


 Apache Kafka is the leading open-source distributed event store and stream-processing platform for collecting, processing, storing, and analyzing data at scale. A Kafka deployment includes a cluster of nodes called Kafka brokers, which handle all the requests from producers and consumers. Producers write or publish messages to a Kafka topic, and consumers can read these messages from the topic they subscribe to. Kafka topics organize and structure messages and are often divided into partitions, which are replicated across the brokers. Thousands of companies use Kafka, such as Intuit, Airbnb, Netflix, PayPal, Spotify, and others, and an impressive 60% of the Fortune 100 are included in the list.
Apache Kafka is the leading open-source distributed event store and stream-processing platform for collecting, processing, storing, and analyzing data at scale. A Kafka deployment includes a cluster of nodes called Kafka brokers, which handle all the requests from producers and consumers. Producers write or publish messages to a Kafka topic, and consumers can read these messages from the topic they subscribe to. Kafka topics organize and structure messages and are often divided into partitions, which are replicated across the brokers. Thousands of companies use Kafka, such as Intuit, Airbnb, Netflix, PayPal, Spotify, and others, and an impressive 60% of the Fortune 100 are included in the list.
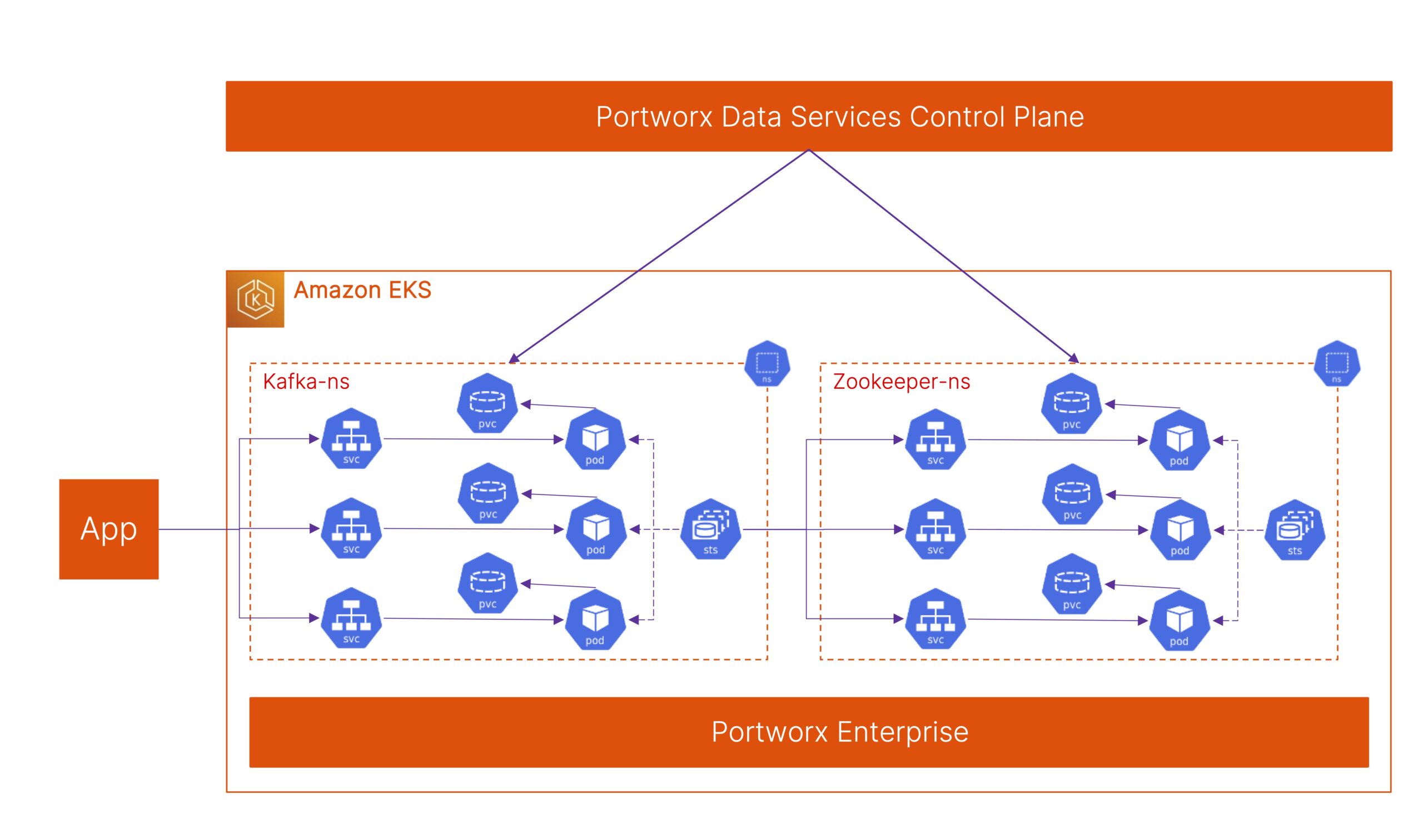
Modern applications built using containers are distributed and loosely coupled in nature, which fits perfectly with the event-driven applications built on Kafka. Running Kafka on Kubernetes allows organizations to use the same orchestration and management layer for their event-streaming platform that they use for their modern applications. Running Kafka on Kubernetes also enables easy deployment, scaling, and upgrades, etc. But choosing the right tool to deploy Kafka on Kubernetes might be a tall task. There are multiple Kubernetes operators—open-source and vendor-supported—or HELM charts that can be leveraged for deploying Kafka on Kubernetes. Each of these options will have its own way of deploying Kafka, performing version upgrades and scale operations, planning for disaster events, etc. This doesn’t even include the steps needed to have a ZooKeeper instance to back the Kafka platform.
ZooKeeper handles the leadership election of Kafka brokers and manages service discovery and keeps track whenever new brokers are added or removed from the cluster. ZooKeeper also helps with topic configuration, maintaining Access Control lists for all topics and managing quotas for each client. Although KIP-500, also known as “Replace ZooKeeper with a Metadata Quorum” was first merged into Kafka version 2.8, it is still considered unsuitable for production for the current 3.2 releases. So, if you are running Apache Kafka in production, the recommendation is to still use ZooKeeper along with Kafka.
Portworx Data Services (PDS) allows organizations to deploy not just Kafka and ZooKeeper, but also modern data services like PostgreSQL, Cassandra, and RabbitMQ on any Kubernetes cluster that’s connected to the PDS control plane. Using PDS, developers can deploy a highly available ZooKeeper instance on their Kubernetes cluster and then use the connection details as part of their Kafka deployment.
For a ZooKeeper deployment, you can follow the standard deployment procedure for PDS and set the following parameters:
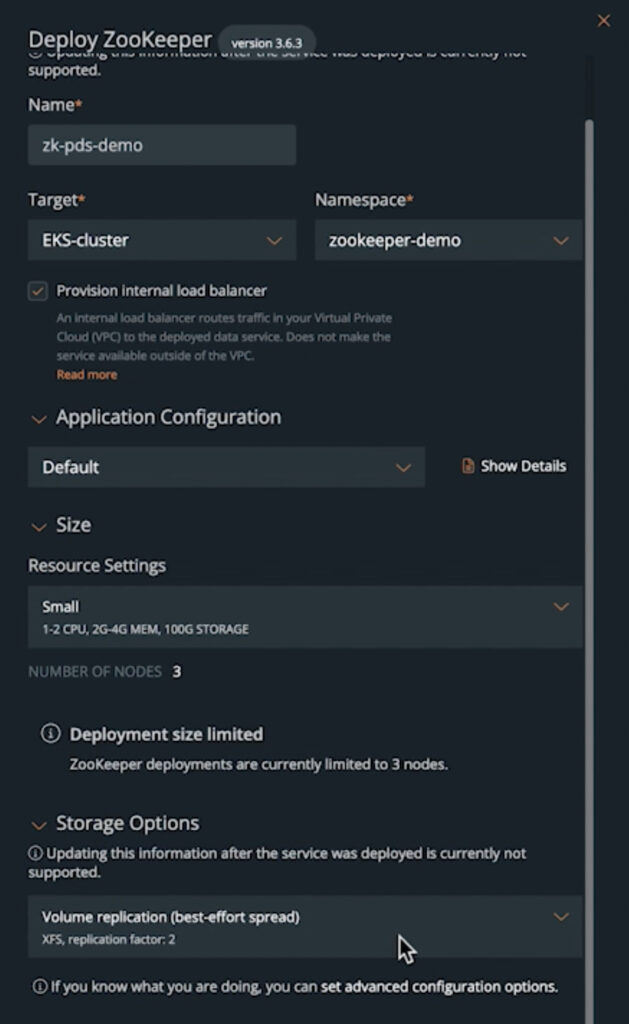
Once you have deployed a ZooKeeper instance, PDS will communicate with the PDS agent running on the Kubernetes cluster and initiate the deployment of the Kubernetes storage class, a StatefulSet object, and the service endpoints needed for the ZooKeeper Custom Resource. Once the deployment is successful, you can fetch the connection details from the PDS dashboard and use these for the Kafka deployment.
For the Kafka deployment, use the same workflow in the PDS dashboard and enter the following details:
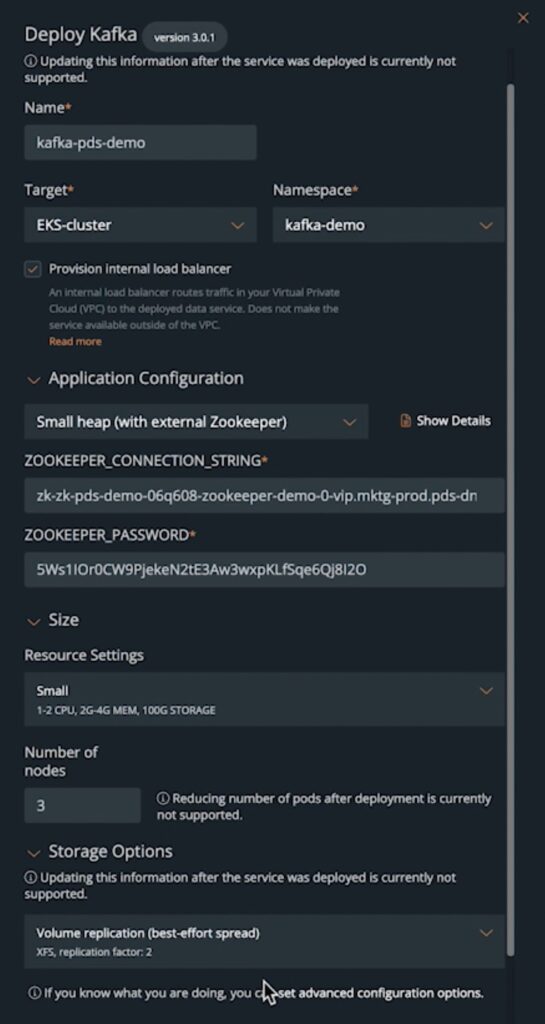
At this point, PDS will initiate the deployment of a Kafka cluster, and once its completed successfully, it will share the connection strings and credentials that you can start using in your application. By default, PDS will create a Kafka cluster called “local”; it uses the SASL PLAIN mechanism for authentication, which allows you to connect to the cluster using a simple username and password that you can fetch from the PDS portal.
If you want to see a demo of a Kafka + ZooKeeper deployment on an Amazon EKS cluster using Portworx Data Services and watch how you can connect to the Kafka cluster and visualize and create topics using the Kafka UI, click on the video below. If you want to learn more about Portworx Data Services, click here!



