




Read Part II of Kubernetes Backup tools published January 2022!
The importance of data protection in the enterprise is greater than ever. Data protection can refer broadly to concepts such as backup and restore, high availability, business continuity, and disaster recovery. Whatever you call it, all enterprises must implement, test, and maintain strategies for data protection in order to avoid risking their reputation and revenue when things go wrong.
As data becomes more important in customer experience and business processes, there is also little tolerance for downtime that makes it impossible to access critical information. According to the Uptime Institute’s study, 41% of outages cost over $1 million, which indicates the increasing dependence of enterprises on the Highly Available (HA) data infrastructure.
Consequently, a viable data protection strategy has to ensure that downtime is rare and that applications and their data can be restored quickly after downtime or data loss. Also, data protection strategies have to ensure data privacy and regulatory compliance (e.g., GDPR and CCPA), which become very important as more users expose their critical data online.
Notwithstanding pressing data protection demands, most companies struggle to protect their data. Traditional data protection methods that work well for applications running on a single host do not scale well in the distributed or multi-datacenter environment, such as those common in Kubernetes environments. Traditional business continuity and disaster recovery (BCDR) approaches simply do not live up to the Recovery Point Objective (RPO) and Recovery Time Objective (RTO) requirements for most mission-critical applications running on Kubernetes.
Because each application and each enterprise is different, data protection comes in many different forms, and the particular forms that are important for each app and enterprise depend on a number of factors. When considering a data protection solution, some of the questions you might be asking yourself may include the following:
Some of these questions depend on whether, for example, you are trying to:
At a high level, these scenarios could be described as examples of Local High Availability, Backup and Restore, and Disaster Recovery. These three capabilities are the foundation of any enterprise data protection program, and they are the essential elements to consider when evaluating a Kubernetes backup tool or solution. Requirements within these solutions can vary, and it is imperative that the business has the right elements to protect the applications and their data based on specific requirements. Often, static backups alone are not enough to protect the necessary data protection; local high availability is required, too.
Local High Availability, Backup and Restore, and Disaster Recovery are the essential elements to consider when evaluating a Kubernetes backup tool or solution.
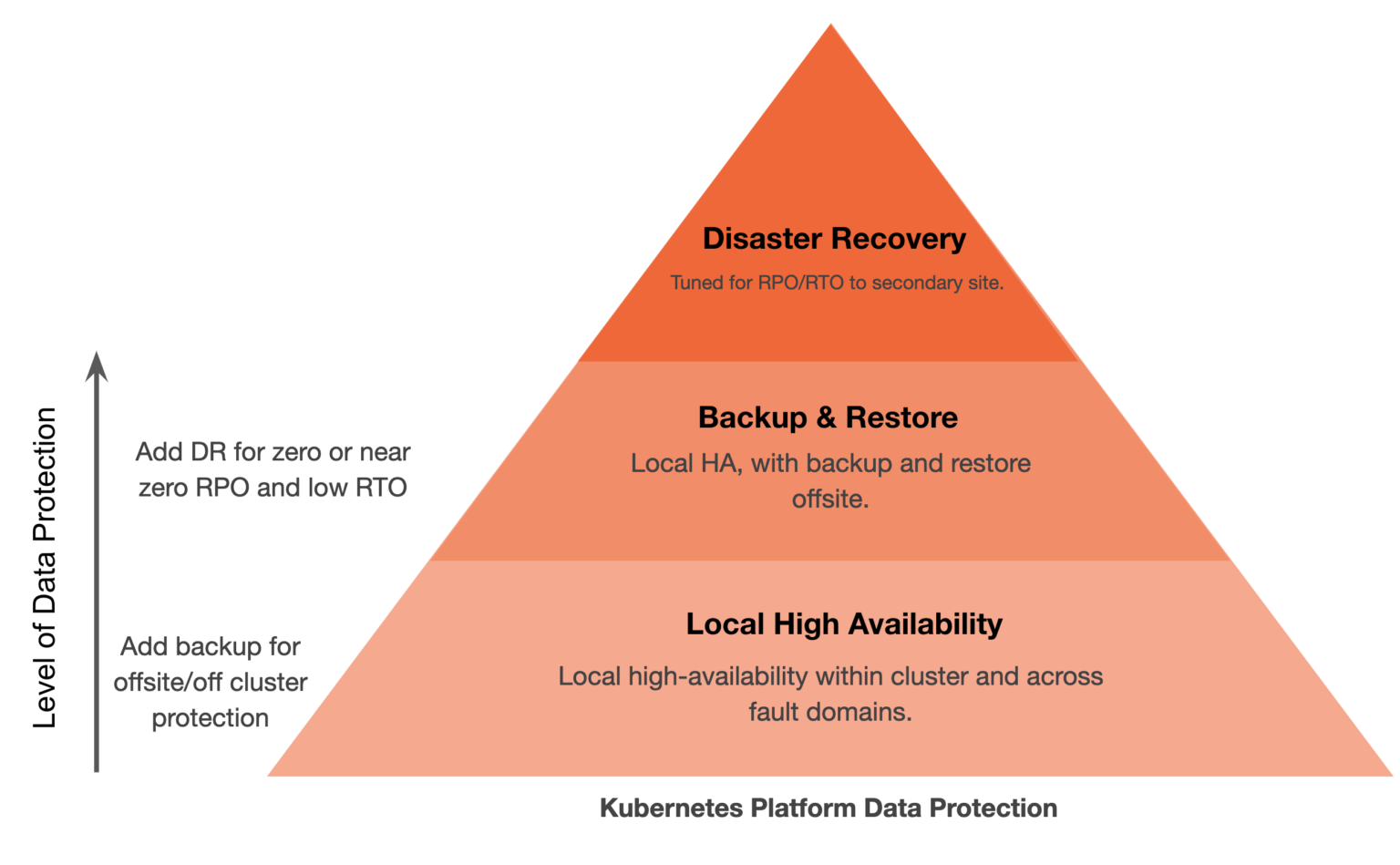
The data protection ecosystem for Kubernetes is new, and certain solutions provide capabilities for one or more of these solutions. This blog will look at some of the major players in today’s Kubernetes ecosystem that focus on the aforementioned data protection capabilities for Kubernetes applications.
The solutions that we look at in this blog focus on protecting the running application and the application’s persistent data and not solutions that backup the Kubernetes node services or ETCD store like Veeam’s solution.
Let’s define the above terms a bit more so that this blog can be as informative as possible for those trying to understand the backup tools and data protection ecosystem for Kubernetes.
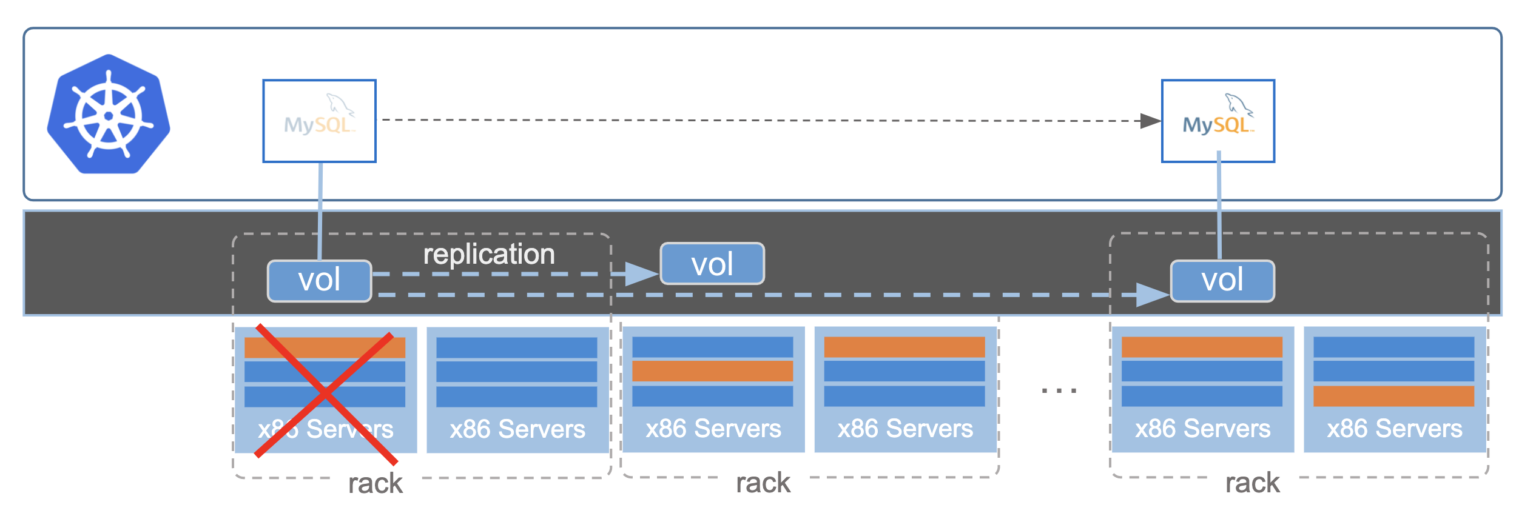
Local high availability is the ability to protect against a failure within a single data center or, in the case of the cloud, across availability zones. When a failure occurs at the infrastructure, application, or node level where the application is running, this is considered local. When local high availability is supported by a Kubernetes backup tool, applications or replicas of an application can incur a failure of this type without downtime, making it highly available to the end user. This type of failure would normally cause application downtime and therefore, downtime to the consumer. A common example of downtime resulting from a local failure is a stuck cloud volume after a node failure.
You can think of local high availability as the base of the data protection pyramid. To provide local high availability, a solution typically needs to be in the data path and offer some type of data replication locally. If local availability is provided by restoring from backups, that is considered backup and recovery since the restore times are typically too long to be considered HA.
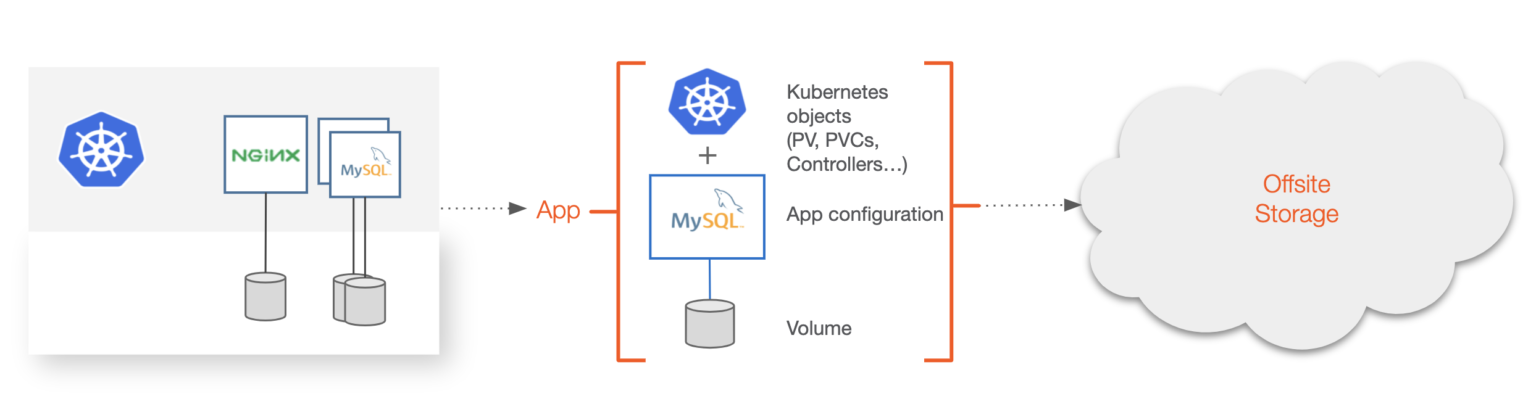
Backup and recovery for Kubernetes is focused on the backup of the entire application from the local Kubernetes cluster to somewhere offsite. Offsite could be object storage in public or private clouds or storage available on prem in different regions or failure domains. Backup solutions can also have multiple backup targets. Backups are done often to protect from system failure or complete a compliance or regulatory checklist for your application. To be considered a “Kubernetes backup,” the backup software must be able to understand the semantics of what makes up the Kubernetes application. This includes:
These objects must be backed up as a single unit to be useful in a Kubernetes context. Traditional backup systems do not take this into account and often target the VM, server, or disk the application is using and not the mixed group of heterogeneous resources. A Kubernetes backup solution should also be able to backup an individual application, group of applications, or entire Kubernetes namespace. These solutions should also support certain aspects of traditional backup, such as schedules, jobs, retention, encryption, and tiering.
A Kubernetes backup must include Kubernetes resources like secrets, service accounts, CRDs, application configuration, and data.
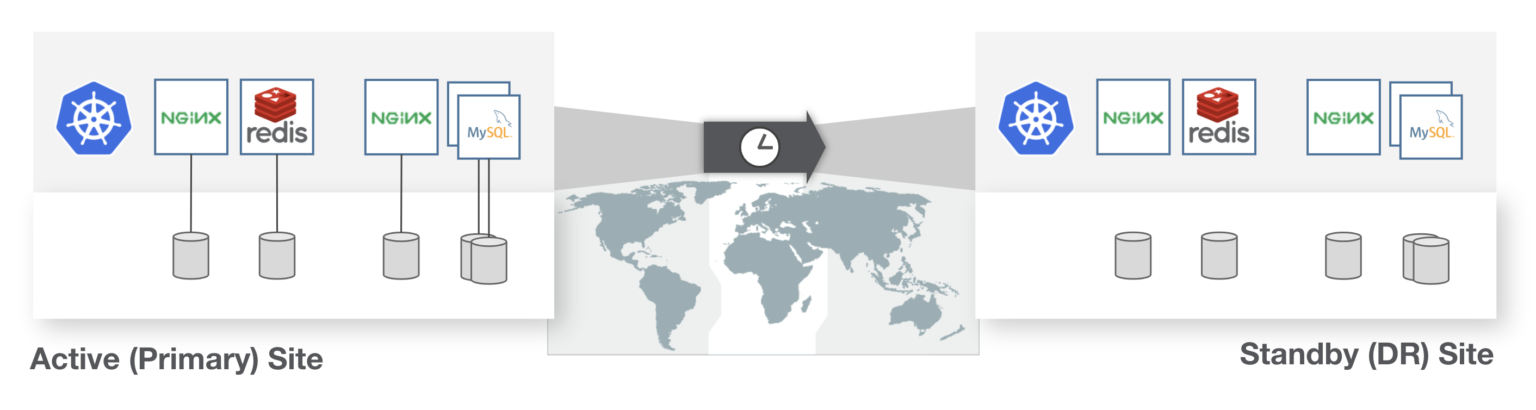
Like backup, disaster recovery (DR) must also consider the disparate Kubernetes objects, application configuration, and data that makes up a Kubernetes application. Resources and persistent state should recover as a single entity being protected from a primary site to another. The DR system must also handle varying levels of RPO and RTO, and depending on the cost and business requirements, protect at these different levels.
One example would be Zero RPO where applications cannot incur any data loss. Another example would be 15-minute RPO where requirements are a bit more relaxed. Additionally, one application could have a RTO objective of <2 minutes while another might be okay with an hour of downtime.
The DR system must also (to some degree) understand how the application is configured to be run in the recovery site. This means it should be able to understand metadata such as labels or replicas the recovered application should start with and do this without human intervention. If these types of Kubernetes APIs are not understood, this could lead to disjointed recovery and ultimately downtime or data loss.
Now that we have an understanding of the different types of data protection that must be included in a Kubernetes backup tool or solution, let’s take a look at how some of the industry players compare.
*This comparison was conducted using the websites and documentation of the evaluated providers.
Quick reference
X – Does not claim to have this feature, or does not show any support for said feature.
❍ – Claims to have a feature by the name, but is lacking major functionality.
◑ – `, but is missing completeness.
✓ – Claims to have a feature by the name; functionality is complete per website or documentation.
| Local HA | Disaster Recovery | Backup and Restore | |
| Cohesity | X | X | ◑ |
| Kasten | X | ◑ | ✓ |
| OpenEBS | ✓ | X | ◑ |
| Portworx | ✓ | ✓ | ✓ |
| Rancher Longhorn | ✓ | ❍ | X |
| Velero | X | ❍ | ✓ |
In Cohesity’s words[1], “Cohesity protects data and application state for Kubernetes namespace. The web-scale platform backs up the namespace including all its operational state—not just its data—comprehensive protection.” Cohesity is a major player in the secondary storage and data protection ecosystem. It recently started supporting Kubernetes by allowing backups of data and applications from the namespace. This solution does understand Kubernetes applications, which is unique for traditional backup solutions, but Cohesity targets the entire namespace only and does not protect individual applications within a namespace, which is often needed because all applications in a namespace do not need the same level of protection. This is why it has a half circle. Cohesity does not have primary storage for Kubernetes or have an integration for Kubernetes-based DR yet, which is why it does not meet criteria of the other two categories. However, Cohesity does have a plethora of solutions for VMs and, combined with the new Kubernetes play, is starting to make a strong entrance to the ecosystem.
In Kasten’s words[2], “The K10 data management platform, purpose-built for Kubernetes, provides enterprise operations teams an easy-to-use, scalable, and secure system for backup/restore, disaster recovery, and mobility of Kubernetes applications.” Kasten is built mostly for backup/restore, disaster recovery, and mobility of applications across clusters. Kasten itself uses the underlying data storage systems—such as EBS or RBD—and does not directly support its own replication within a single cluster, so it does not meet requirements for Local HA. As mentioned above, relying on cloud block storage directly for Kubernetes volumes often results in application downtime due to stuck volumes. It does have disaster recovery listed, so you might ask why it gets a half circle here. The reason is because there is no data path component, so Kasten cannot achieve Zero RPO (no data loss) use cases, and backups are only asynchronous, so there will be a delta between the latest write to an application and the state in the latest backup. While this is often okay for enterprise applications, it does not meet Zero RPO requirements for Disaster Recovery which are common in the enterprise. To learn more about RPO and RTO, see the video below.
OpenEBS describes their solution this way[3]: “We’re an Open Source abstraction layer between your applications and any local, network or cloud storage. Reduce maintenance, lower storage costs, and simplify administration with OpenEBS.” OpenEBS mostly focuses on the Local HA usecase; however, it also has an integration with Velero (see more on Velero below) that enables a solution they call OpenEBS Data Management as a Service (DMaaS). DMaaS is a solution that can “migrate Kubernetes stateful workloads along with their persistent data from anywhere to anywhere, be it on-premise or across clouds”[4] and is based on Velero. Contrary to Cohesity that only backups an entire namespace but not individual Kubernetes apps, OpenEBS only backs up individual apps. While the app-specific flexibility is a positive, some uses require namespace-aware backups. Additionally, OpenEBS can only be used to backup stateful applications where there is a persistent volume present, and it can’t be used to backup or migrate only Kubernetes objects and application configuration. OpenEBS backup is based on Velero, which has its own limitations—such as not being able to offer full featured disaster recovery—and OpenEBS doesn’t claim support for this, either, though it could be used in a similar manner as Kasten as a backup-based disaster recovery strategy.
Portworx is an end-to-end storage and data management solution for any Kubernetes project, including container-based CaaS, DBaaS, SaaS, Backup and Restore, and Disaster Recovery initiatives. Portworx was ranked the #1 Kubernetes storage platform by GigaOm, who stated that Portworx has “a feature set and characteristics that are perfectly tailored for large enterprises and service providers. It is a sophisticated solution that is aimed at supporting complex Kubernetes infrastructures, no matter if they are deployed on-premises, in the cloud, or a hybrid fashion.” With Portworx, all Kubernetes apps benefit from container-granular storage, local high availability, disaster recovery, backups, data security, multi-cloud migrations, and more. Portworx provides a data layer that can stretch across low latency networks to enable zero RPO disaster recovery as well as provide fine grain application backup or wider namespace backup in addition to local persistent storage. Local high availability was the first use case Portworx supported, and that’s no different now that it has PX-DR and PX-Backup to offer comprehensive data protection.
According to Rancher[5], Longhorn is “lightweight, reliable, and powerful. You can install Longhorn on an existing Kubernetes cluster with one kubectl apply command or using Helm charts. Once Longhorn is installed, it adds persistent volume support to the Kubernetes cluster.” While Longhorn has a smaller community than other open-source solutions, it was recently accepted into the CNCF. Longhorn has a unique feature called a DR Volume which can be setup as a source and destination so the volume becomes active in a new cluster based on its latest backup. This is a neat solution to DR, though like Kasten, it is still backup-based, so it cannot achieve zero RPO DR, and it also does not include the application metadata or resources for a full Kubernetes application-aware recovery.
Velero describes its solution as[6] “an open source tool to safely backup and restore, perform disaster recovery, and migrate Kubernetes cluster resources and persistent volumes.” By itself, Velero only supports stateless application resources, but users can choose or add plugins for persistent volume claim snapshots backup. The other alternative is Restic, which is a file/copy based approach when plugin support for snapshots is not available or needed. So, Velero by itself does not tackle the data problem for Kubernetes applications, though, when combined with a plugin or Restic, it can provide backup and restore as well as a level of asynchronous backup-based disaster recovery in much the same way OpenEBS and Kasten can provide DR, so zero RPO is out of the cards.
If you want to learn more about RTO and RPO, check out this lightboard video.
Hopefully this article gives you a better understanding of the Kubernetes backup tool and data protection landscape and why it is so different from traditional disaster recovery or backup and restorer solutions in the ecosystem today. Very plainly, applications are built differently in today’s cloud native architectures, and this demands a new set of solutions that are able to understand the needs of the application to truly protect it and enable users to quickly recover from various levels of failure, all with a clear understanding of what moving pieces there are.
Thanks for reading. If you have any questions about the data presented, please feel free to contact us.
References
[1] https://www.cohesity.com/resource-assets/solution-brief/Data-Protection-for-Entire-Kubernetes-and-Container-Application-Stack-Solution-Brief.pdf
[2] www.kasten.io/product/
[3] https://openebs.io/
[4] https://help.mayadata.io/hc/en-us/articles/360033401591-DMaaS
[5] https://github.com/longhorn/longhorn
[6] https://velero.io/


