



Portworx is the leader in running production stateful services using containers, and we have worked with customers running all kinds of apps in production. One of the most frequent errors we see from our customers are Failed Attach Volume and Failed Mount which can occur when using Azure Disk volumes with Kubernetes.
This post is the latest in a ongoing series about debugging Kubernetes in production. It will focus on Azure Disks on Kubernetes and will show you how to resolve the Failed Attach Volume and Failed Mount warnings as well as showing you how to avoid the issue in the future. We’ve also done a similar post focused on stuck volumes on AWS EBS.
[su_box title=”How Portworx Solves Your Cloud Storage Problems” box_color=”#ff5000″ radius=”5″] [su_row][su_column size=”3/4″ center=”left” class=””]Block storage in the cloud is convenient and easy to provision. But it was designed to provide storage to VMs, not Containers. In highly dynamic Kubernetes environments, this leads to problems such as limited density of volumes per host, and … Read More[/su_column]
[su_column size=”1/4″ center=”right” class=””] [/su_column][/su_row] [/su_box]
[/su_column][/su_row] [/su_box]
As we have mentioned in a previous blogpost, when a 1-to-1 relationship between Azure disks and containers is created, there is a range of problems that might occur:
When there is a problem in one of these areas, is is typical to see errors like the following:
Warning FailedAttachVolume Pod 81 Multi-Attach error for volume "pvc-9e40a1f7-17fa-11e8-a49a-0022480733dc"
Volume is already exclusively attached to one node and can't be attached to another
Warning FailedMount Pod 1 Unable to mount volumes for pod "mysql-app-1465154728-r9cst_ready30(38d2678f-17fb-11e8-a49a-0022480733dc)":
timeout expired waiting for volumes to attach/mount for pod "ready30"/"mysql-app-1465154728-r9cst".
These errors (namely Failed Attach Volume and Failed Mount), are important because attach and mount are the two essential tasks for properly starting up a stateful container that uses an Azure Disk volume.
This post will focus on why these errors occur, the path to solving them and how to avoid the problem happening in the future.
A TLDR of the problem:
When an event occurs that requires a pod to rbe escheduled and the scheduler chooses a different node in the cluster, you will not be able to attach the Persistent Volume to a new host if Azure sees the volume already attached to a existing host
We see 90% of Azure issues using Kubernetes happen because of this issue. Because the Azure Disk volume is still attached to some other (potentially broken) host, it is unable to attach (and therefore mount) on the new host Kubernetes has scheduled the pod onto.
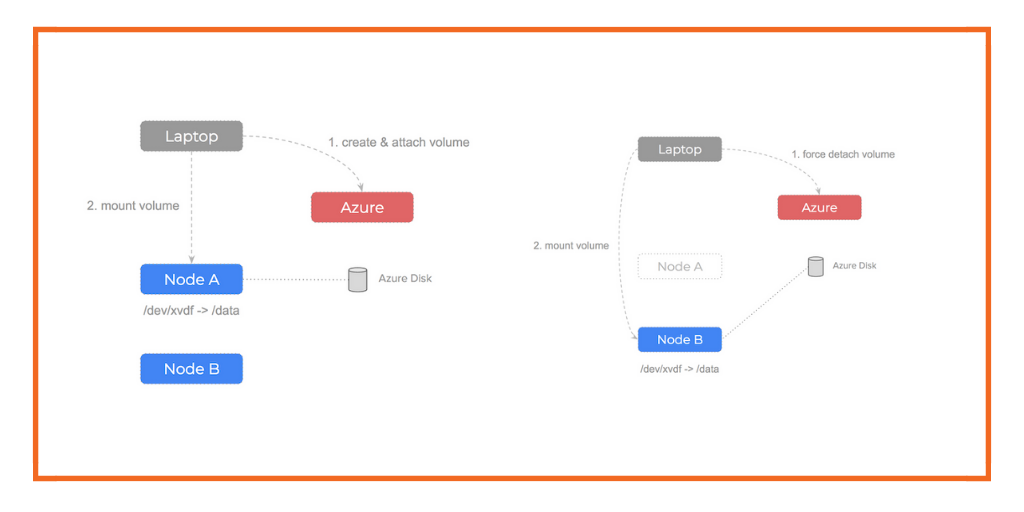
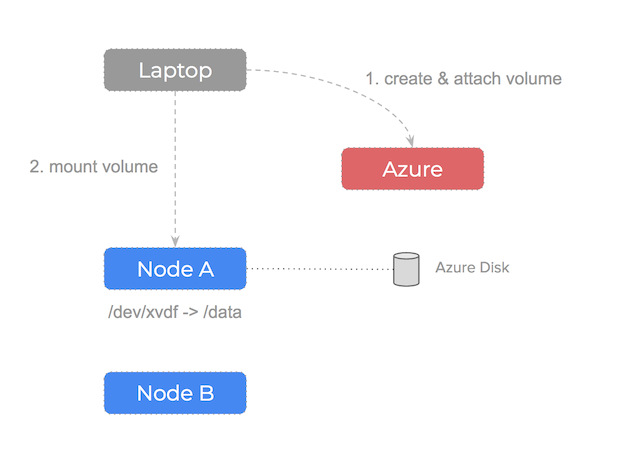
We can trigger this problem manually to confirm it is an underlying issue of how the infrastructure is configured. We can see this by manually creating a disk using the Azure api and then attaching it to one of our compute nodes:
If the node our Azure Disk volume is attached to fails, what would we do? The steps are as follow:
unmount the volume from the failed nodeforce detach the volumeavailable – we are able to attach and mount it to a healthy node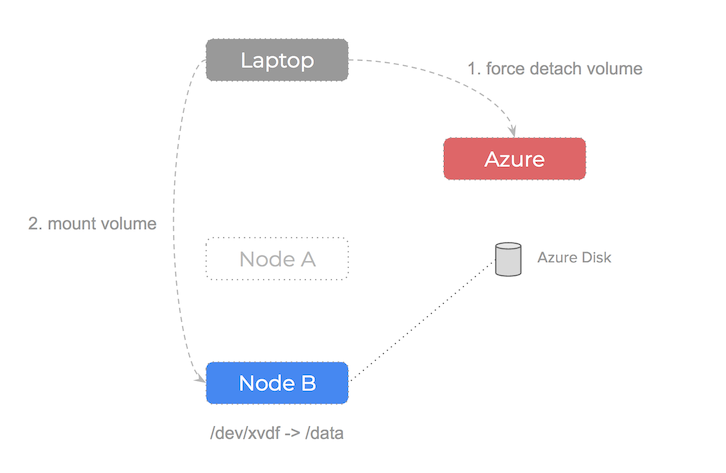
In another blog we demonstrated how Kubernetes consumes persistent storage.
Following this, let’s take a look at some failures that can occur during daily operations when using Azure Disks and Kubernetes – especially focusing on the Warning Failed Attach Volume and Warning Failed Mount errors.
Warning Failed Attach Volume is an error that occurs when an Azure disk volume is unable to be detached from an instance. This means it can no longer be attached to another node and happens because Kubernetes will not force detatch Azure Disk volumes from nodes. The Azure Disk volume must be in the available state in order to be attached to a new node.
Put another way – the Warning Failed Attach Volume is an outcome of a fundamental failure to unmount and detach the volume from the failed node. The message Volume is already exclusively attached to one node and can't be attached to another is a classic symptom of this happening (you will see this message in the output of $ kubectl describe po for the failed pod).
The Kubernetes codebase will produce this error and it is generated when Kubernetes attempts to attach the volume to a node that happens to already be attached to an existing node.
Warning Failed Mount is an error that follows this because the mount operation happens after the attach operation and because the attach has already failed, it means that the Mount operation is not possible.
Again, the Kubernetes codebase can be perused to see where this error is produced.
Various scenarios can occur that can cause these problems:
Each of the links above point to a post that focuses on the specific error case. Each post zooms in on the failure scenario and takes note how using Azure disks on a Kubernetes cluster behaves when it encounters them.
NOTE: each of the tests used Kubernetes version v1.7.9
We are using Kubernetes version v1.7.9 in our tests and we’ve seen that it suffers from the Failed Attach Volume and Failed Mount warnings.
Because Kubernetes will not automatically force detach Azure disks, they become stuck and so can’t be attached to an alternative node.
If you encounter this problem on your Kubernetes cluster, you can resolve it by doing a force detach on the disk using the Azure cli.
Here is an example using Powershell taken from the Azure documentation:
$VirtualMachine = Get-AzureRmVM -ResourceGroupName "RG11" -Name "MyVM07"
Remove-AzureRmVMDataDisk -VM $VirtualMachine -Name "DataDisk3"
Update-AzureRmVM -ResourceGroupName "RG11" -VM $VirtualMachine
This will enable Kubernetes to attach the DataDisk3 to another node because it is now in the available state meaning it is free to be consumed by an alternative node.
Some of the failures we have seen could be avoided if the Kubernetes Azure Disk driver codebase were to be updated. However, the problem is one of low level architecture and is not solved using string and tape-style code patches.
The fact is, Azure disks are not nimble resources and they should not be moving around a Kubernetes cluster being attached to different nodes.
On top of the Failed Attach Volume and Failed Mount errors we have witnessed, the following spurious events can also occur:
A major reason to use SAN based storage is to enable failover without losing data. A downside of this is that we loose performance because the Azure disks are network attached.
If performance is a concern, you could use the super fast, local SSD disks that have a high number of IOPS. However, we cannot use these local disks if we want any kind of failover because they are local and so suffer from a node failure in the same way as the node itself.
An entirely different architectural approach is taken by Portworx. When using Portworx as your Kubernetes storage driver running on Azure, this problem is solved because:
An Azure Disk volume stays attached to a node and will never be moved to another node.
The Azure disk and node are treated as a single resource and if the node fails, the disk is decommissioned and deleted. This is an example of embracing the immutable infrastructure aspect of the cloud native approach to distributed systems.
However, a question remains – how can we ensure no data loss occurs in the event of failover?
Portworx takes an entirely different approach to how it consumes the underlying Azure Disk drive whilst providing failover:
Synchronous block layer replication.
Portworx creates a storage pool from the underlying disks and turns that pool into a cluster wide fabric.
What this means is that containers get virtual slices of the underlying storage pool on demand and we are no longer attaching an entire disk per container
It is able to synchronously replicate the data for each slice to multiple nodes and work alongside the Kubernetes scheduler to ensure containers and data converge efficiently.
With Portworx, Azure Disk drives are created, attached, mounted and formatted once and then join the storage pool. Thousands of containers could be started using the same number of Azure Disk drives because Portworx decouples the underlying storage from the container volumes.
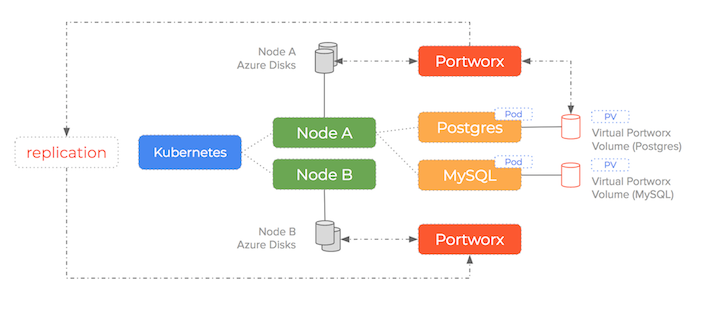
As you can see – Portworx consumes the underlying storage but decouples the actual drives from the volumes it presents to containers. Because the data is synchronously replicated – the failover scenario we saw earlier becomes much simpler (and therefore less error-prone).
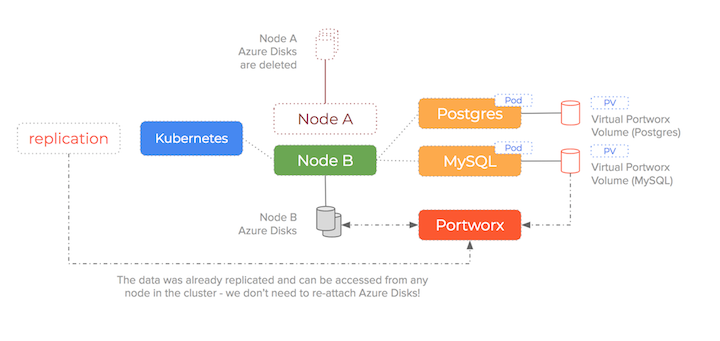
We are no longer enforcing a 1-to-1 relationship between Azure Disks and containers and so the sequence of:
is no longer needed – the target Azure Disk drive is already attached and already has the data!
The advantage of using the Portworx storage layer to decouple our Azure Disk drives from container volumes is that an error-prone and brittle process is eliminated and we avoid any Azure Disks becoming stuck and unable to Attach or Mount to a new node.
Portworx is like a gearbox sat between your underlying Azure Disk drives and the containers that are using volumes from that underlying storage pool.
The alternative is going back to having a single Azure Disk drive per container and thus increasing the risk of encountering the dreaded Failed Attach Volume and Failed Mount errors – as well as having volumes stuck in the Attaching State. We have found (as have our customers) that by employing the fundamentally different architecture of de-coupling storage from containers, failover does not cause the need for manual intervention and you can take advantage of ultra-fast local SSD drives.
Be sure to checkout the other blog-posts in the Azure series:
Take Portworx for a spin today and be sure to checkout the documentation for running Portworx on Kubernetes!


