



PostgreSQL (Postgres) is a robust stateful, object-relational, open-source database known for its reliability, high performance, and extensibility. The database management system offers features including foreign key constraints, high availability, complex queries, SQL multi-version concurrency control (MVCC), and updatable views. These features make PostgreSQL suitable for providing resilient and highly available data services to Kubernetes (K8s) applications.
PostgreSQL Kubernetes operators include:
Let’s take a closer look at these PostgreSQL Kubernetes operators. We’ll review each operator’s features and installation to help you decide which one best meets your needs.
CloudNativePG is an open-source Kubernetes operator that manages the life cycle of the PostgreSQL cluster. This is specially designed for PostgreSQL databases. This operator combines high availability and fault tolerance with monitoring. Key features of this operator are:
Prerequisites
Once the Kubernetes cluster is up and running, proceed to install CloudNativePG. The operator can be installed on a Kubernetes cluster with Helm Chart or YAML files available on the operator’s GitHub repository. Let us install it directly using the operator YAML manifest:
Install via the GitHub repository
kubectl apply --server-side -f https://raw.githubusercontent.com/cloudnative-pg/cloudnative-pg/release-1.24/releases/cnpg-1.24.1.yaml
This installation configures a PostgreSQL operator for Kubernetes, setting up resources in the cnpg-system namespace to manage PostgreSQL clusters. Key Custom Resource Definitions (CRDs) include:
A service account (cnpg-manager), associated role, and role-binding grant permissions to operate on these resources. The cnpg-controller-manager deployment runs the operator’s control loop, while ConfigMaps and webhook configurations handle monitoring, validation, and enforcement of policies. The operator setup allows for automated lifecycle management of PostgreSQL clusters, ensuring efficient resource scaling and reliable backup mechanisms within Kubernetes.
Verify the CloudNativePG operator status
```kubectl get deployment -n cnpg-system cnpg-controller-manager NAME READY UP-TO-DATE AVAILABLE AGE cnpg-controller-manager 1/1 1 1 21s ```
Once the CloudNativePG operator is successfully installed, you can set up PostgreSQL on Kubernetes cluster with the operator as per your requirements.
Crunchy Postgres Operator for Kubernetes (PGO) automates deployment and simplifies management of Kubernetes-enabled PostgreSQL clusters. The operator also provides pod customization and PostgreSQL configuration features, delivering high availability, monitoring, and data recovery through the pgBackRest open-source utility.
Significant PGO features include:
There are three ways you can install Crunchy Postgres for Kubernetes
We will set up PGO using Helm.
Prerequisites
Install via Helm OCI registry
To install PGO directly from the OCI registry, run the command below.
```sh helm install pgo oci://registry.developers.crunchydata.com/crunchydata/pgo ```
It will deploy pgo in the default namespace as Kubernetes Deployment and is composed of a single container. This container will help manage custom resources like PostgresCluster, which we will apply later to the cluster. PGO uses a Custom Resource Definition (CRD) to extend Kubernetes’ functionality to handle those specifications. The main custom resource definition is postgresclusters.postgres-operator.crunchydata.com.
This CRD defines the PostgreSQL cluster that the operator will use to perform resource allocation, high availability, backup management, cluster configuration, DR, monitoring, and so on. The official documentation provides a detailed explanation of the architecture and functionality of PGO.
Verify the PGO status
``` kubectl get pods -l postgres-operator.crunchydata.com/control-plane=pgo NAME READY STATUS RESTARTS AGE pgo-5dd778ccfb-mnp2h 1/1 Running 0 4m55s ```
See Crunchy’s PostgreSQL Operator documentation for further guidance on setting up custom configurations, disaster recovery, user roles, and authentication.
Patroni powers Zalando’s Postgres Operator. The operator uses CRDs that can be included as YAML in your CI/CD pipelines, enabling infrastructure as code practices. The operator interacts with Kubernetes to handle Postgres cluster management, reducing the need for manual intervention to provision resources. Also, the operator enables you to manage multiple Postgres clusters in various namespaces.
Much of the operator’s scope simplifies deploying Patroni-powered clusters on Kubernetes—rolling updates, provisioning, and cleaning up Postgres clusters—while Patroni handles high-availability cluster bootstrapping operations.
There are multiple ways to deploy the Zalando Postgres operator: manual deployment, Customization, and Helm Chart. In the setup below, we will be using the Helm Chart. Please refer to the official documentation for alternative deployment options.
Prerequisites
Install via Helm chart
Run the below command to install Postgres Operator and Postgres Operator UI.
``` helm repo add postgres-operator-charts https://opensource.zalando.com/postgres-operator/charts/postgres-operator helm install postgres-operator postgres-operator-charts/postgres-operator helm repo add postgres-operator-ui-charts https://opensource.zalando.com/postgres-operator/charts/postgres-operator-ui helm install postgres-operator-ui postgres-operator-ui-charts/postgres-operator-ui ```
Once the status of Postgres Operator and UI is running, port-forward the UI at 8081 port on local.
Port-forwarding Postgres Operator UI
Run the below command in a new terminal to port forward the ui service on 8081.
```kubectl port-forward svc/postgres-operator-ui 8081:80 ```
Navigate to localhost:8081 in the browser.
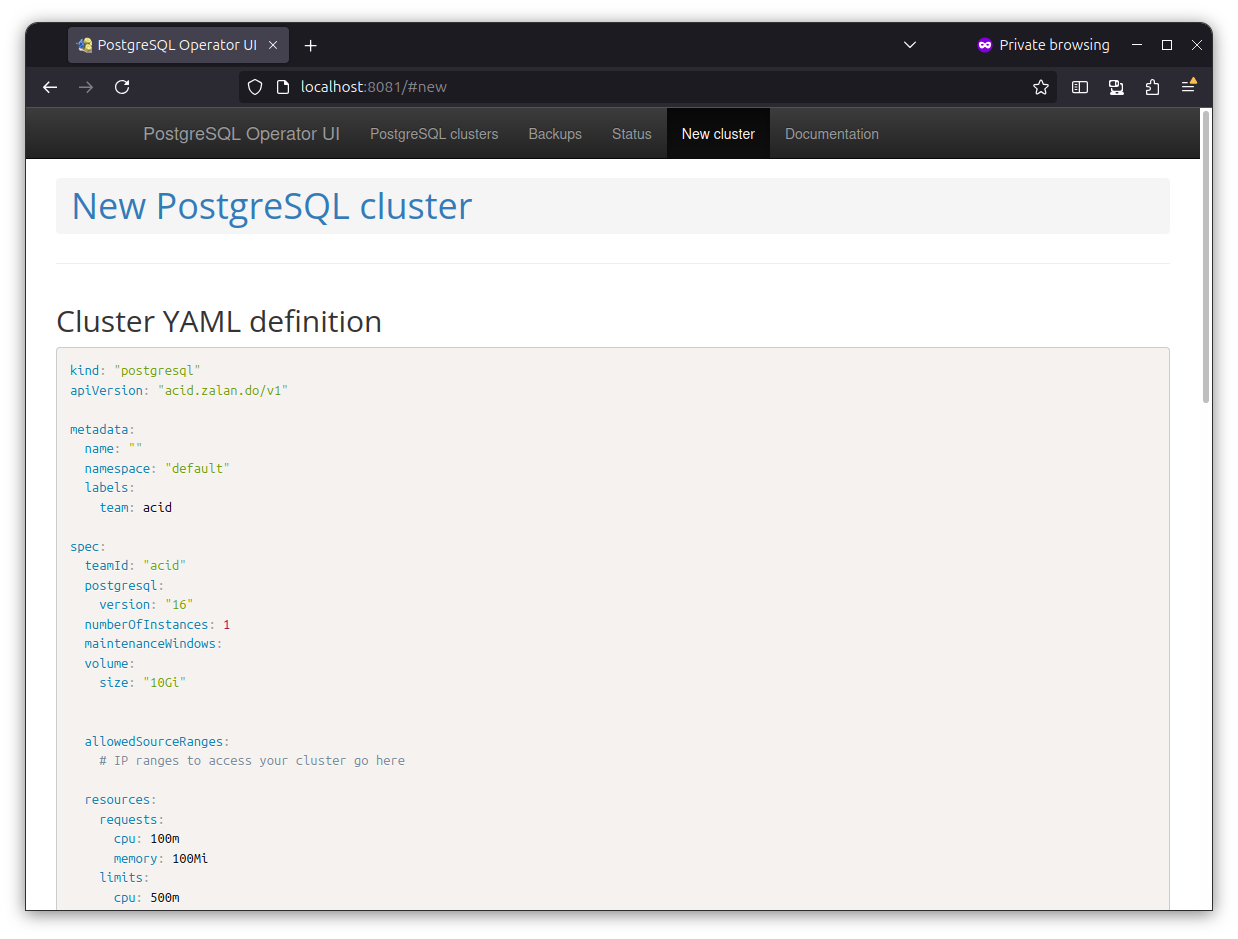
You should be redirected to the new PostgreSQL cluster creation window.
Please refer to Zalando’s documentation for more detailed information on creating a Postgres Cluster and its configurations.
AppsCode developed KubeDB, which enables you to create operators for various databases. KubeDB automates routine PostgreSQL operations in Kubernetes, such as cluster provisioning, backup, recovery, patching, failure discovery, and repair. Additionally, the KubeDB operator reduces complexity by allowing you to manage one stack for all your stateful and stateless applications.
Other core KubeDB features include:
Prerequisites
Since the KubeDB operator monitors Postgres objects in a Kubernetes environment, the KubeDB operator spins up new Deployments/StatefulSets plus cluster IP services after creating the Postgres object.
To install the KubeDB operator you need a license, which you can get after you fill out this form. Once you get the license based on your cluster-ID, provide its path while installing with Helm chart using the following commands.
Install via Helm chart
The following command can be run on the cluster to install the KubeDB.
``` helm install kubedb oci://ghcr.io/appscode-charts/kubedb \ --version v2024.9.30 \ --namespace kubedb --create-namespace \ --set-file global.license=/path/to/the/license.txt \ --wait --burst-limit=10000 --debug ```
With the above command, KubeDB operator is installed into the kubedb namespace. Once installed, KubeDB provides custom resources and controllers that enable deploying and managing PostgreSQL databases on Kubernetes.
If the KubeDB installation fails, one of the possible reasons could be resource limitations. Hence, make sure you have enough worker nodes and disk space for installing KubeDB on the cluster.
Verify the KubeDB operator status
It will take a few minutes to install the KubeDB operator, once the installation is complete, you can Get the KubeDB operator pods by running the following command:
```kubectl --namespace kubedb get pods NAME READY STATUS RESTARTS AGE kubedb-kubedb-autoscaler-7f5f84cf96-hvsnz 1/1 Running 0 17m kubedb-kubedb-ops-manager-6dc65c7d5c-t5c7x 1/1 Running 0 17m kubedb-kubedb-provisioner-584cd7b588-pd5r8 1/1 Running 0 17m kubedb-kubedb-webhook-server-6cf66b748-w4pxg 1/1 Running 0 17m kubedb-petset-operator-6b5fddcd9-bq2p9 1/1 Running 0 17m kubedb-petset-webhook-server-68cf76f9fc-d72bw 2/2 Running 0 17m kubedb-sidekick-f8674fc4f-cvdz7 1/1 Running 0 17m ```
To run a PostgreSQL database with KubeDB follow the official documentation here.
The StackGres Operator offers robust frameworks for resource setup, cloud-native storage compatibility, and dynamic configuration validation that are consistent with modern Kubernetes standards. This ensures optimal compatibility with various storage types while adhering to best practices for individual and enterprise deployments.
StackGres uses Envoy as a sidecar proxy to improve observability and optimize performance.
Along with this, integrations with Prometheus make it possible to monitor in real time, track errors, and make the best use of resources to solve observability problems in distributed setups.
The StackGres Operator not only manages core Kubernetes tasks, but it also includes advanced monitoring and self-healing features. By using adaptive tuning and real-time metrics collection, it enhances resilience, availability, and fault tolerance, enabling teams to sustain high uptime and responsiveness in intricate Kubernetes environments.
StackGres provides a wide range of features, which include but are not limited to:
Check out the StackGres documentation for a comprehensive understanding of its robust features and recommended configurations.
Installing the StackGres operator to manage and monitor PostgreSQL databases on Kubernetes requires the use of Helm or kubectl commands. The StackGres Operator is operational and prepared to manage PostgreSQL clusters by following the steps below:
Prerequisites
Install via Helm chart
Follow the steps to set up the StackGres PostgreSQL Operator:
```helm repo add StackGres-charts https://StackGres.io/downloads/StackGres-k8s/StackGres/helm/```
```helm install --create-namespace --namespace StackGres StackGres-operator StackGres-charts/StackGres-operator```
The command above deploys the StackGres Operator to a Kubernetes cluster in StackGres namespace. The operator deployment includes a set of Kubernetes Custom Resource Definitions (CRDs), allowing the cluster to recognize and manage custom resources designed for StackGres, such as PostgreSQL clusters and related services.
Once installed, this operator will monitor and manage StackGres-specific resources. It interprets custom resources, like SGCluster, which defines the structure and configuration of PostgreSQL clusters, to manage tasks like provisioning, scaling, and updating the clusters.
Custom resources, such as SGPostgresConfig and SGInstanceProfile, offer more customization options for PostgreSQL clusters.
Verify the Operator and Pod status
Verify if the Operator is Ready
```kubectl wait -n StackGres deployment -l group=StackGres.io --for=condition=Available``` deployment.apps/StackGres-operator condition met ```
Verify Pod Status
```kubectl get pods -n StackGres -l group=StackGres.io NAME READY STATUS RESTARTS AGE StackGres-operator-77d44b4cc8-xjc58 1/1 Running 1 (17m ago) 17m ```
To verify the status of all pods in the StackGres namespace, execute the following command:
```kubectl get pods -n StackGres NAME READY STATUS RESTARTS AGE StackGres-operator-77d44b4cc8-xjc58 1/1 Running 1 (24h ago) 24h StackGres-restapi-78fdd56df8-5b28x 2/2 Running 0 24h ```
This displays all pods in the namespace, not just those labeled as group=StackGres.io.
We recommend configuring storage classes based on the performance and storage requirements of your workload (see also dynamic provisioning and storage class setup for Portworx) after installing and running the StackGres Operator to ensure optimal compatibility and efficiency. With the storage setup complete, StackGres is now ready to empower your PostgreSQL clusters with deployment, creation, scaling, customization, and optimization. See the StackGres documentation for detailed instructions on how to set up, optimize, and deploy clusters so that you can get the most out of its advanced features.
The operators we’ve highlighted meet the base-level threshold for running high availability and fault-tolerant PostgreSQL clusters on Kubernetes. However, to ensure continuous availability even during pod rescheduling, dynamic, container-native storage solutions optimized for PostgreSQL are required.
For end-to-end data management, consider a solution that aligns with your availability, performance, security, compliance, and service-level agreement (SLA) requirements. Learn more about how the Portworx Data Services database-as-a-service platform helps deploy and automatically manage your Kubernetes data services.
This is a good opportunity to take the next step in optimizing your PostgreSQL clusters.
Ready to get started? Sign up for a free trial or learn more about PostgreSQL and Kubernetes with Portworx to improve your understanding and optimize your configuration.


