



As increasingly complex applications move to the Red Hat OpenShift platform, IT teams should have disaster recovery (DR) processes in place for business continuity in the face of widespread outages. These are not theoretical concerns. Many industries are subject to regulations that require data protection even in the event of massive failures. For instance, CFR 164.308(7)(ii)(B) of the HIPAA regulation stipulates that companies must be able to “restore ANY loss of data” (emphasis added) in the event of a failure. Thus for some truly mission critical applications to run on OpenShift, disaster recovery is essential.
This blog outlines how enterprises may achieve up to zero data loss disaster recovery, known as RPO zero, using Red Hat OpenShift and Portworx. Portworx is certified on the Red Hat Container Catalog and has a certified Operator on OperaterHub, providing a unified OpenShift experience for Red Hat customers. Before diving into how an enterprise may achieve RPO zero DR on OpenShift, let’s look at why we shouldn’t just use a traditional DR solution.

Traditional backup and restore solutions for applications are often implemented at the virtual machine (VM) level. This works great when a single application runs on a single VM. Backing up the VM and backing up the application are synonymous. Containerized applications like those that run on OpenShift, however, are much different.
A single VM often runs many pods, and not all of these pods are part of the same application. Likewise, a single application is often spread over many VMs. This distribution of application components over a cluster of servers is a basic architectural pattern of containerized applications. So it is easy to see why backing up a VM is no longer sufficient. VM backup is both too much and too little. Too much, because if I want to back up App 1, my VM backup might contain data for App 2 and App 3 as well. Too little, because even if I back up the entire server, parts of App 1 are running on different VMs that are not captured by my VM-based backups.
To be able to solve this problem, DR for OpenShift requires a solution that is:
The Portworx Enterprise Data Platform is designed to provide this with PX-DR. Let’s see how it works.
PX-DR is a container-granular approach to DR. That is, instead of backing up everything that runs on a VM or bare metal server, it gives users the ability to backup specific pods or groups of pods running on specific hosts.
In the below diagram, we see a three-node OpenShift cluster, with a three-node Cassandra ring and three individual PostgreSQL databases.
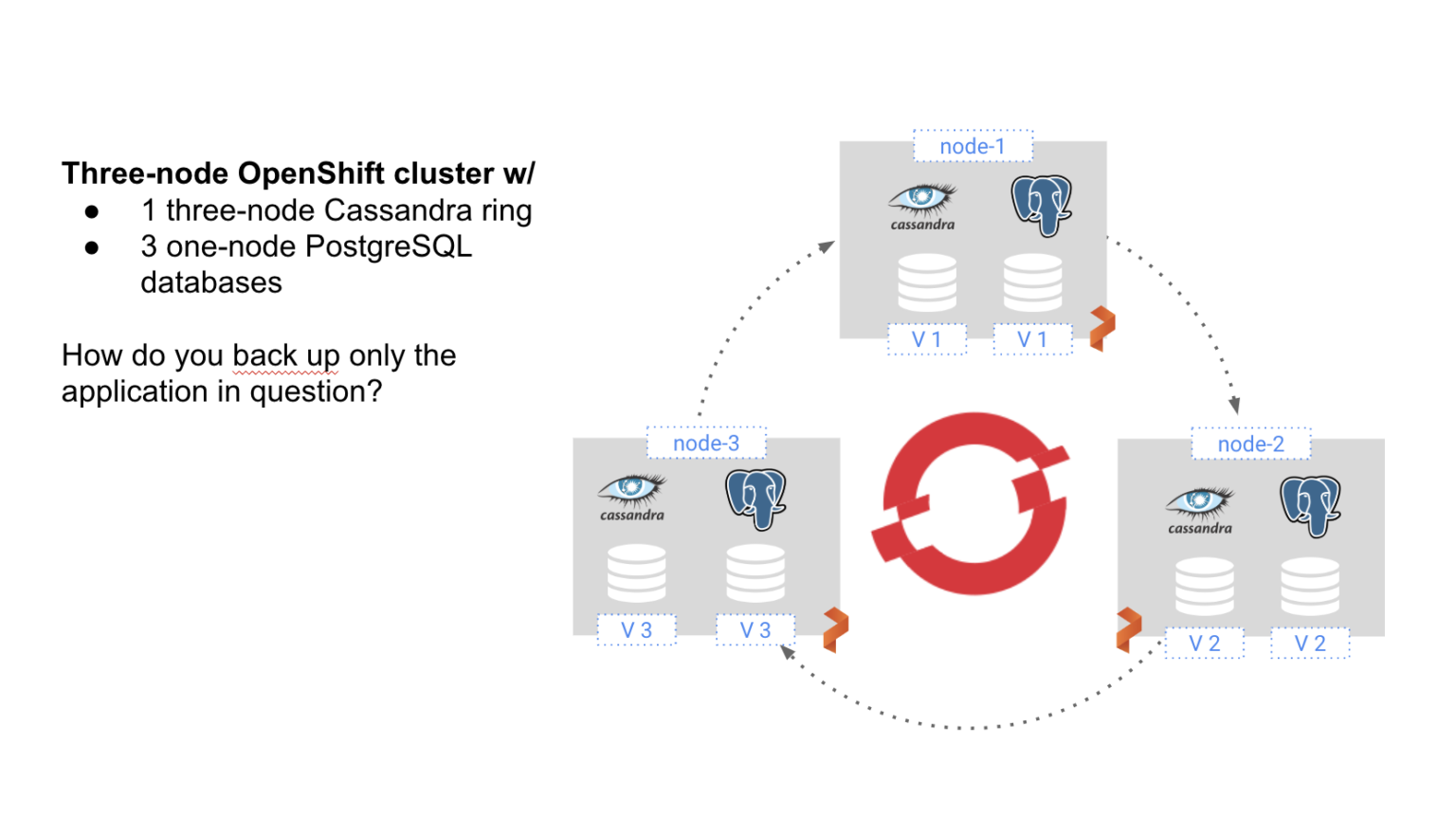
With PX-DR we can zero in on just the pods that we want to back up. For instance, we can back up just the three-node Cassandra ring or just one of the PostgreSQL databases. By offering container-granularity, we can avoid the complications of extract, transform, and load (ETL) procedures that would be required if we backed up all three VMs in their entirety. And by only backing up the specific applications desired, we can minimize storage costs and keep recovery time objectives (RTO) low.
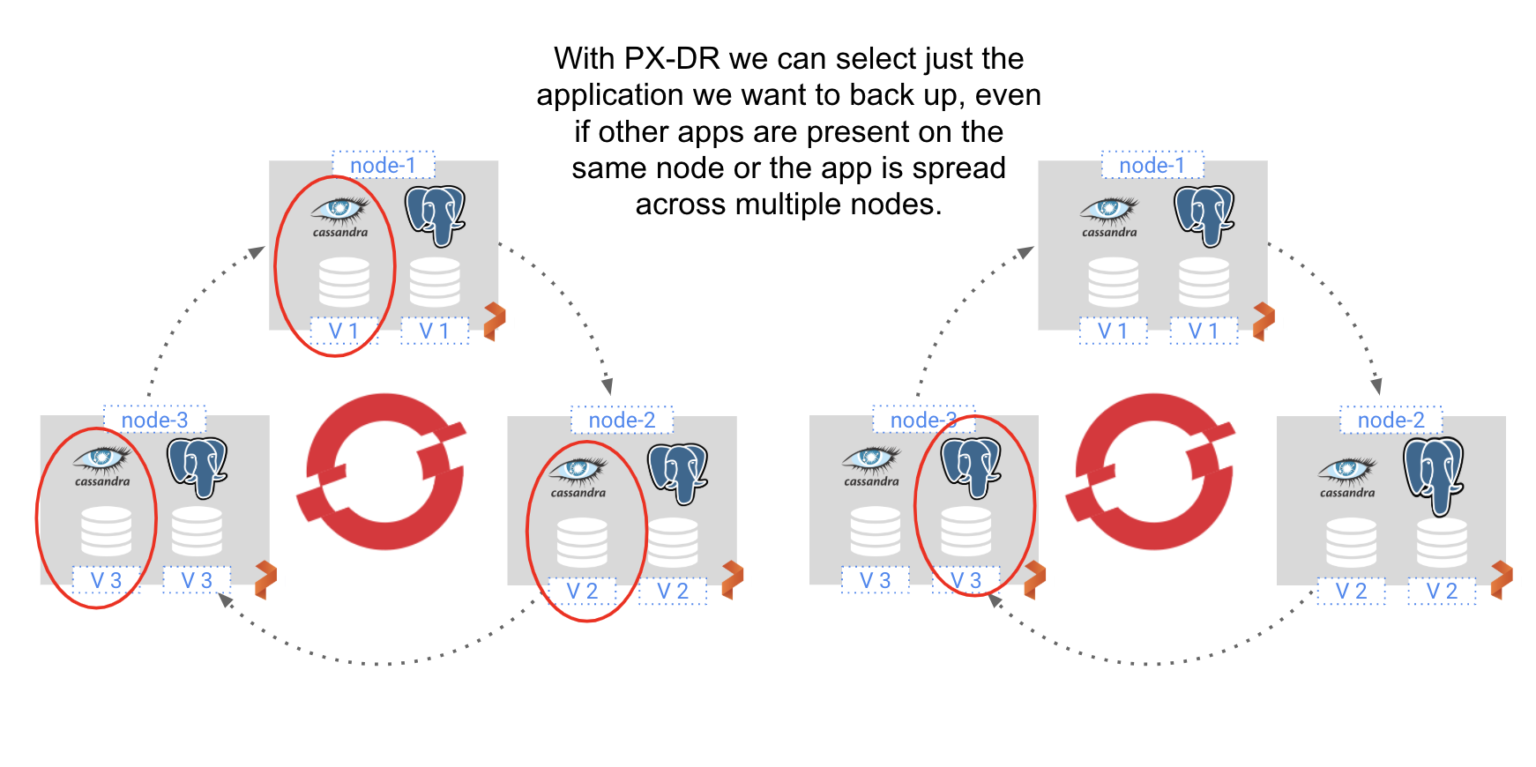
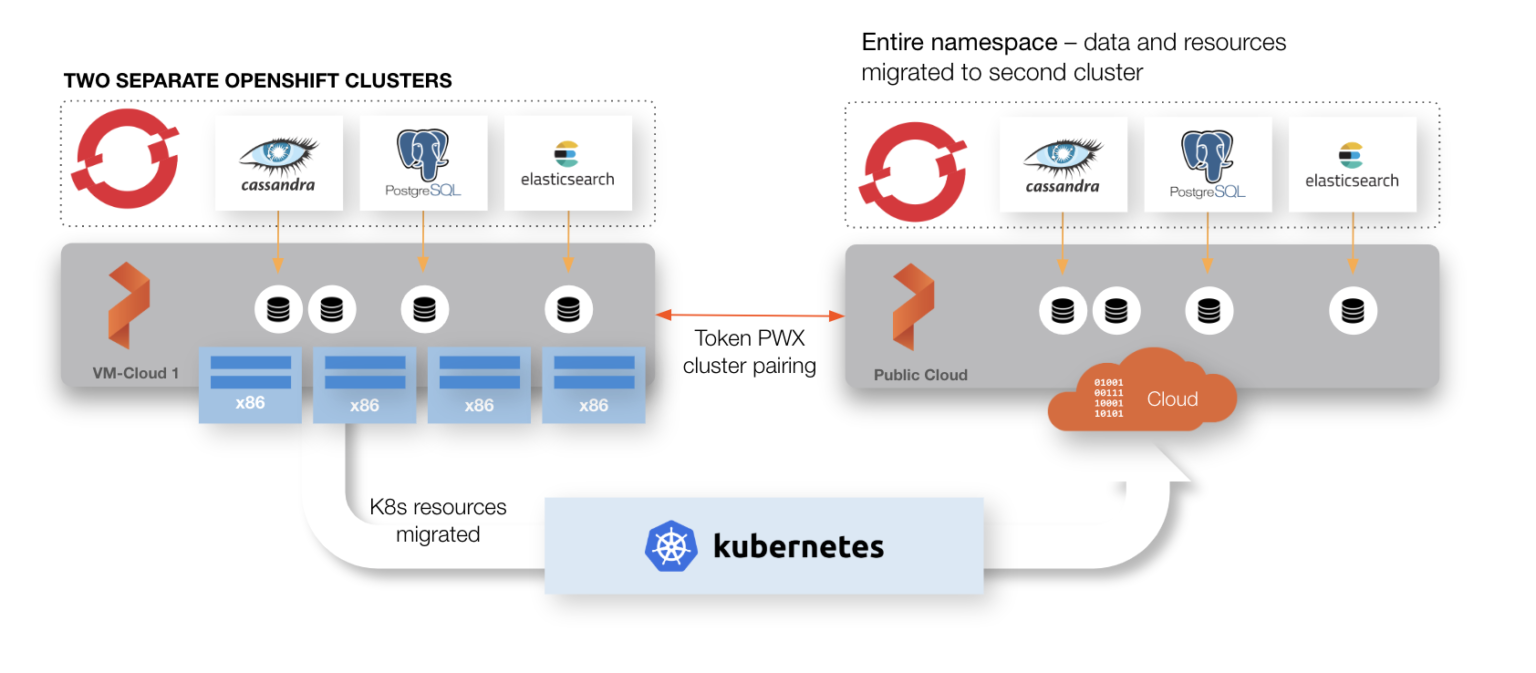
The concept of container-granularity can be extended to entire namespaces. Namespaces within Kubernetes typically run multiple applications that are related in some way. For instance, an enterprise might have a namespace related to a division of the company. Often, we want to back up the entire namespace, not just a single application running in that namespace. Traditional backup solutions run into the same problems outlined above. Namespaces bridge VM-boundaries. PX-DR, however, can give you the ability to backup entire namespaces, no matter where the pods that compose that namespace run.
PX-DR is also application consistent. Take the above example. The three Cassandra pods are a distributed system. Snapshotting them in a way that allows for application recovery without risk of data corruption requires that all pods be locked during the snapshot operation. VM-based snapshots cannot achieve this. Nor can serially executed individual snapshots. Portworx provides a Kubernetes group snapshot rules engine that allows operators to automatically execute the pre- and post- snapshot commands required for each particular data services. For Cassandra, for instance, we must run the nodetool flush command to take an application consistent snapshot of multiple Cassandra containers.
apiVersion: stork.libopenstorage.org/v1alpha1 kind: Rule metadata: name: cassandra-presnap-rule spec: - podSelector: app: cassandra actions: - type: command value: nodetool flush
We’ve now established the importance of container-granularity, being aware of namespaces, providing application-consistent backups. Now, let’s look at why DR for OpenShift requires a solution of data and application configuration.
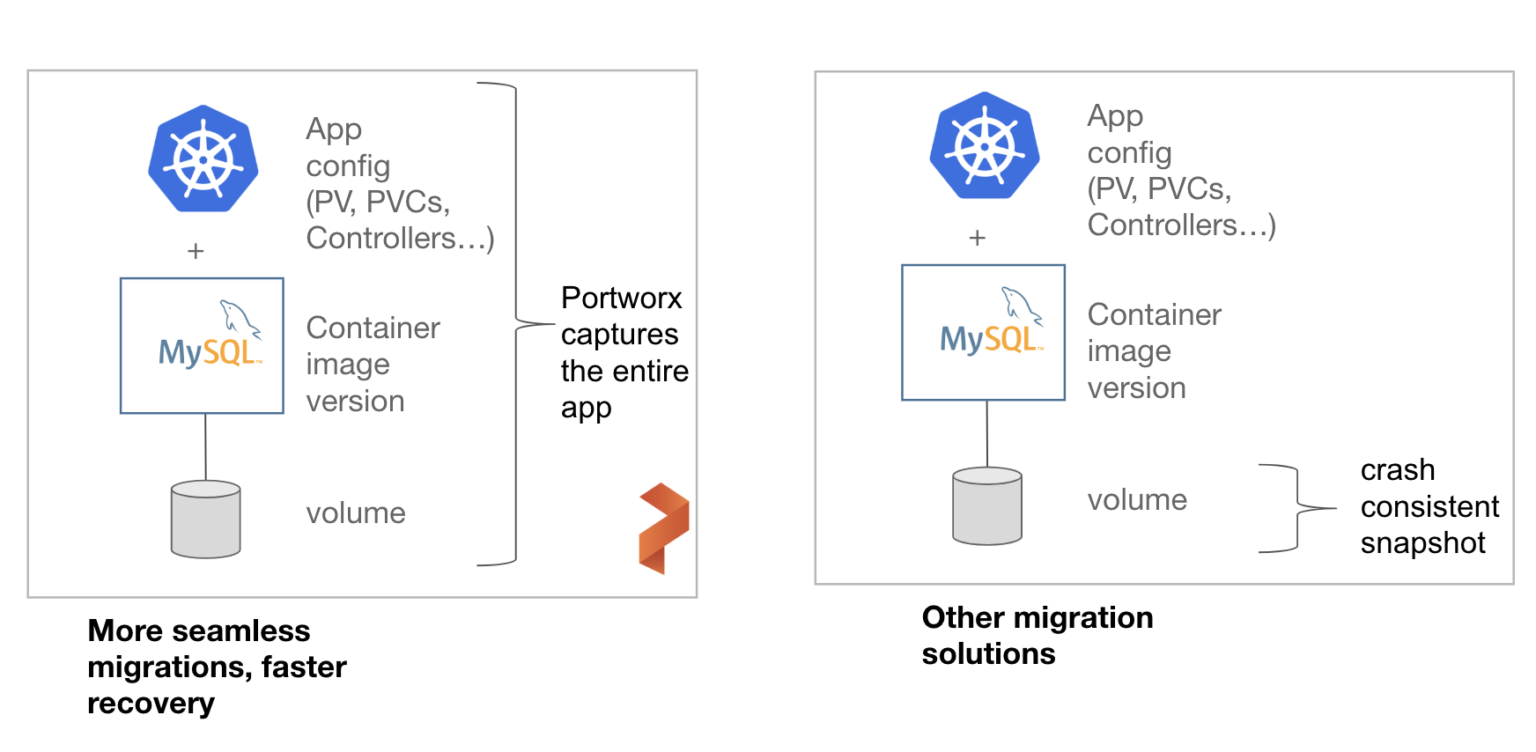
Backing up and recovering an application on OpenShift requires two things: data and app configuration. If we only back up the data, then recovering our application will take a long time, because we will have to rebuild the application configuration in place, increasing RTO. If we only back up the app config–all those yaml files that define our deployments, our service accounts, our PVCs–then we can spin up our application, but we won’t have our application data. Neither is sufficient. We need both. PX-DR captures both application configuration and data in a single OpenShift command, making recovering our OpenShift application after a failure using `oc -f apply myapp.yml` because recovering the application is simply the same process as deploying it initially.
Picking the right DR strategy for OpenShift requires an understanding of your goals and your data center architecture. Based on these goals, you will pick a synchronous or asynchronous disaster recovery model. In some cases, you might even pick both, as each provides a different layer of resiliency.
For instance, a bank with an on-prem data center Direct Connected into an AWS region might require RPO Zero DR for an important customer engagement application along with an RTO of < 1 minute. In this case, they will opt for Synchronous PX-DR because they can provide zero data loss due to the low latency between their two environments.
On the other hand, a manufacturing company with data centers on the East and West coast of the United States might have an application that requires a low RTO, but hourly backups are sufficient to meet their RPO goals. In this case, an asynchronous PX-DR model using continuous, incremental backups will work.
| Application and Infrastructure requirements for OpenShift Disaster Recovery | Synchronous DR | Asynchronous DR |
| Number of Portworx clusters | 1 | 2 |
| Needs an S3-compatible object store to move data? | No | Yes |
| Max round trip latency between data centers | < 10 ms | > 10 ms |
| Data guaranteed to be available at both sites (Zero RPO) | Yes | No |
| Low RTO | Yes | Yes |
Here is what these OpenShift DR architectures might look like in both cases.
Wide area network DR architecture for OpenShift (>10 ms roundtrip latency between sites)
Metro-area DR architecture for OpenShift (<10 ms roundtrip latency between sites)
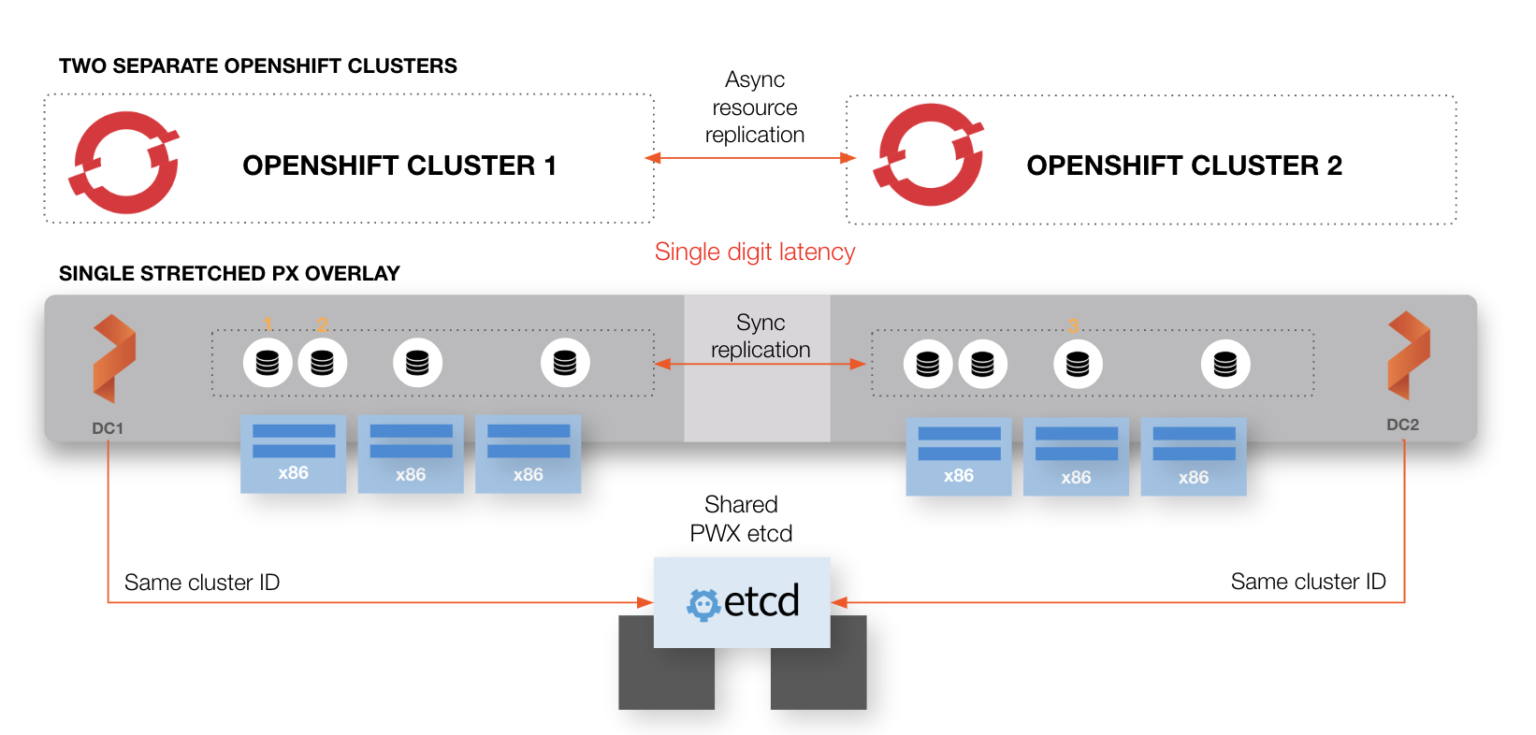
While PX-DR supports synchronous and asynchronous DR for OpenShift, this demo will focus zero RPO synchronous DR. Let’s walk through the concepts and configuration for synchronous disaster recovery with Portworx and Openshift including initial setup and triggering a failover. ### Multiple sites, single Portworx data management layer As seen in the architecture diagram above, synchronous PX-DR uses a single Portworx data management layer which sits below multiple Openshift clusters. This helps provide that copies of data are always available in both OpenShift sites. A single data management layer also means that there is effectively one Portworx cluster but with two cluster domains. A cluster domain allows the Portworx data management layer to distinguish between the Primary site versus the DR Site. The cluster domains are configured when the Portworx cluster is installed. In each of your OpenShift clusters (Primary and DR), configure Portworx to include the same key-value store endpoint and cluster name but use different cluster domains to identify each site. See the example below:
Primary DR Site args: ["-k", "etcd:http://etcd:2379", "-c", "px-cluster-synchronous", "-s", "type=gp2,size=250", "-secret_type", "k8s", "-cluster_domain", "primary" "-x", "kubernetes"] ``` args: ["-k", "etcd:http://etcd:2379", "-c", "px-cluster-synchronous", "-s", "type=gp2,size=250", "-secret_type", "k8s", "-cluster_domain", "dr-site" "-x", "kubernetes"]
Low Latency Requirement
Synchronous PX-DR also needs low latency. Why? Because each write will be synchronously replicated to the backup site and application performance will suffer if the latency is too great. This is why volumes in this architecture must use a replication factor of at least two. The latency should be a maximum of 10ms round trip time to the DR site but please keep in mind some applications may need even lower latency than this. When designing your application, think about the architecture and the overall latency needs for the application, this specific number is just a suggestion for PX-DR. To test your RTT, you can use the ping utility between sites. Note the bottom line starting with rtt, which gives the minimum, average, maximum and standard deviation.
$ ping ip-10-0-131-167 PING (10.0.131.167) 56(84) bytes of data. 64 bytes from (10.0.131.167): icmp_seq=1 ttl=255 time=0.019 ms 64 bytes from (10.0.131.167): icmp_seq=2 ttl=255 time=0.028 ms 64 bytes from (10.0.131.167): icmp_seq=3 ttl=255 time=0.035 ms 64 bytes from (10.0.131.167): icmp_seq=4 ttl=255 time=0.029 ms 64 bytes from (10.0.131.167): icmp_seq=5 ttl=255 time=0.028 ms ^C --- ip-10-0-131-167.us-west-2.compute.internal ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4080ms rtt min/avg/max/mdev = 0.019/0.027/0.035/0.008 ms
Setup the Openshift Cluster Pair
Once the both sites are running Portworx, they should be successfully synced together with the proper Cluster Domain setup. To validate this, you can run the Portworx command: “` $ pxctl cluster domains show “` Once verified that both domains are (Active), it’s time to create the cluster pair object so that both sites can share OpenShift Application YAML files back a forth. These YAML files represent our application configuration and are an essential part of having low RTO in the case of an outage. First, generate the cluster pair for the target namespace then apply that YAML to the primary site.
$ storkctl generate clusterpair -n appns dr-site > dr-site.yaml $ oc create -f dr-site.yaml
You can verify the cluster pair by running the following command.
$ storkctl get clusterdomainsstatus
Create a schedule and migration
Depending on your organizations RTO requirements you may want to choose to sync your application state at specific intervals. To do this, you first need to create a policy which specifies a schedule, then associate that schedule with a migration of applications.
First, create a schedule. The example below migrates application configuration as quickly as every minute. Save this as a yaml file and use `oc create -f` to create the policy.
apiVersion: stork.libopenstorage.org/v1alpha1 kind: SchedulePolicy metadata: name: sched-policy namespace: appns policy: interval: intervalMinutes: 1 daily: time: "10:14PM" weekly: day: "Thursday" time: "10:13PM" monthly: date: 14 time: "8:05PM"
Next, create a migration that targets the “appns” namespace, “dr-site” cluster pair and uses this schedule, notice the “schedulePolicyName” near the bottom of the file. Again, save this to a yaml file and apply it with ` oc create -f`.
apiVersion: stork.libopenstorage.org/v1alpha1 kind: MigrationSchedule metadata: name: migrationschedule namespace: appns spec: template: spec: clusterPair: dr-site includeResources: true startApplications: false includeVolumes: false namespaces: - demo schedulePolicyName: sched-policy
Note that the above only sets includeResources to true and the rest to false because our synchronous DR cluster is already making data available to both clusters so we don’t need to include volumes and we don’t want to start the application until we have had a failure event. If we were using the Asynchronous PX-DR method, we would turn `includeVolumes` to true.
You can verify that migrations are occurring by running the following command.
$ storkctl get migration
### Failover to your OpenShift DR Site
Now that our OpenShift clusters are synced and applications are being synced as well, we are prepared to recover our applications. When a disaster occurs on the primary site, the following steps are used to failover the application with zero RPO to the DR site.
First, deactivate the primary site and wait for the domain to become (NotInSync)
$ storkctl deactivate clusterdomain ocs-primary $ storkctl get clusterdomainsstatus
Next, if you have access to the primary site, scale the replicas to 0. If you don’t have access to the primary site, then skip to the next section which activates the applications on the DR site.
$ oc scale deploy -n demo --replicas=0 --all
Also, suspend the migration by adding `suspend: true` to the MigrationSchedule and apply the updated spec.
apiVersion: stork.libopenstorage.org/v1alpha1 kind: MigrationSchedule metadata: name: migrationschedule namespace: appns spec: template: spec: clusterPair: dr-site includeResources: true startApplications: false includeVolumes: false namespaces: - demo schedulePolicyName: sched-policy suspend: true
$ oc apply -f migration-schedule.yaml
Finally, on the DR site, activate the migration to turn the pods on in the DR site.
$ storkctl activate migration -n appns
Your applications from the “appns” namespace should now be up and running with zero data loss in your OpenShift DR Site.
PX-DR includes an API for the automation of the above steps. Additionally, when the original site comes back online, application configuration and data will be resynced so that you can fail back your applications.



