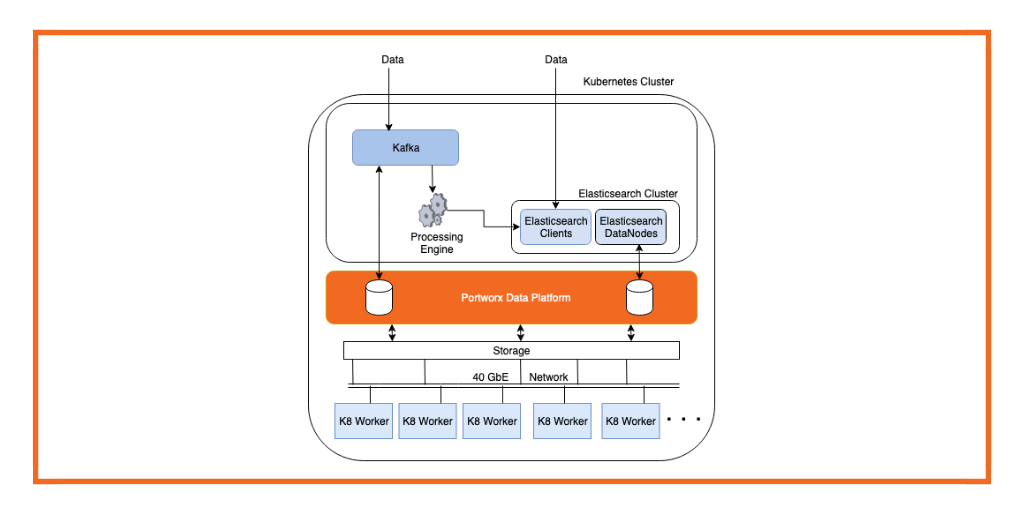
Elasticsearch is an open-source search engine that uses Lucene StandardAnalyzer to store, retrieve and analyze semi-structured data. In a previous post, we discussed use cases for near-real-time analytics using Elasticsearch. In this blog post, we will focus on setting up a high-performance Elasticsearch cluster on Kubernetes like the cluster used by one of Portworx’s large customers. We will discuss performance tuning needed at hardware, networking and application layers in order to achieve a high data density cluster with sustained high ingestion rates.
High-Performance Goals
Elasticsearch is a document-oriented schema-less system that can manage a huge amount of data. The Elasticsearch application stores Elasticsearch documents in close proximity to the corresponding metadata. This approach ensures the Elasticsearch cluster can return your search queries within milliseconds instead of seconds. Besides quick responses to search query data, here are a couple of goals for a typical high-performance Elasticsearch cluster:
- Ingestion rate. If you want to capture vast amounts of data in your cluster, you need to be able to ingest or pass documents into the cluster at a fast rate. There are many factors like increasing the shard count in the application and the type of client and document type which can influence the ingestion rate. The ingestion rate goal for a typical high-performance cluster like those used by large Portworx customers is a sustained ingestion rate of 1TB (TeraBytes) /hour.
- Scale. Volumes sizes of up to 6TB, distributed across the Kubernetes cluster in order to achieve 100TB capacity in the cluster. The challenge here is to achieve the stated sustained ingestion goal while keeping the number of worker nodes to be less than 50 data nodes.
Challenges of setting up a high-performance data pipeline
There are many challenges in achieving our goals of high-density data and the fast ingest rate of our Elasticsearch cluster. Let’s look at the performance considerations:
- Hardware. You want to make sure your storage platform and or storage media is able to achieve sustained Input-Output (IO) performance. The performance considerations apply to the physical media as well as storage control plane software.
- Networking. With 5G becoming more prevalent in the coming years, you are going to get data from
more edge devices. In order to gather and process data from smart edge devices, even before 5G is the norm, you need to have a network that is capable of sustained 10-40 Gbps throughput.
- Application – Data pipelines. In order to architect a high throughput data pipeline, you have to compose and configure your data aggregation and data processing pipeline with performance considerations in mind. Beyond picking the correct application to achieve the desired outcome, you also need to pay attention to data caching, replication and management & configuration strategies within your data pipeline.
An approach to achieving a high-performance Elasticsearch cluster
In order to achieve the desired outcome for our data pipeline, we need to analyze the entire technology stack. First, we need to optimize the infrastructure and make sure it’s capable of driving up to the high level of ingesting rates at scale.
Infrastructure
For optimal utilization of the underlying infrastructure, the Portworx cluster setup uses the following layout:
- Dedicated storage nodes that run the Portworx Enterprise storage platform software exclusively.
- Shared compute nodes that run the Portworx Enterprise storage platform software as well as Elasticsearch data node.
Applications
We need a high-performance message queue application to queue incoming data. In this case, we plan to use Kafka to collect incoming messages into various topics. A lightweight processor application reads and preprocesses this data and makes it available for consumption for Elasticsearch. This processed Kafka data is then used by the Elasticsearch cluster to ingest into various indexes and later can be processed and analyzed.
Data processing pipeline considerations
- Application data processing tooling. A very lightweight and fast data processing helper application will consume data from the Kafka cluster and prepare it for Elasticsearch consumption.
- Application and storage replication factor. We will set the application replication factor of Kafka and Elasticsearch at replication factor two. We will also set the Portworx Volume replication factor to two. Since the Portworx Enterprise storage platform understands fault domains, the platform will ensure volume replication is spread across fault domains while efficiently managing the number of write operations from application and storage perspective. Having 2x replication at both the application level and Portworx provides a high level of resiliency and availability. If we had picked 3x replication factor at application and storage level, it would have led to write amplification of 9 writes. Having 2x replication at the application level and at Portworx storage level will keep the write amplification factor in check.
- Data placement. The Portworx data platform makes sure that volumes and any replicas are distributed equally across all available storage nodes. Using an efficient distribution strategy, all storage pools are utilized equally. This ensures no load hotspots will occur in the storage cluster.
- Disaggregation. Given the IO access pattern of Kafka and Elasticsearch volumes, the respective application data nodes are isolated from each other to reduce any IO interference.
Portworx Data Platform configuration considerations
- Resource allocation. Portworx platform nodes need to be deployed in a high-performance configuration in order to support high-performance Elasticsearch and Kafka clusters. We need to remove any restrictions on CPU consumption for Portworx storage nodes and increase shared memory for storageless nodes to 2GB.
- Volume type. Kafka and Elasticsearch have very different IO characteristics. The Portworx platform has the ability to specify different io_profiles for different workloads. Since Kafka uses sequential writes, we will specify a sequential io_profile for Kafka volumes while Elasticsearch volumes will use a DB specific io_profile.
- Application-specific volume optimizations. Application internal details can be used to further optimize volume IOs. For example, the IO pattern on Kafka volumes is largely sequential read and sequential writes. Whereas on Elasticsearch volumes it’s pseudo sequential writes and sequential reads. Elasticsearch volumes also see heavy delete activity resulting from the frequent merging of smaller indexes into larger ones.
The outcome of a high-performance Elasticsearch Cluster
From the application perspective, over a 24 hour period, the high-performance Elasticsearch cluster was able to achieve an average index rate of 46.0K/sec with 57.0 Billion documents indexed.
For this 24 hour period, the image below shows the Portworx storage backend performance and utilization. It shows the sustained throughout levels with very low latency at scale. 40TB+ of data was managed and written by the Portworx storage system and the IO latencies did not exceed 3 seconds except for a couple of exceptions.
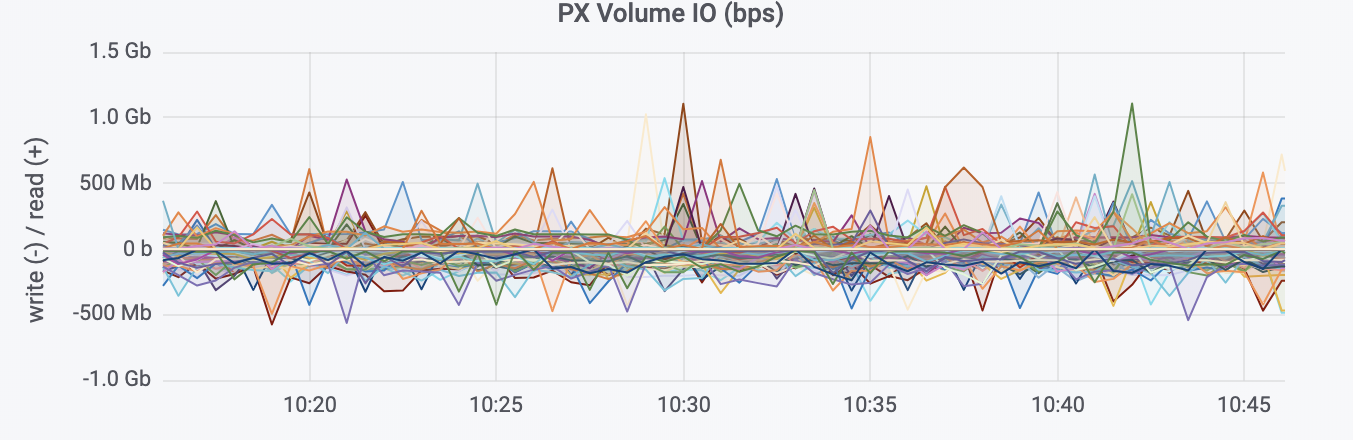
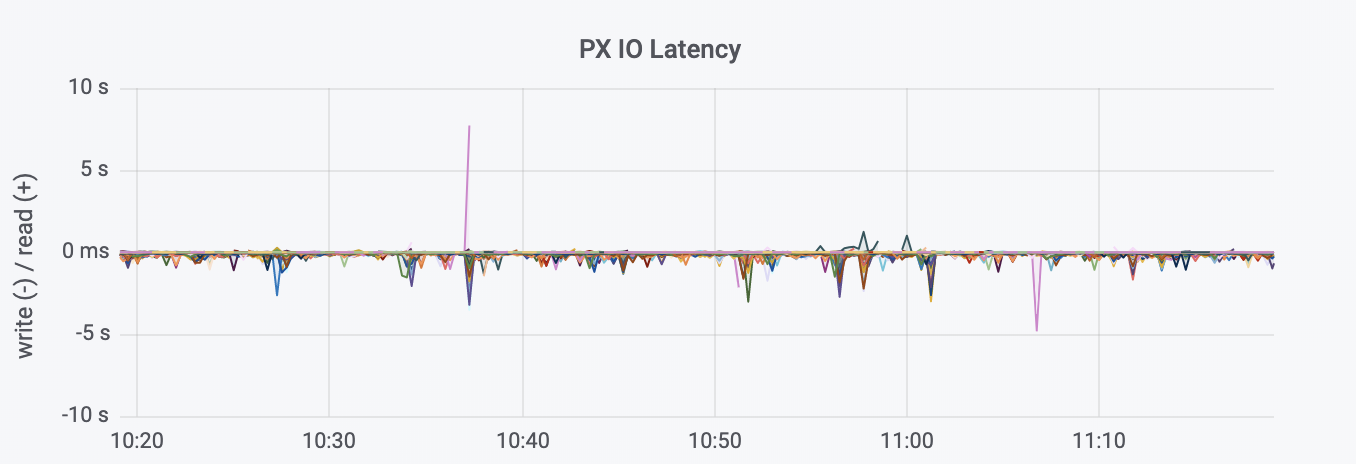
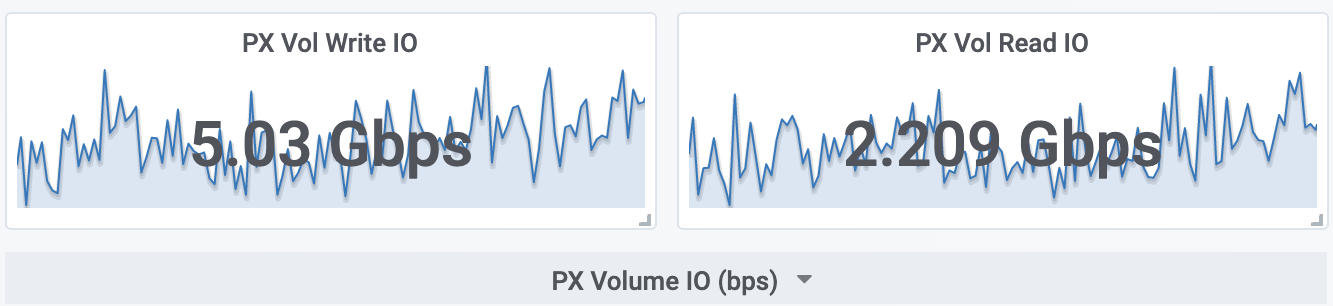
The image below demonstrates the ability of the Portworx Enterprise storage platform to achieve sustained read and write rates at scale in a 24 hour time window.

Conclusion
If you would like to learn more about the Portworx Enterprise Storage Platform and how to configure a high-performance Elasticsearch cluster on Kubernetes, please request a demo and talk to one of our Elasticsearch experts. You can also join our Slack channel to discuss how Portworx Enterprise can help you run stateful workloads in production.
Resources







