 # Password authentication for local connections
- host all all 0.0.0.0/0 scram-sha-256 # Password authentication for external connections
```
This setup secures PostgreSQL with password authentication, using credentials from the Kubernetes Secret for both local and external connections.
With this configuration, run the following command to deploy PostgreSQL.
`kubectl apply -f cluster-example.yaml`
You can verify the deployment of PostgreSQL with following command.
```sh kubectl get pods -n default NAME READY STATUS RESTARTS AGE postgresql-instance-1 1/1 Running 0 80s ```
Configuring PostgreSQL Heap Size and Replicas
Right-sizing PostgreSQL on Kubernetes is crucial for optimal performance. Two parameters that help with this are heap size and replicas.
The heap size determines the memory allocated to each PostgreSQL instance for query operations, buffer caches, and working memory
Heap Size: This determines the memory allocated to each PostgreSQL instance for query operations, buffer caches, and working memory. The shared_buffers parameter is used to configure the heap_size in PostgreSQL. This parameter controls the amount of memory allocated to PostgreSQL’s buffer cache, which acts like the “heap” in PostgreSQL. For optimal performance, it is recommended to set the heap size to 30-50% of available memory of what’s left of the node after Kubernetes services.
Replicas: This represents the number of PostgreSQL instances running in your cluster. Using CloudNativePG in Kubernetes, it is possible to configure replication by setting up a PostgreSQL cluster with multiple instances. The operator will automatically set up one primary and multiple replicas based on the number you provide. In the following configuration, we have set the instances to 3. This creates one primary and two replicas. Further, when replicationSlots.highAvailability: is set as enabled:true prevents the replicas from falling behind.
```yaml
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: postgresql-instance
namespace: default
spec:
storage:
size: 1Gi
instances: 3 # One primary, two replicas
replicationSlots:
highAvailability:
enabled: true # Enables high availability for replication storage:
postgresql:
parameters:
shared_buffers: "2GB" # Set heap size to 2GB
```
Configuring Network Settings
Networking restrictions are critical to running workloads on the cloud. When it comes to running PostgreSQL on Kubernetes, you need to have network policies and rules in place that only allow the operator to communicate with the PostgreSQL pods on 8000 and 5432 ports and restrict all other traffic for enhanced security. If there are any other restrictive policies on the cluster, create a network policy to handle that. You can refer to the official CloudNativePG networking guide for more.
Configuring Shards
Sharding splits one table into multiple tables to improve performance and scalability. You can create shards manually.
Step 1: Create a main table
Access the PostgreSQL Instance
``kubectl exec -it postgresql-instance-1 -n default -- psql -U myuser -d mydatabase```
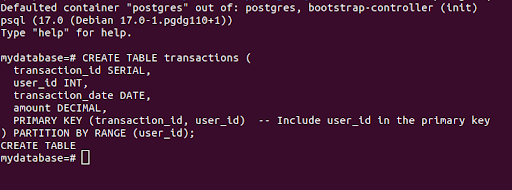
You will be logged into the mydatabase created based on the details we provided in the yaml to configure the PostgreSQL cluster. Once inside the database, create a main table using the following command, with the partition key (user_id) in the primary key:
``` CREATE TABLE transactions ( transaction_id SERIAL, user_id INT, transaction_date DATE, amount DECIMAL, PRIMARY KEY (transaction_id, user_id) -- Include user_id in the primary key ) PARTITION BY RANGE (user_id); ```
You should see CREATE TABLE output after successful creation of the table.
Step 2: Create Shards (Partitions) by Range
Create individual shards for different user_id ranges with following commands:
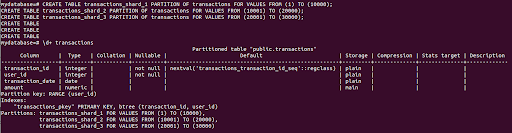
``` CREATE TABLE transactions_shard_1 PARTITION OF transactions FOR VALUES FROM (1) TO (10000); CREATE TABLE transactions_shard_2 PARTITION OF transactions FOR VALUES FROM (10001) TO (20000); CREATE TABLE transactions_shard_3 PARTITION OF transactions FOR VALUES FROM (20001) TO (30000); ```
To confirm the shards are created successfully, you can run the following command in database,
\d+ transactions. You should see the output the same as follows.
Monitoring PostgreSQL on Kubernetes
Comprehensive monitoring of PostgreSQL on Kubernetes is necessary for production setups to ensure performance and reliability. The typical standard monitoring stack of Prometheus for metrics collection and Grafana for visualization provides insights into both database and container-level metrics.
Some key monitoring components include:
- PostgreSQL exporter that exposes PostgreSQL metrics like connections, transaction rates, buffer stats, etc.
- Node exporter captures host-level metrics relevant to database performance, including CPU, memory, I/O operations, etc.
- kube-state-metrics monitors Kubernetes-specific metrics for PostgreSQL pods and associated resources.
You can also configure and track other metrics relevant to your setup and use case. Refer to CloudNativePG’s monitoring guide to set up monitoring using Prometheus and Grafana on your cluster.
Day 2 Operations for PostgreSQL on Kubernetes
Once the PostgreSQL deployment on Kubernetes is complete, continuous monitoring and maintenance are required, especially as the application scales. A well-planned strategy is necessary to address failures and improve the overall operation to ensure that the database is reliable, efficient, and resilient during Day 2 operations in a dynamic environment.
Let us look at ways to deal with these issues and highlight how Portworx’s capabilities can improve and streamline operations:
Handling Node Failures
Node failures are an unavoidable part of managing workloads on Kubernetes. With PostgreSQL on Kubernetes and the right strategies, you can minimize disruption. Portworx provides reliable storage options that facilitate automatic failover and high availability. The combination of Kubernetes capabilities and Portworx data resilience ensures that PostgreSQL clusters can withstand unexpected outages, allowing the application to run smoothly and efficiently.
Scaling PostgreSQL Cluster
As applications evolve, scaling the PostgreSQL database is critical to meeting the customer’s growing demands. However, scaling the database cluster in a Kubernetes environment can be difficult because handling more requests and larger databases requires a seamless user experience. This task is manageable using Portworx. By offering automated scaling and dynamic storage provisioning, Portworx makes it possible to scale the cluster without causing any challenges.
How to Secure PostgreSQL on Kubernetes
To secure PostgreSQL on Kubernetes, a multi-layered approach that combines network isolation, encryption, and access control is critical to safeguarding the database.
- Network Policies: Defines rules that specify which pods can communicate with PostgreSQL instances, limiting exposure to potential threats and ensuring that only trusted services access the database, hence controlling pod traffic
- Securing Communication with TLS: It encrypts data in transit between clients and the PostgreSQL server, protecting sensitive information from eavesdropping and ensuring confidentiality.
- Role-Based Access Control (RBAC): It allows for precise management of permissions within Kubernetes cluster, ensuring that only authorized users or service accounts can perform actions on the PostgreSQL database, thereby minimizing the risk of unauthorized access or changes.
These combined measures create a robust security framework for PostgreSQL deployments in Kubernetes environments.
Securing Data at Rest
Portworx significantly enhances data security for PostgreSQL by providing robust capabilities for securing data at rest. One of its key features is AES-256 encryption, which protects sensitive information stored in persistent volumes. This encryption ensures that even if unauthorized access occurs at the storage level, the data remains unreadable without the proper decryption keys. Users can create encrypted Persistent Volume Claims (PVCs) using either a cluster-wide secret or unique secrets per volume, allowing for flexible and robust data protection strategies. This comprehensive approach ensures that both data in transit and at rest are adequately secured, making PostgreSQL deployments on Kubernetes resilient against unauthorized access and data breaches.
PostgreSQL Backup and Restore Strategies
Implementing effective backup and restore strategies for PostgreSQL is essential for ensuring data integrity and availability. Utilizing Portworx capabilities can significantly enhance these processes. Here are some key methods to consider:
Snapshot and Restore
Portworx provides robust snapshot capabilities to back up PostgreSQL on Kubernetes. With Portworx, consistent, point-in-time snapshots, PostgreSQL volumes can be created without downtime. These snapshots capture the entire database state, including the write-ahead logs, allowing for quick and reliable restoration. This feature is particularly beneficial in production environments where minimizing downtime is critical, as it ensures that backups are both efficient and non-disruptive. Portworx’s snapshot capabilities ensure PostgreSQL data is always protected and recoverable, even in unexpected failures.
Using Volume Snapshots
Portworx supports Kubernetes-native volume snapshots, enabling efficient backups of PostgreSQL data. Using Kubernetes’ built-in snapshot functionality, backups can be created directly from the command line or through automated pipelines. This integration simplifies the backup process while ensuring that PostgreSQL data is protected alongside other application data. Portworx’s volume snapshots are designed to be consistent and atomic, ensuring that the backup reflects a stable state of the database at the time of the snapshot.
Automating Backups
Automating backups is vital for maintaining regular data protection without manual intervention. Portworx allows scheduled automated backups of PostgreSQL instances, enabling defining backup policies that specify frequency and retention. This automation minimizes the risk of human error and ensures that backups are consistently taken according to requirements.
Best Practices for Running PostgreSQL on Kubernetes
When deploying PostgreSQL on Kubernetes, following these best practices can enhance performance, reliability, and security. Here are some essential strategies to consider:
Regular Updates and Patching
Keeping PostgreSQL deployment updated with the latest patches and updates is crucial for maintaining security and performance. Regularly updating the PostgreSQL database and the underlying Kubernetes components helps mitigate vulnerabilities and keeps up with the latest features and improvements. Implementing a scheduled maintenance window for updates can minimize disruption to services.
Resource Quotas and Limits
Implementing resource quotas and limits is vital for managing resource allocation effectively within the Kubernetes cluster. Setting these limits on CPU and memory usage for PostgreSQL pods, can prevent any single instance from consuming excessive resources. This practice helps ensure that the PostgreSQL database operates efficiently while maintaining overall cluster stability.
Effective Use of Namespaces
Kubernetes namespaces effectively allow the organization of PostgreSQL deployment logically. Creating separate namespaces for different environments (e.g., development, testing, production) can isolate resources and easily manage access controls. This separation helps prevent conflicts between services and simplifies resource management. Additionally, using namespaces aids in applying specific policies and configurations tailored to each environment.
Keeping Configuration Consistent
Maintaining consistent configuration across PostgreSQL deployments is essential for reliability. Using ConfigMaps and Secrets to manage configuration data and sensitive information enables decoupling configuration from application code, making it easier to update settings without redeploying the database and keeping it secure from attacks. Employing Infrastructure as Code (IaC) tools can also help ensure that configurations are consistently applied across different environments.
Adhering to these best practices—regular updates, resource management, effective use of namespaces, and consistent configuration—can optimize PostgreSQL deployments on Kubernetes, ensuring robust performance, security, and maintainability in a cloud-native environment.
Get Started Running PostgreSQL on Kubernetes with Portworx
Running PostgreSQL on Kubernetes can unlock flexibility, reliability, and efficiency, but doing so requires the right Kubernetes storage and data management solution. Portworx is a leading container data management platform enabling automated storage operations, data backup and protection, and more at scale.To get started, try Portworx for free.











Kubernetes Tutorial: How to Create Cloud Snapshots of PostgreSQL Persistent Volume Claims on GKE

Kubernetes Tutorial: How to Create Local Snapshots of PostgreSQL Persistent Volume Claims on GKE

Kubernetes Tutorial: How to Expand PostgreSQL Persistent Volume with No Downtime on Google Kubernetes Engine (GKE)









