



Update: If you are trying to resolve Failed Attachvolume or FailedMount errors on Kubernetes, we’ve written a post just about that. Read how to solve Failed Attachvolume and failedMount errors here.
A journey into the world of avoiding EBS volumes stuck in the “Attaching” State.
In order to run a stateful service like Postgres or Cassandra, we will need a storage device of some kind to save our data. If we like to live dangerously – we could use a RAM disk but more likely, we would choose some kind of persistent storage. For instance, we could use local storage but if the node dies we lose all our data.
Instead, many of us decide to use AWS Elastic Block Store, or EBS, the most popular storage system at AWS.
This means that the disk can be attached to a new node even if the old one dies – keeping our data intact. EBS is one of the most common ways to provide storage for Docker, but it is also one that gives the community many headaches. This post will answer the question “how do I use Docker and EBS?” by examining why EBS volumes get stuck so frequently in an attaching state and how you can avoid it for your containerized applications.
Let’s illustrate how using EBS for a dockerized application works in the event of a node failure for two databases we are running on AWS: Postgres and MySQL.
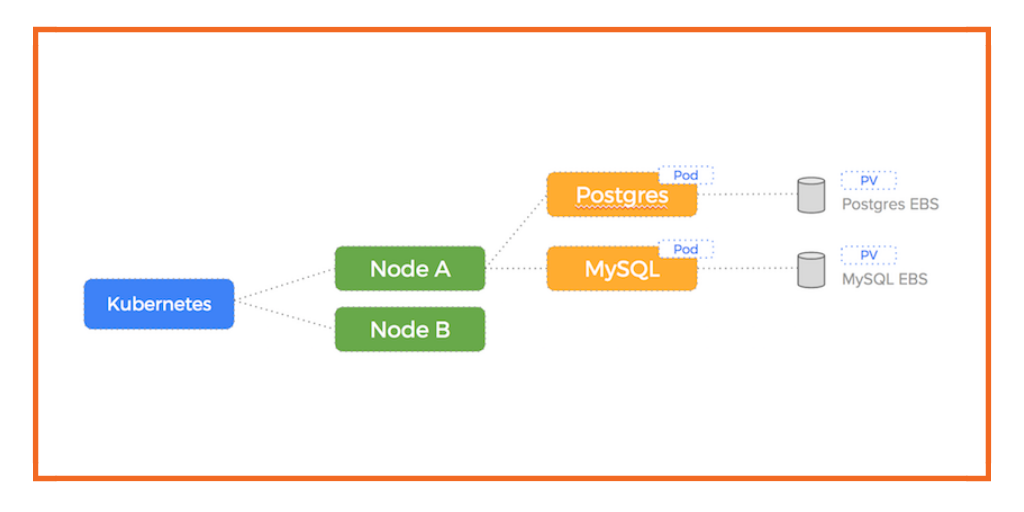
Kubernetes on AWS EC2 with the native EBS driver enables us to create a Persistent Volume and Persistent Volume Claim for our Postgres and MySQL containers which will result in 2 EBS volumes being created (one for each container).
Here is a diagram illustrating our setup before the node failure – our EBS drives are attached to Node A:
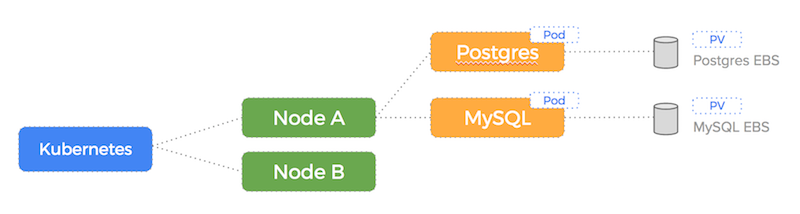
The advantage of this setup using PV Claims is that the EBS drives (with data intact) can be attached to another node in the event of a failure.
The magic of this automation becomes apparent at 4.30AM whilst we are sleeping and the node running the database containers fails.
Kubernetes would do the following:
This process is illustrated by the following diagram:
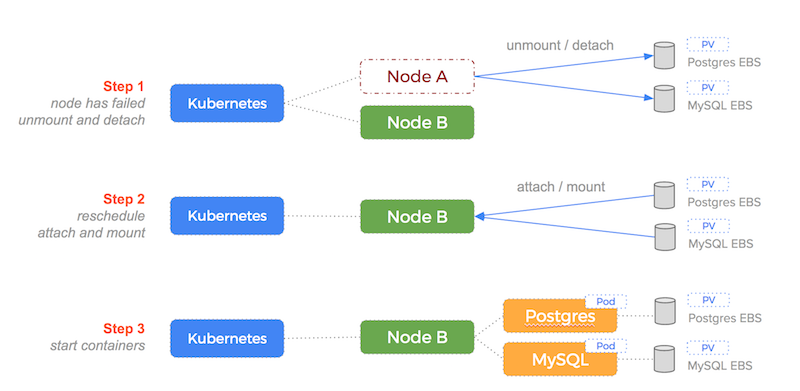
So, to enable failover for our database, we have created a 1-to-1 relationship between the EBS volume and the volume that the Postgres container consumes.
To summarize: if the Postgres or MySQL container moves, the EBS volume “moves” with it. The container and EBS volume constitute a single atomic unit.
Easy peasy.
But….there are problems with this approach. To make our clusters resilient and generally less troublesome – we should always try to reduce risk in everything we do.
Because we are enforcing a 1-to-1 relationship between our EBS drives and containers (so we get automatic failover) – it triggers the following error-prone sequence of events, every time the container moves:
Each of these steps requires a combination of either an API call to the AWS servers and/or running commands as root on a node.
There are a variety of problems that can occur when doing this:
A cursory google search for stuck ebs volumes reveals many souls lost to this problem:
The reality is that EBS drives (or any other type of network attached storage) are not nimble, numerous resources as far as the Linux kernel is concerned.
Attempting to treat them as such increases our exposure to risk and means at some point soon, we’ll be visiting one of the troubleshooting pages from Google.
Besides the stuck EBS volume problem, there are other issues stemming from having 1 container volume per EBS volume:
Portworx takes a different approach – it pools the underlying EBS drives into data layer. This means containers get virtual slices of the underlying storage pool on demand. It is able to replicate data to multiple nodes and work alongside the Kubernetes scheduler to ensure containers and data converge efficiently.
With Portworx, EBS drives are created, attached, mounted and formatted once and then join the storage pool. Thousands of containers could be started using the same number of EBS drives because Portworx decouples the underlying storage from the container volumes. With EBS, you are limited to at most 40 volumes per host, no matter how large the host is, whereas with Portworx, you can run many hundreds of containers per host, each with their own volume. Containers are supposed to be lightweight so we can densely pack them, but the 1-to-1 EBS mapping breaks that model.
From AWS docs Important – Attaching more than 40 volumes to a Linux instance is supported on a best effort basis only and is not guaranteed.
Here is an illustration of how the EBS drives are consumed when using the Portworx native Kubernetes Volume Driver:
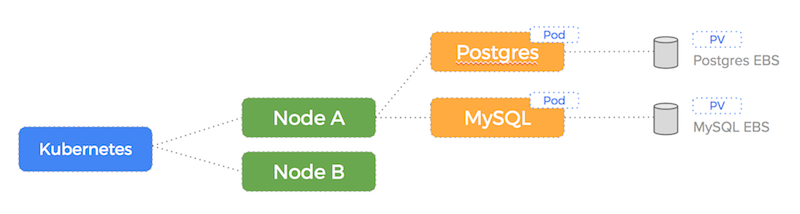
As you can see – Portworx consumes the underlying storage but decouples the actual drives from the volumes it presents to containers.
Because the data is replicated – the failover scenario we saw earlier becomes much simpler (and therefore less error-prone).
Using a Portworx volume – Kubernetes would do the following:
Here is an illustration of how Kubernetes handles failover when using a Portworx volume:
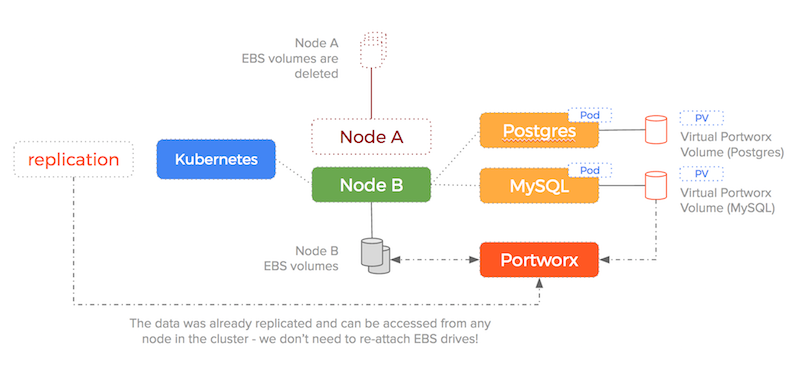
We are no longer enforcing a 1-to-1 relationship between EBS drives and containers and so the sequence of:
is no longer needed – the target EBS drive is already attached and already has the data!
Imagine we have 3 nodes each with 2 EBS volumes:
We would start the Portworx agent – adding both /dev/xvdf and /dev/xvdg to the storage pool.
This gives us a total storage capacity of 3 x 100GB + 3 x 50GB = 450GB across our 3 node cluster.
It is a heterogeneous pool consisting of 2 types of storage. The EBS drives are attached once – the virtual container volumes are created from these underlying block devices as often as it needed for the number of containers running on the host.
Using pxctl (the command line tool to control a Portworx storage cluster) or (or the CLI of our scheduler or choice) – we can create volumes from the underlying storage offered by our EBS volumes.
Here is an example creating a 10GB volume for our postgres database that has triple replication and can be viewed from any node in the cluster:
$ pxctl volume create \
--size 10G \ # a 10GB disk
--repl 3 \ # replicate the data 3 times
--shared \ # this means the volume can be viewed from any node in the cluster
--io_priority high \ # control the class of storage used - EBS drives with provisioned iops can be used here
--fs ext4 \ # what filesystem is presented to the container - this can be different per container
postgres-production-volume
We can then use the Kubernetes Volume Driver to create a Persistent Volume:
apiVersion: v1
kind: PersistentVolume
metadata:
name: postgres-production-volume
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
portworxVolume:
volumeID: "postgres-production-volume"
fsType: "ext4"
We then create a Persistent Volume Claim:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc0001
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
And finally run our Postgres pod that will use this claim:
apiVersion: v1
kind: Pod
metadata:
name: postgres
spec:
containers:
- name: postgres
image: postgres
volumeMounts:
- name: postgres-prod
mountPath: /var/lib/postgres/data
volumes:
- name: postgres-prod
persistentVolumeClaim:
claimName: pvc0001
To summarize, the key to using EBS with Docker is:
So we can see the advantage of using the Portworx storage layer to decouple our EBS drives from container volumes. We remove an error-prone and brittle process and get out of any stuck EBS problems we were having.
Think of Portworx like a gearbox sitting between your underlying EBS drives and containers using volumes from that underlying storage pool.
Without that de-coupling mechanism, we are back to having a single EBS drive per container and if we are running a large number of stateful containers that is risky.
One important thing to note is that the stuck EBS drive issue will happen with any storage driver that relies on a one-to-one mapping of of EBS volumes to container volumes, including the native EBS volume plugin for Docker or Kubernetes, or connectors like Flocker and RexRay. While these solutions seem simple, the fragility of AWS EBS means that you will certainly be restarting hosts and waiting for block devices to mount a lot once you are at any type of scale.
Like what you read? Learn more about Docker storage, Kubernetes storage and DC/OS storage.


