




We first discussed the importance of Kubernetes backup tools and compared some common tools in the ecosystem in April of 2020. You can read the article here.
The importance of data protection in the enterprise has continued to increase since 2020. As organizations start to onboard more production applications onto their Kubernetes platforms, many are taking the next step and finding solutions to protect data across their environments. Nearly 55% of Kubernetes IT professionals say that backup and restore is a top concern[1] for their stateful applications running on Kubernetes.

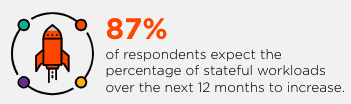
Tackling this challenge comes along with making sure your Kubernetes backup capabilities are scalable, flexible, and purpose-built for Kubernetes—both are important for your overall data protection plan. With more than 53% of applications running on Kubernetes being stateful[2], backup and restore capabilities are becoming more important for these stateful applications.
Data protection for applications can mean many things to an organization. A common denominator for data protection is to protect applications and the data they own in the case of something going wrong or, in the worst case scenario during a catastrophic issue such as a complete cryptographic lock on data during a ransomware attack or a physical datacenter outage during a natural disaster. However, techniques and requirements vary quite a bit within these scenarios.
Traditional business continuity and disaster recovery (BCDR) approaches simply do not live up to the Recovery Point Objective (RPO) and Recovery Time Objective (RTO) requirements for most mission-critical applications running on Kubernetes. Let’s explore why having a backup solution alone may not be enough.
Applications on Kubernetes are subject to varying levels of failures while they are running on any Kubernetes platform, including:
The above list of reasons make it imperative for applications to be protected across all domains which are local and remote. Having a backup solution that only offloads applications and data to object storage to make available for restore can make it slow and cumbersome to restore to production. It also does not fully achieve a solution that is flexible across the varying levels of potential issues. This is why using a platform such as Portworx by Pure Storage is imperative to provide the three levels of protection:
These three levels of protections are key to your success in protecting applications on Kubernetes. They are the foundation of any enterprise data protection program, and they are the essential elements to consider when evaluating a Kubernetes backup tool or solution.
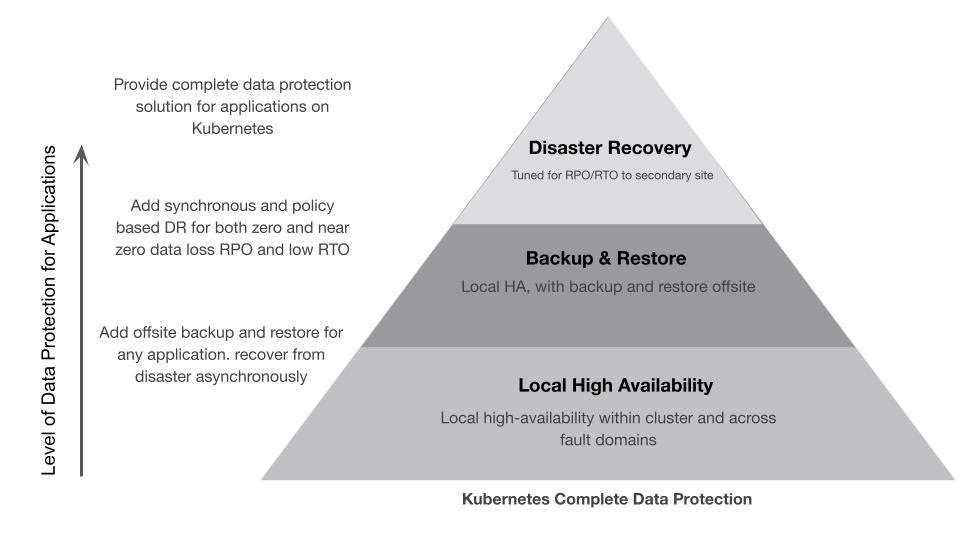
For more details on the differences between these three different levels of data protection, you can find detailed definitions for them in our previous blog.
Now, let’s take a look at some of the common tools and GigaOm Data Protection for Kubernetes leaders in the ecosystem and see how they stack up to these critical levels of data protection.
| Tool | Local HA | Backup & Restore | Disaster Recovery |
| Portworx by Pure Storage | ⬤ | ⬤ | ⬤ |
| Kasten by Veeam | X | ⬤ | ◕[3] |
| Velero by VMWare | X | ⬤ | ◕[4] |
| Metallic by Commvault | X | ⬤ | ◕[5] |
| Longhorn by SUSE | ⬤ | ◑[6] | ◑[7] |
Learn more about the latest PX-Backup has to offer by watching the below webinar and demo recording on PX-Backup 2.1.
Hopefully this article gives you a better understanding of the Kubernetes data protection landscape and why it is so different from traditional disaster recovery or backup and restore solutions in the ecosystem today. Very plainly, applications are built differently in today’s cloud native architectures, and this demands a new set of solutions capable of understanding the needs of the application to truly protect it and enable users to quickly recover from various levels of failure, all with a clear understanding of what moving pieces there are. These levels of protection are why Portworx is a leader in both the Data Protection for Kubernetes and Data Storage for Kubernetes GigaOm categories.
[1] The Pure Storage Survey was conducted by Wakefield Research (www.wakefieldresearch.com) among 500 IT Professionals, employed full-time in the US (250) or UK (250) at companies of 500+ employees, who self-identify as possessing significant knowledge of their company’s Kubernetes usage and currently running stateful applications on Kubernetes.
[2] See footnote #1
[3] This backup and restore solution can be manually used or placed on a schedule to restore from disaster; however, this disaster recovery solution does not offer zero RPO solutions for synchronous disaster recovery, so it is not considered a full solution when compared to Portworx Backup and DR capabilities. Reference: https://docs.kasten.io/latest/usage/protect.html
[4] See footnote #1; Reference https://velero.io/docs/v1.8/disaster-case/
[5] See footnote #1; Reference https://docs.metallic.io/metallic/protecting_kubernetes_with_metallic.html
[6] Longhorn only backs up the data volume to object storage, not the full application and data together. Reference https://longhorn.io/docs/1.2.3/snapshots-and-backups/backup-and-restore/create-a-backup/
[7] See footnote #1. Additionally, DR Volumes do not include application metadata. Reference https://longhorn.io/docs/1.2.3/snapshots-and-backups/setup-disaster-recovery-volumes/


