




Apache Kafka has become a critical component of modern data architectures. As teams have shifted toward event-driven or microservices architectures, Kafka has become a popular choice for handling large volumes of data, often in real time. With the ability to scale horizontally, process data in real time, and integrate with a wide variety of technologies, Kafka has become a key tool in many organization’s toolboxes. While Kafka is a critical and simple-to-use tool simple to use, it also comes with its own complexity to manage. This blog post talks through how to manage these complexities by running Kafka on Kubernetes with Portworx Data Services.
Portworx Data Services (PDS) is a data services platform that can manage not just Kafka, but a number of other data services, including relational databases like MySQL and PostgreSQL, NoSQL databases like Cassandra and Redis, and, of course, messaging systems like Kafka. PDS provides a centralized management plane for your data services deployed across clouds or on-premises environments, giving users control over their data. PDS can manage data services for any conformant Kubernetes cluster, regardless of its location. Let’s see how Portworx Data Services can help us with the management of our Kafka clusters.
If you’re trying to deploy Kafka by hand, you’ll quickly find out that getting it up and running isn’t a straightforward task. First, our Kafka clusters need more than one node deployed to handle failures, which complicates our installation a little bit. Second, Kafka also needs a distributed solution to store our persistent data, which is usually Apache Zookeeper or Apache KRaft. We’re already starting to see some of the complexity with managing Kafka, and we’re still only in the deployment phase. This is one of the many reasons why you might want to leverage Portworx Data Services to manage your Kafka clusters.
The Portworx Data Services portal provides users an app-store-like experience for users to choose data services to build their applications upon. These data services can be deployed and configured from the Portworx Data Services UI or through the PDS application programming interface (API), which gives customers the flexibility to deploy these solutions in the way that works best for them.
From the PDS user interface, we can choose Kafka from our full list of data services and select our configurations from templates, making deployments simple and easy. PDS provides customization options for each data service, so you can customize the way your databases are deployed. An example of the Kafka data service options can be found in our documentation.
These configuration settings allow Kafka administrators to define standards for the Kafka clusters deployed in the environments they manage while allowing end users the ability to request new Kafka clusters without waiting for service tickets to be fulfilled.
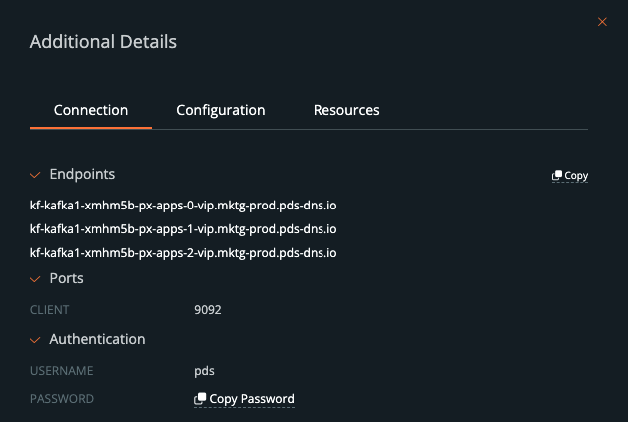
Once the Kafka service has been deployed, users can retrieve the connection details about the Kafka service so they can use them within their applications. This includes endpoints, ports, usernames, and passwords needed to connect to your Kafka brokers.
If you’re deploying Kafka, you’re also likely deploying additional data services. Kafka is often deployed as a buffer for other databases to smooth out the writes being pushed to the database. Kafka’s data ingestion capabilities make it a good choice for this, but it’s also used as a message bus for many consumers to pull data relevant to them. In either of these situations, you’ll likely be pushing the Kafka data to another database. In the example below, you can see how Kafka might act as both a data buffer and a message bus for multiple consumers to read from.
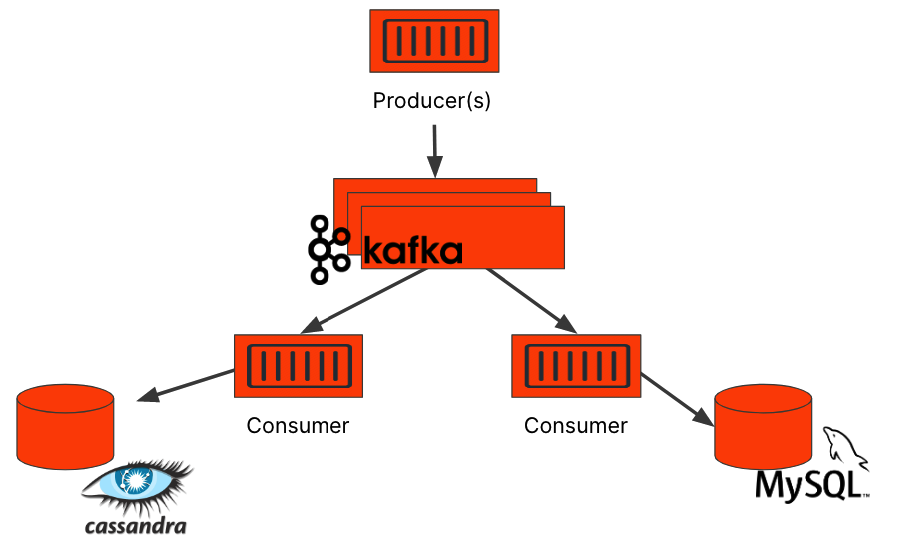
Portworx Data Services can deploy all of these databases for you from a single portal, making managing a distributed application simpler.
As any platform engineer will tell you, deployments are really only the first part of being able to manage your data services. Once they’ve been deployed, they require maintenance to keep them secure, performant, and reliable. These actions we take on our Kafka clusters after deployment are commonly referred to as “day 2 operations.” Let’s take a look at how PDS can help us manage our clusters after they’ve been deployed to our Kubernetes clusters.
We take pretty good guesses at how many resources our applications will need when we’re designing them. We want to size our solutions so we don’t waste resources such as CPU and memory on our infrastructure or consume cloud resources that charge us by the hour. When we actually start deploying our data services, we start to get a better understanding of how popular our application is and what kind of changes we need to make to ensure it performs under production load. Usually, over time, our design assumptions have to be modified, and we make these changes based on data.
Portworx Data Services provides these metrics by default when you start deploying your data services. PDS deploys its own version of Prometheus that will export performance data to the PDS control plane, allowing users to see how their data services are performing under real-world conditions.
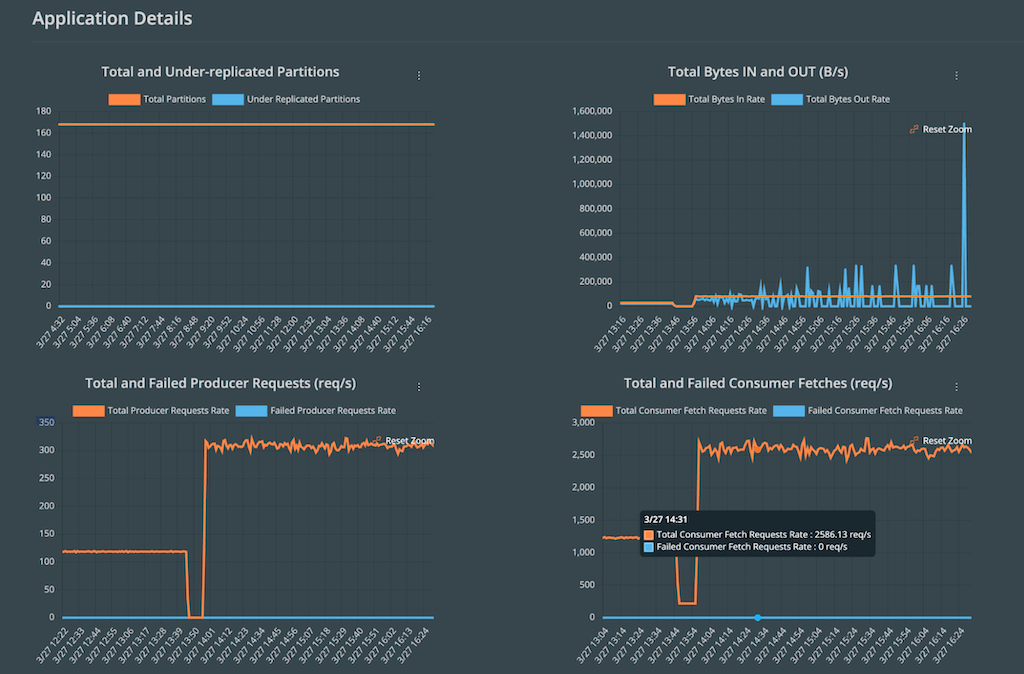
Thanks to the performance metrics found in PDS, we may have identified that our applications are wildly popular, and that means we need to increase their capacity so they can handle all the transactions they’re receiving. To resize our Kafka cluster in PDS, we can simply select our Kafka deployment and then change either the size of our Kafka brokers (scale up), or we can add additional Kafka brokers to our cluster (scale out). PDS will update the Kafka cluster to meet your desired state.
Data services are just like any other application when it comes to patching and updates, except data services can’t usually be destroyed and re-created like ephemeral containers can. Kafka brokers store persistent data, so we have to look after them with care. When there are new patches or capabilities added to your Kafka brokers, PDS will display a notification that updates are available. PDS users can select their data services and choose to upgrade to the latest version. When PDS performs these upgrades, the Kafka brokers will be updated in a rolling fashion so that no more than one Kafka broker is taken down at one time, leaving the cluster in an operational state during the upgrades.
Portworx curates all of the images for the data services provided in PDS. As security updates or new versions become available, Portworx makes a new version of the data service available through the portal. Portworx takes care of all the security scanning and testing of these images, both before they are released and continuously after they have been made available for use by customers.
At some point, you may decide to retire your data service. Maybe you changed your architecture, or maybe the application is no longer necessary anymore. Portworx Data Services makes it really easy to delete your data services. Just select the “delete” option from the Kafka dropdown menu, and your data services can be removed from your Kubernetes cluster. This might be a very handy feature to have for organizations that frequently deploy Kafka for development environments or during continuous delivery.
Apache Kafka is a wildly popular messaging application for distributed applications, but it comes with its own set of operational challenges. Portworx Data Services provides a mechanism to help deploy and manage your Kafka brokers running on Kubernetes. From the SaaS-based PDS portal, users can deploy their Kafka brokers in templatized configurations, ready to be used on Kubernetes and backed by Portworx Enterprise storage capabilities. Portworx Data Services can eliminate the toil of managing upgrades, capacity, scaling, and monitoring of your Kafka data services along with any other database solutions you might be using.
For more information about how to use PDS or about running Kafka on Kubernetes, check out the whitepaper listed below.



