Debugging Errors in Kubernetes on Azure: Node Failure
This is a micro-blog that is part of a series of posts regarding common errors that can occur when running Kubernetes on Azure.
Being the leader in cloud native storage containers, Portworx have worked with customers running all kinds of apps in production. One of the most frequent errors we see from our customers are Failed Attach Volume and Failed Mount which can occur when using Azure Disk volumes with Kubernetes.
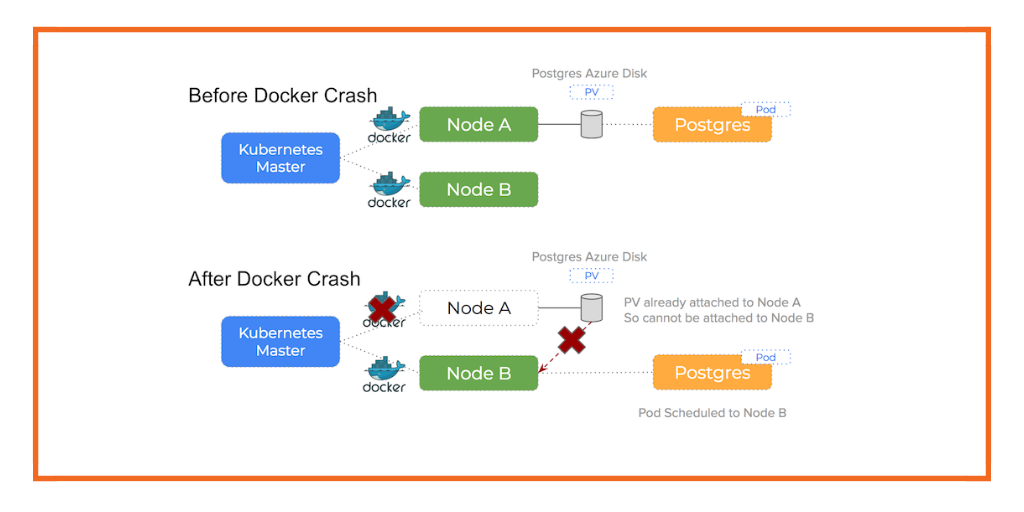
This post zooms in on errors that can happen when a node in your cluster fails. In this case, the Kubernetes master can no longer assert the health of the node and the pod will be re-scheduled to another node which can result in Failed Attach Volume and Failed Mount warnings.
Node failure
We tested how k8s deals with an Azure node going away so we can learn how to avoid downtime that can occur when we have a kernel panic or other disaster (such as a power cut). These errors are hard to simulate so we used the Azure console to delete the node and watched what happened. In this special case of node failure, K8s responds properly because Azure does a force detach because we are in effect giving it warning that the node is no longer is use. However, that is not a real world scenario since most often, Azure doesn’t get such a warning and doesn’t force detach a block device..
Hence, there is an interesting outcome when running our node failure test. As mentioned, we used the Azure console to delete the node once the pod was scheduled to it and this triggers the following actions:
- power down and remove the Azure VM instance
- perform a detach operation on any disks that were attached to the VM
It’s an important fact to consider that the way in which we simulated a node failure is not representative of a real-world use case.
If you consider the following statement it becomes apparent what is happening:
By using the Azure GUI to delete the node, we are giving Azure pre-warning that the node is no longer in use meaning it is safe to perform an force detach operation on any attached disks
This is not representative of a real-world failure case where any of the following events lead to the node failure:
- power cut
- kernel panic
- reboot
Each of these failure modes don’t provide Azure with permission to force-detach the disks because it was not an intentional action and so Azure would not perform the force detach operation that is needed to free the disk and allow it to be moved.
Considering the following statement and the reasoning why force-detach is not a good idea unless absolutely sure becomes clear:
Force detach on an otherwise healthy node could lead to data corruption if the pod is actively making writes to the disk
When it comes to production disks, it is always better to be cautious!
By deleting the node using the Azure console – we are marking each of the Azure disks as available which in turn allows the Kubernetes controller to proceed and attach it to the new node.
You can see how this happens in the following diagram:
Error Output
Let’s study the output of the Kubernetes event log once the node has been deleted:
Normal SuccessfulMountVolume kubelet, k8s-agent-24653059-0
MountVolume.SetUp succeeded for volume "pvc-7559c82f-27f5-11e8-bbb9-0022480128db"
Warning FailedMount attachdetach AttachVolume.Attach failed for volume "pvc-7559c82f-27f5-11e8-bbb9-0022480128db" :
failed to get azure instance id for node "k8s-agent-24653059-0"
Normal Scheduled default-scheduler
Successfully assigned mysql-app-1467715154-mj0vg to k8s-agent-24653059-1
Normal SuccessfulMountVolume kubelet, k8s-agent-24653059-1
MountVolume.SetUp succeeded for volume "pvc-7559c82f-27f5-11e8-bbb9-0022480128db"
What this indicates:
- the volume is initially mounted successfully to
k8s-agent-24653059-0 - we then use the Azure console to delete the VM instance
k8s-agent-24653059-0 - in the background – Azure has force detached the volume leaving it in the available state
- the
Warning Failed Mounterror confirms that Kubernetes can no longer see thek8s-agent-24653059-0node - Kubernetes subsequently schedules the pod to
k8s-agent-24653059-1 - finally – the volume is mounted to
k8s-agent-24653059-1because it is available thus the mount operation is successful
These logs confirm our theory that a delete node operation performed using the Azure console is not indicative of an actual node failure and is actually the same as:
- force detach the disk from
k8s-agent-24653059-0 - re-schedule the pod to
k8s-agent-24653059-1 - attach and mount the disk to
k8s-agent-24653059-1
This sequence is the same as the sequence of commands we would have to apply if unpicking this problem manually.
Portworx and cloud native storage
To understand how Portworx can help you to avoid these problems – please read the main blog-post.
In summary:
An entirely different architectural approach is taken by Portworx. When using Portworx as your Kubernetes storage driver running on Azure, this problem is solved because:
An Azure Disk volume stays attached to a node and will never be moved to another node.
Conclusion
Again, make sure you read the parent blog-post to understand how Portworx can help you to avoid these errors.
Also – checkout the other blog-posts in the Azure series:
- Docker daemon crashed or stopped
- Update affinity settings or node cordon, forcing a reschedule
- A network partition occurred
Take Portworx for a spin today and be sure to checkout the documentation for running Portworx on Kubernetes!
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Kai Davenport
Kai has worked on internet-based systems since 1998 and currently spends his time using Kubernetes, Docker and other container tools and programming in Node.js and Go.
Debugging Errors in Kubernetes on Azure: Forcing a Reschedule, Cordoning a Node and Updating Affinity Settings