


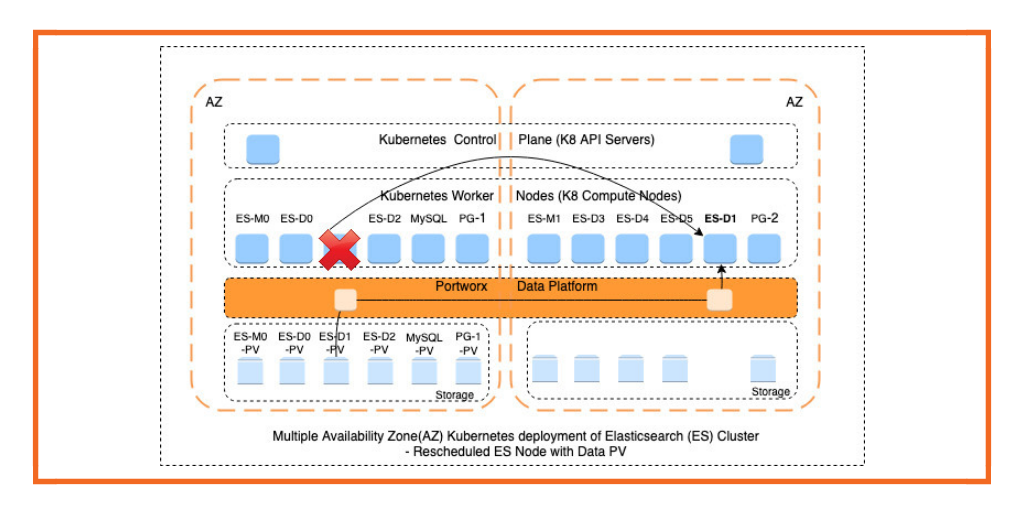
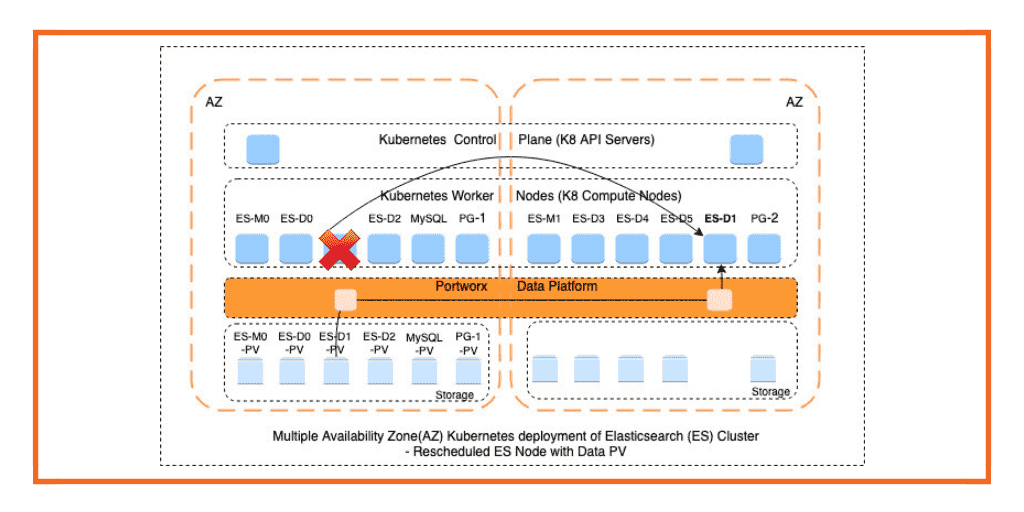
Elasticsearch is an open source search engine built on top of the Apache Lucene library. In a previous post, we discussed common use cases for Elasticsearch and how the Portworx Enterprise Data Platform helped with scaling of an Elasticsearch cluster. This blog post will focus on a particular use case where Elasticsearch cluster is being used to store location data from edge devices. We will demonstrate how you can span fault domains like Availability Zones using the Portworx Data Platform, and increase data durability in an Elasticsearch cluster.
We are producing data at an amazing rate, from connected cars to geolocation aware devices. In the near future, each 5G enabled device will be able to send the device location information to a central facility for analysis and processing. There are a lot of different use-case for near real time analysis. Here are a few to give you an idea of the flexibility:
In the use cases described above, we are making an assumption that sensory data is being collected at a central facility. The central facility has the necessary infrastructure so that the data can be indexed, analyzed and visualized for the end-user application. In the case of a search application, this relies on the resiliency of Elasticsearch in the event of server failures. Cluster operation of Elasticsearch can impact the data availability in the given cluster. Cluster operations has been improved in Elasticsearch v7.0+ using a new cluster coordination system called zen2, however, it remains important to make sure that Elasticsearch data itself is highly available.
The Portworx Data Platform can help with data durability concerns if you are running Elasticsearch on a Kubernetes cluster. With Elasticsearch version 7.0+ it is easier to scale an Elasticsearch cluster and when you pair the Elasticsearch data nodes with the Portworx Data Platform, scaling of underlying storage sub-system also becomes easier. In addition to complementing the application replication strategy, the Portworx Enterprise Data Platform can provide disaster recovery, data security, data mobility and more to Elasticsearch-backed applications running on Kubernetes.
To see the effect of server failures on Elasticsearch availability, we ran two tests, with and without Portworx, in which we loaded the Elasticsearch cluster with 400K documents spread across two Elasticsearch data nodes. In the first test, the Elasticsearch data pods have persistent volumes provided by a storage system which cannot span fault domains, such as Availability Zones within AWS. When one of the data nodes fails and is rescheduled across the fault domain, you can see that the Elasticsearch master node runs with diminished data index until the failed data node (elasticsearch-data-0) is recovered using manual intervention. This impacts the performance of the application relying on Elasticsearch.
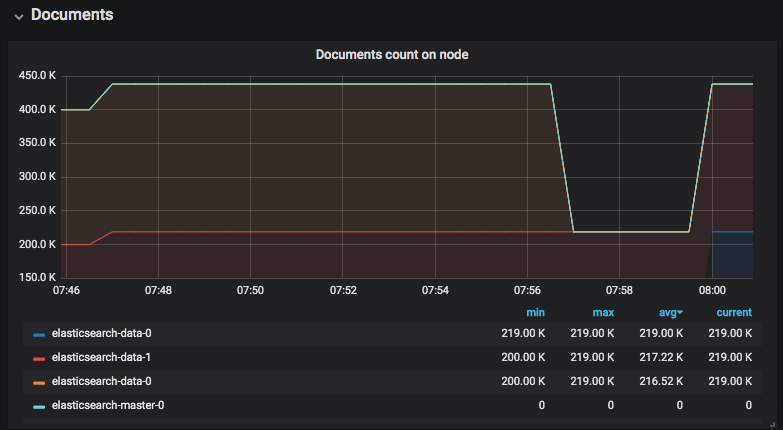
Elasticsearch Data Node failure and recovery using a cloud provided storage class
In our second test scenario, Portworx Data Platform is used to provision the persistent volumes for the Elasticsearch data nodes. In the event that theElasticsearch data node fails and is rescheduled across fault domains, the Elasticsearch data is able to come back online without any decrease in master node document count (elasticsearch-master-1 teal line). As depicted in the graph below, the Elasticsearch-data-0 is being rescheduled at 09:46:30 and another instance of the node comes back online at 09:47:00 with its persistent volume. Most of the recovery time was spent pulling the Elasticsearch container image from the registry instead of rebuilding the data node’s documents.
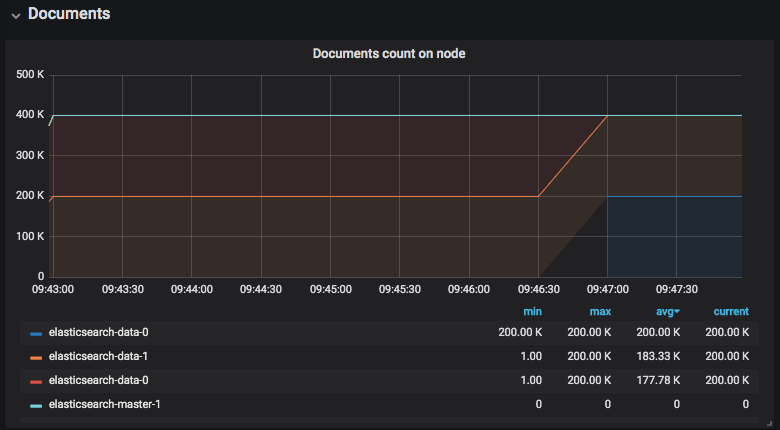
Elasticsearch Data Node failure and recovery using Portworx Data Platform
Elasticsearch can be used in multiple use cases to ingest and index vast amounts of data. The application is capable of replicating data across its data nodes using an application level replication factor. Portworx Data Platform offers replication of data at storage level which can span fault domains. In container orchestrators, like Kubernetes, pods can be rescheduled for many reasons. Due to the dynamic scheduling nature of Kubernetes, an approach we are suggesting is to let application focus on application functionality and offload data replication concerns to the Portworx Data Platform.
If you would like to learn more about the Portwox Data Platform and how to configure Elasticsearch cluster in Kubernetes, please request a demo and talk to one of our Elasticsearch experts. You can also join our Slack channel to discuss how Portworx Enterprise can help you run stateful workloads in production.



