



Kubernetes, also known as K8s, is an open-source container orchestration platform that runs as a cluster of worker and master nodes, allowing teams to deploy, manage, and scale their stateless and stateful applications. Google initially used an orchestration platform internally for their mission-critical applications called Borg. A decade later, they released an open-source version of Borg and called it Kubernetes. The name “Kubernetes” originates from the Greek word for “Helmsman.” Kubernetes, now managed by the Cloud Native Computing Foundation, is one of the top open-source projects, with active development and contribution from large organizations like Google, Red Hat, VMware, Microsoft, and others.
Kubernetes automates the deployment and management for modern applications built using containers. Kubernetes allows developers to configure the desired state for their applications and runs a reconciliation loop to match the current state to the desired state for their applications. Using primitives like StatefulSets, Deployments, and ReplicaSets, Kubernetes performs scale up/out, rolling update operations for containerized applications.
Kubernetes provides a uniform orchestration platform that unlocks application mobility and portability. Developers can take their application code and run it against any conformant Kubernetes cluster on-premises (enterprise’s datacenter) or in any public cloud.
Even with the explanation above, it may be hard to understand what containers and Kubernetes are all about. For a better understanding of containers, we will begin with a little history on how application deployment methods evolved.
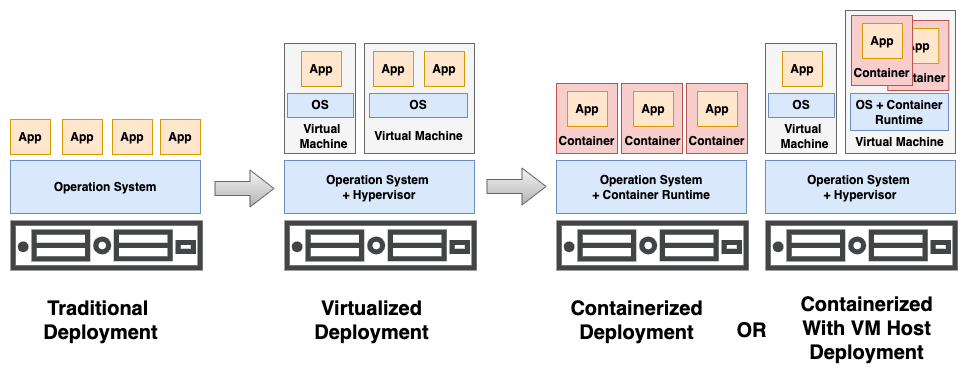
Traditional Deployment:Early on, when compute resources such as CPU and memory were not as powerful as today, applications were directly installed on the servers and operating systems. If multiple applications run on the same server, the binaries and libraries are often shared with each other. The resource sharing was difficult if one of the applications was a resource hog—using either high CPU, memory, network, or disk I/O—the other applications would suffer performance degradation. Often, the solution to this was to deploy a single application into a dedicated physical server, but this also leads to the problem of server resource underutilization.
Virtualized Deployment: The virtual machine (VM) was introduced as a solution. With the help of hypervisors—such as VMware, RedHat KVM, or Microsoft Hyper-V—we can run multiple VMs on a single physical server. Each VM is a full machine running independently, including its own operating system, on top of the virtualized hardware. This allows applications to be isolated between VMs and provides a level of security, as the information and data in a VM cannot be accessed by other VMs.
Virtualization also leads to much better server resource utilization as you can easily size or set the resource limit to the VMs. VMs can be easily scaled by cloning VMs and moving them around to other servers/hosts.
Containerized Deployment and Containers on VMs: Containers are similar to VMs, but they have relaxed isolation properties to share the Operating System (OS) among the applications. Therefore, containers are considered lightweight. Similar to a VM, a container has its own filesystem, share of CPU, memory, process space, and more. As they are decoupled from the underlying infrastructure, they are portable across clouds and OS distributions. In Kubernetes, the smallest deployable application unit is called a pod. A pod contains one or multiple containers. In this article, we use the terms “pod” and “container” interchangeably.
There are many benefits to using containers, but here are some of the main advantages:
Now that we understand containers are lightweight and agile, we can move ahead and see where containers are used today. To illustrate, we will look at a fictional tech company called “Orange Device, Inc.”
Orange Device, Inc. is releasing a new smartphone, and a massive number of customers are going to order a new phone online on the release day. This means the company’s online phone ordering system will need to process a huge spike of transactions during the first few days of phone release. Let’s see how containers and Kubernetes can help resolve this challenge.
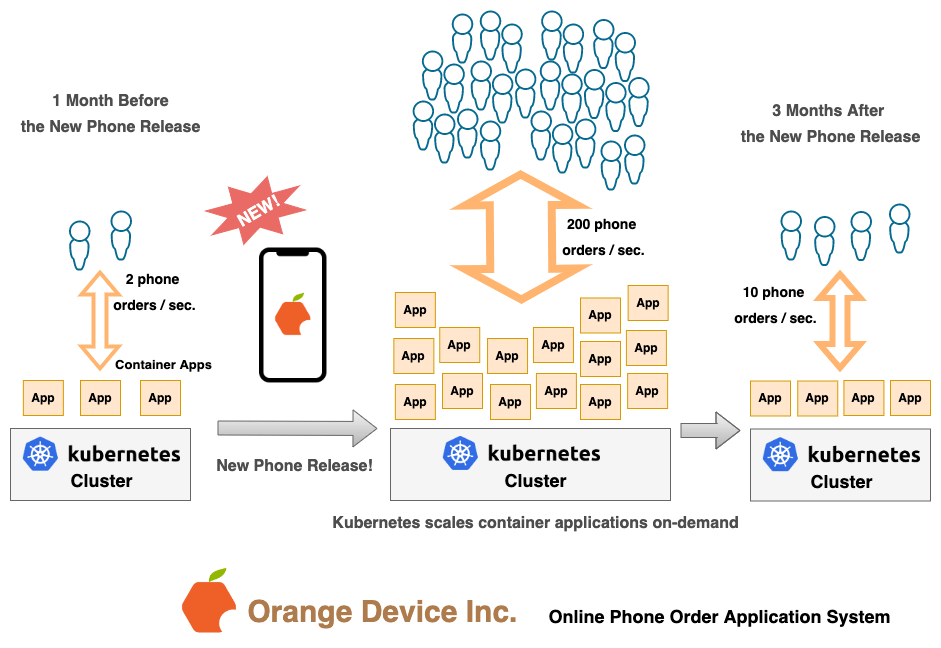
The diagram above shows how the “Online Phone Order” application system manages online transactions on-demand:
So, as a container orchestration platform, Kubernetes automates a lot of the manual processes involved in managing, deploying, and scaling containerized apps. The example shown above is just one popular use case of containers and the Kubernetes cluster.
A cluster resembles a group of nodes or servers that work together to distribute the workload. It also provides high availability in case of a node failure.
A Kubernetes cluster consists of at least one master node and one worker node. This configuration is usually for dev, testing, and learning purposes. A production cluster is made up of at least three master nodes and multiple worker nodes. More information regarding the number of nodes can be found here.
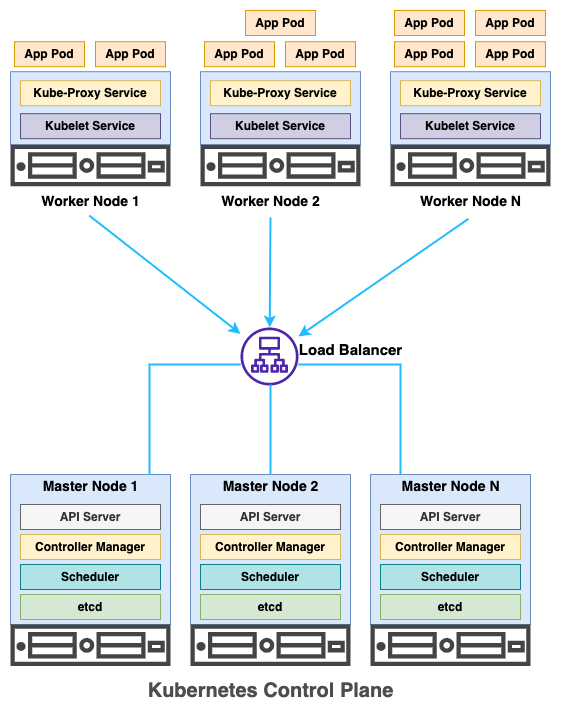
The master nodes are running several Kubernetes processes that control and manage a set of worker nodes. In Kubernetes, master nodes are also called control planes. The control plane has the following components to help manage worker nodes:
The worker nodes are actually running application pods (sometimes called workload) in the cluster. They have following two components:
Worker nodes are generally more powerful than master nodes because they have to run hundreds of application containers on them. However, master nodes are very important because they manage the distribution of workload and the state of the cluster.
At the high level, there are two types of applications or containers in Kubernetes.
Kubernetes is well known for managing stateless applications. Stateless means that when a new container is created, no data nor state is stored. Since no data is stored, stateless applications can be used as short-term workers. Kubernetes’ control plane can easily scale the number of stateless containers on-demand and scale them down with less demand.
Examples of stateless applications:
Stateful applications typically involve some kind of database with read and write operations. The data is stored as persistent volumes on a local server, shared storage, or remote storage. Stateful applications serve requests from stateless applications such as web servers to process and store web transactions.
Examples of stateful applications:
Kubernetes objects are persistent entities in the Kubernetes system. Kubernetes uses these entities to represent the state of your cluster. Specifically, they can describe:
A Kubernetes object is a “record of intent.” Once you create the object, the Kubernetes system will constantly work to ensure that object exists. By creating an object, you’re effectively telling the Kubernetes system what you want your cluster’s workload to look like; this is your cluster’s desired state.
YAML stands for “yet another markup language.” It is a text format used to specify data related to configuration. Any Kubernetes objects can be described as YAML files.
In short, Portworx is the container-native storage for stateful applications.
Kubernetes provides automation for application deployments by scheduling pods dynamically on worker nodes. This works very well for stateless applications. However, managing stateful applications is more complex because they have persistent volumes attached to them. In many cases, these persistent volumes come from the shared storage array—such as Pure Storage FA—and are attached to the nodes. Due to this persistent nature, dynamically moving stateful pods is difficult for Kubernetes.
So, what happens in case of a node failure that runs stateful pods? How do we migrate stateful pods in between nodes or even in between clusters? Since stateful pods often run database applications, we need to protect this data as well. How do we back up these persistent volumes so they can be easily restored? Portworx delivers the answers to these questions, helping users handle the complexities of storage management in the world of Kubernetes.
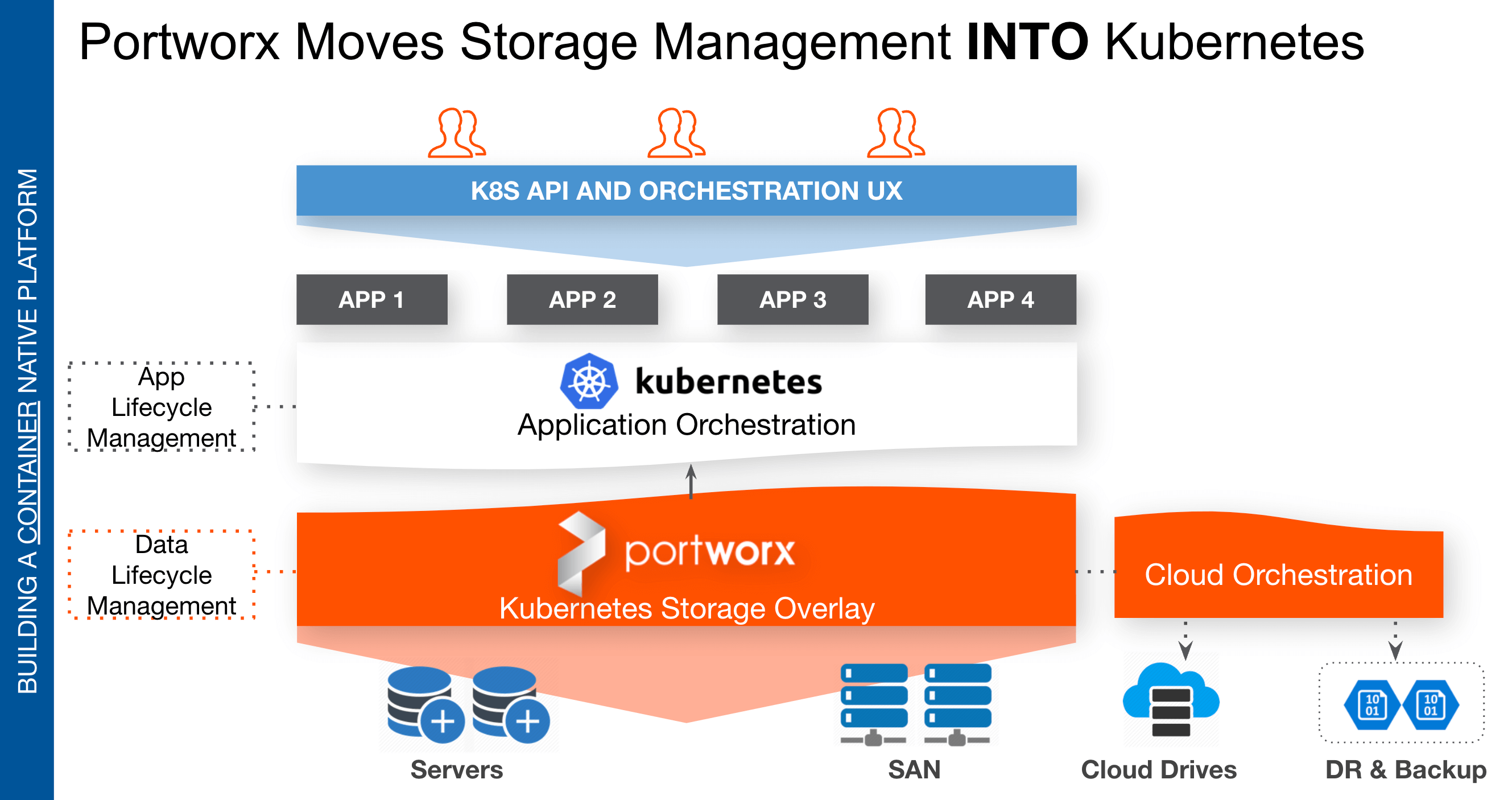
Portworx is a data management platform that serves application pods in Kubernetes clusters. Portworx is deployed natively within Kubernetes and extends the automation capabilities down into the infrastructure to eliminate all the complexities of managing data.
The diagram above shows how Portworx does this:
Portworx provides following advantages in cloud:
The Portworx portfolio helps platform engineering teams operate, scale, and secure containers and databases anywhere in production with a few clicks using Portworx Data Services, Portworx Enterprise, and Portworx Backup.
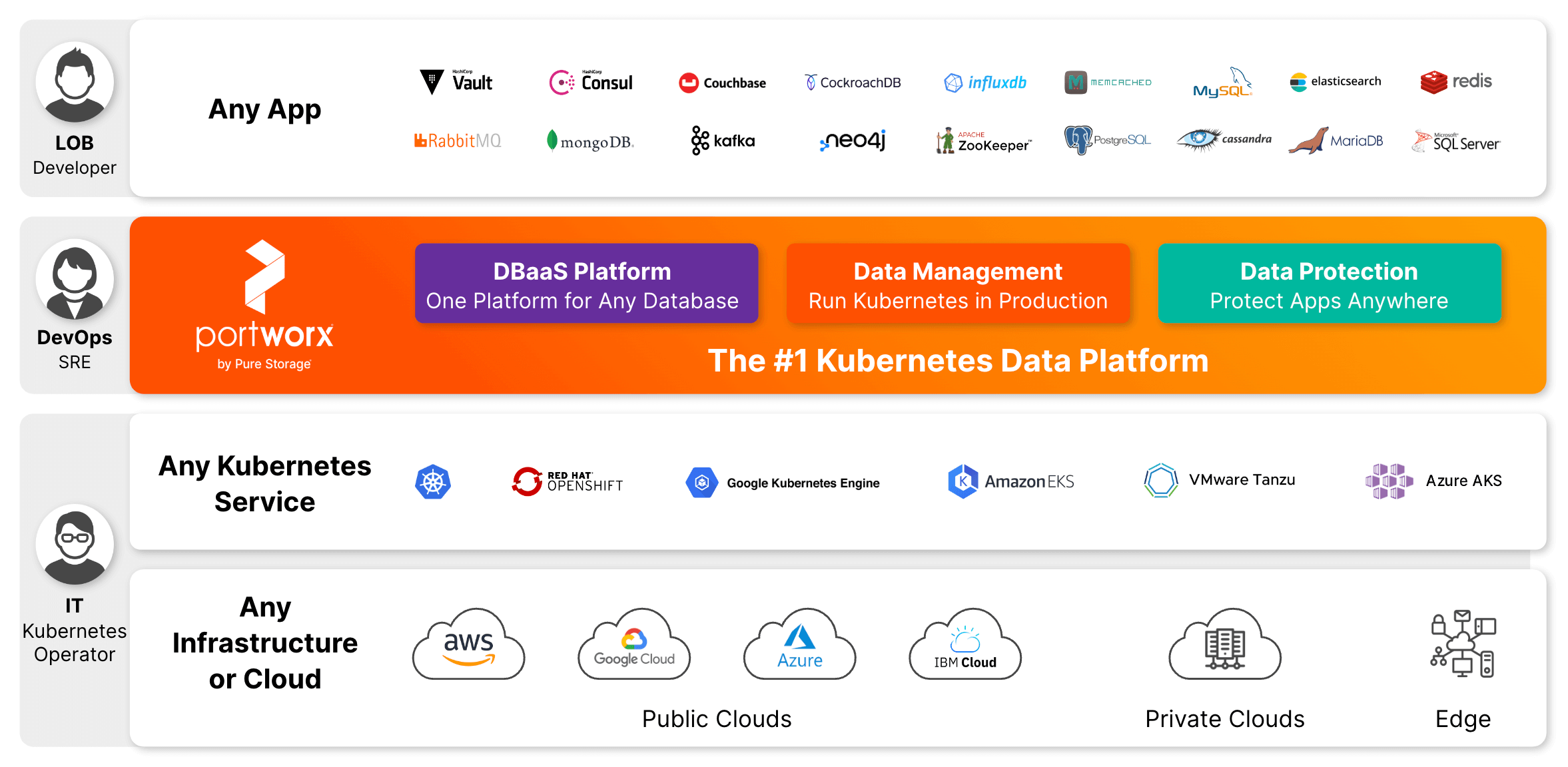
Portworx Data Services is a database-platform-as-a-service that enables enterprises to expedite deployment, day 2 operations, and protection for heterogeneous databases, without any lock-in or the need to hire specialists. Platform teams and Site Reliability Engineers (SREs) can now use ONE platform for any database to benefit from the single-click deployments—a consistent way to all databases and one vendor for enterprise grade support.
Portworx Enterprise is the Kubernetes Data Management platform trusted in production by the world’s leading enterprises because of capabilities such as persistent storage, disaster recovery, data security, cross-cloud and data migrations, and automated capacity management for containerized apps. Portworx Enterprise enables platform teams to run Kubernetes in Production with elastic scalability, unmatched availability, and self-service access to any storage, reducing time to market while maximizing app performance.
Portworx Backup is a leader in Kubernetes Data Protection, providing the easy button to secure containerized applications anywhere. Portworx Backup is an app-aware and container granular service built to simplify compliance and data protection, providing speedy restores in as little as a single click. Self-service management empowers application owners to back up and restore their apps anywhere in minutes while guaranteeing protection against ransomware with object lock and immutability.
In Kubernetes, namespaces provide a mechanism for isolating groups of resources within a single cluster. They are a way to divide cluster resources between multiple users. Namespaces provide a scope for names. Names of resources need to be unique within a namespace but not across namespaces. Namespaces cannot be nested inside one another, and each Kubernetes resource can only be in one namespace.
Kubernetes starts with four initial namespaces:
Administrators can create as many Kubernetes namespaces as necessary to isolate workloads or resources and limit access to specific users.
When you start Kubernetes clusters with a small team, managing access control to the resources and namespaces might be a lower priority. As the team grows, we need a system to limit the access to Kubernetes resources to increase security. If you are hosting a cluster for an application development team and developers need access to the cluster, then you definitely need to limit the access to the resources that are dedicated for them.
Role-based access control (RBAC) is a method of regulating access to computer or network resources based on the roles of individual users within your organization. RBAC in Kubernetes infrastructure is implemented through Role, ClusterRole, RoleBinding, and ClusterRoleBinding.
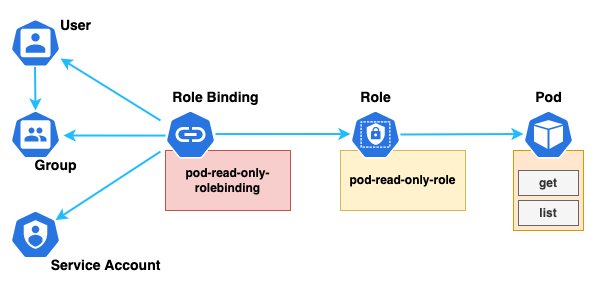
An RBAC Role or ClusterRole contains rules that represent a set of permissions. Permissions are purely additive (there are no “deny” rules). A Role always sets permissions within a particular namespace; when you create a Role, you have to specify the namespace it belongs in.
ClusterRole, by contrast, is a non-namespaced resource. The resources have different names (Role and ClusterRole) because a Kubernetes object always has to be either namespaced or not namespaced; it can’t be both.
ClusterRoles have several uses. You can use a ClusterRole to
If you want to define a role within a namespace, use a Role; if you want to define a role cluster-wide, use a ClusterRole.
Here is an example Role YAML file in the “dev” namespace that can be used to grant read access to pods. We gave this Role the name of “pod-read-only-role,” as also shown in the diagram above.
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: namespace: dev name: pod-read-only-role rules: - apiGroups: [""] # "" indicates the core API group resources: ["pods"] verbs: ["get", "list"]
A RoleBinding grants the permissions defined in a role to a user or set of users. It holds a list of subjects (users, groups, or service accounts) and a reference to the role being granted. A RoleBinding grants permissions within a specific namespace, whereas a ClusterRoleBinding grants that access cluster-wide.
A RoleBinding may reference any Role in the same namespace. Alternatively, a RoleBinding can reference a ClusterRole and bind that ClusterRole to the namespace of the RoleBinding. If you want to bind a ClusterRole to all the namespaces in your cluster, you use a ClusterRoleBinding.
Here is an example of a RoleBinding that grants the “pod-read-only-role” to the user “john” within the “dev” namespace. This allows “john” to read pods in the “dev” namespace.
apiVersion: rbac.authorization.k8s.io/v1 # This role binding allows "john" to read pods in the "dev" namespace. # You need to already have a Role named "pod-reader" in that namespace. kind: RoleBinding metadata: name: pod-read-only-rolebinding namespace: dev subjects: # You can specify more than one "subject" - kind: User name: john # "name" is case sensitive apiGroup: rbac.authorization.k8s.io roleRef: # "roleRef" specifies the binding to a Role / ClusterRole kind: Role #this must be Role or ClusterRole name: pod-read-only-role # this must match the name of the Role or ClusterRole you wish to bind to apiGroup: rbac.authorization.k8s.io
ClusterRole and ClusterRoleBindings provide permission to cluster-wide resources. They can be very powerful. You need to be careful with how you apply them because they apply not only to any existing namespaces but also to any future namespaces that you create.
For more information about Kubernetes, visit the link below.
https://kubernetes.io/docs/home/
For more information about Portworx products, visit the link below.


