

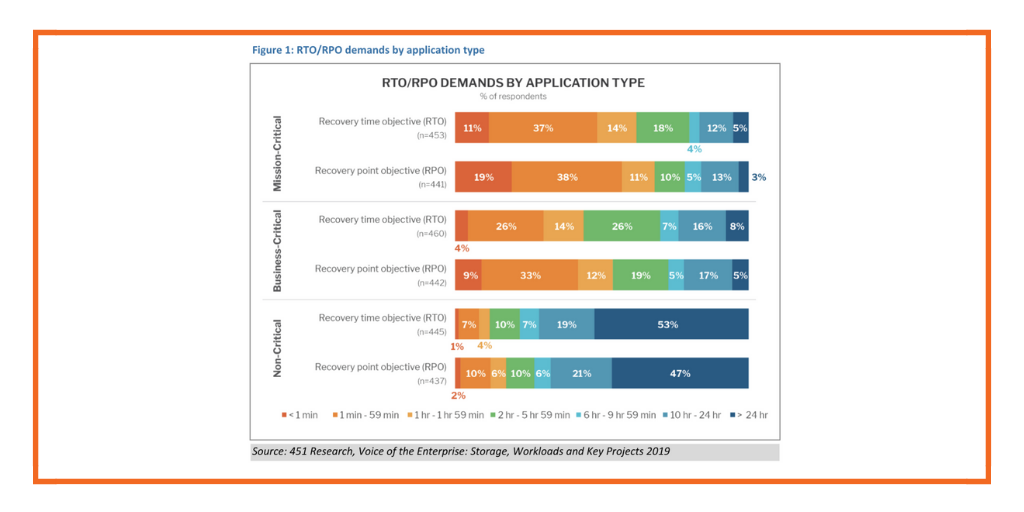
In today’s fast-paced digital landscape, the reliability and availability of applications are paramount. Organizations must ensure that their applications can recover quickly from failures, minimizing both data loss and downtime. This is where the concepts of Recovery Point Objective (RPO) and Recovery Time Objective (RTO) come into play. In this blog, we’ll dive deep into what RPO and RTO are, how they influence your disaster recovery strategy, and how Portworx can help you achieve optimal RPO and RTO for your applications.
RPO and RTO are critical metrics in disaster recovery planning that help define the acceptable levels of data loss and downtime an application can tolerate in the event of a failure.
Both RPO and RTO are integral to determining the resilience of an application and the effectiveness of its disaster recovery plan.
To better understand RPO, imagine you have a critical application running on a Kubernetes cluster, such as a financial transaction processing system. Backups are taken every two hours. In this scenario, the RPO is two hours; as the organization has determined that two hours is the maximum acceptable age of its backup data to maintain normal business operations in the event of disruption.
Achieving a low RPO—especially near zero—requires a robust data replication strategy. Continuous replication ensures that data is always synchronized between your primary and disaster recovery (DR) sites. Portworx facilitates this by offering real-time replication, where data is continuously copied from the primary site to the DR site. Replication must occur at the storage level, so only fully integrated data management solutions like Portworx can provide enterprises with the disaster recovery capabilities. This ensures that in the event of a disaster, you can recover data with minimal or no loss, meeting stringent RPO requirements.
Other Kubernetes-native backup and restore solutions are not able to provide replication at the storage level and rely instead on backup snapshots to recover data. Because there is no real-time replication, these solutions are usually not sufficient to protect mission-critical applications.
While RPO focuses on data loss, RTO deals with downtime—the amount of time an application can be offline before it affects business operations. For instance, if an application needs to be online within 30 minutes of a failure to avoid significant impact on users or revenue, then its RTO is 30 minutes.
Reducing RTO – the time to workload recovery in the event of an outage – requires a solid disaster recovery strategy. In Kubernetes environments, Portworx can orchestrate the restoration of workloads on a different node or cluster as well as replicating the data between nodes and sites..
Portworx also supports the concept of application consistency, ensuring that the entire state of the application, including data and configuration, is restored. This allows for a seamless recovery, where users can resume their work without significant disruption.
The ability to achieve the requirements for RPO and RTO is critical for any organization, especially those in sectors like finance, healthcare, and e-commerce, where downtime and data loss can have significant consequences. Portworx offers several features that help you meet stringent RPO and RTO requirements:
It’s important to note that different applications may have different RPO and RTO requirements. For instance, a customer-facing e-commerce site might require an RPO of a few minutes and an RTO of near zero, while an internal reporting application might tolerate an RPO of several hours and an RTO of one hour.
When planning your disaster recovery strategy, it’s crucial to:
Portworx provides the flexibility and tools needed to tailor RPO and RTO to meet the specific needs of each application, ensuring that your disaster recovery plan is both comprehensive and effective.
RPO and RTO are vital components of any disaster recovery plan. By understanding these concepts and implementing the right tools and strategies, you can ensure that your applications are resilient, with minimal data loss and downtime in the event of a disaster.
Portworx offers powerful features in addition to Kubernetes storage that help you achieve optimal RPO and RTO, ensuring that your data is protected and your applications can recover quickly. Whether you’re dealing with a minor disruption or a major disaster, Portworx enables you to maintain business continuity and protect your critical data assets.
In the end, a well-defined disaster recovery plan supported by Portworx’s persistent storage and advanced capabilities can be the difference between a quick recovery and a prolonged outage. Take the time to assess your RPO and RTO needs, configure your systems accordingly, and leverage Portworx to keep your business running smoothly, no matter what challenges arise.


