



This is a micro-blog that is part of a series of posts regarding common Errors that can occur when running Kubernetes on Azure.
Being the leader in cloud native storage for containers, Portworx has worked with customers running all kinds of apps in production. One of the most frequent errors we see from our customers are Failed Attach Volume and Failed Mount which can occur when using Azure Disk volumes with Kubernetes.
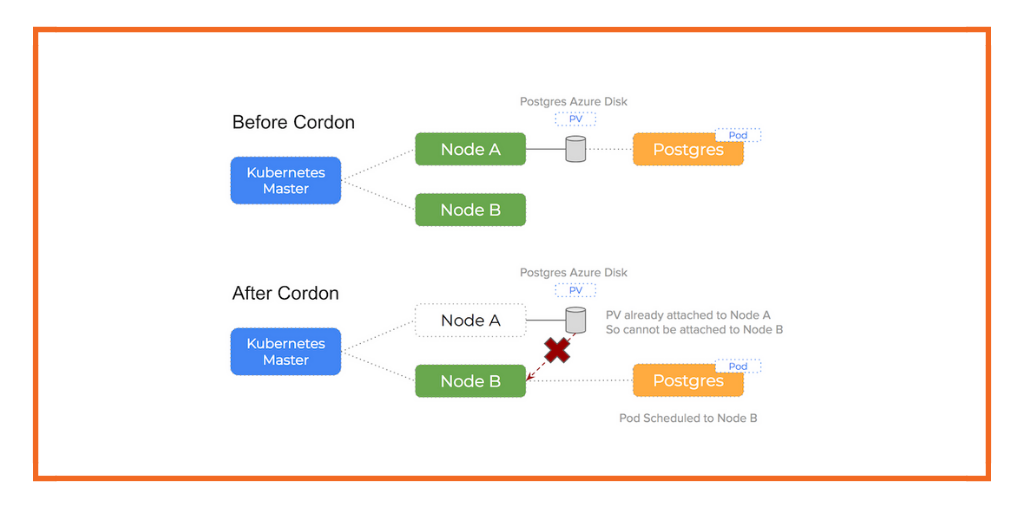
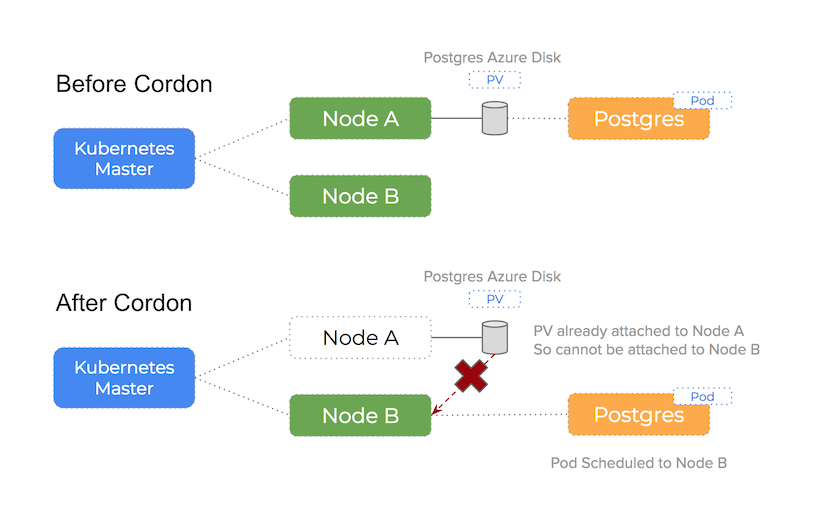
This post zooms in on errors that can happen when updating the node affinity settings for a pod or when a node is cordoned. In summary: When an event occurs that requires a pod to rescheduled and the scheduler chooses a different node in the cluster, you will not be able to attach the Persistent Volume to a new host if Azure sees the volume already attached to a existing host.
A fundamental feature of Kubernetes is to constrain pods to certain nodes. This is often done with affinity, nodeSelectors and cordoning.
This is known as affinity and gives a powerful way to identify nodes with certain properties that your pods should be scheduled onto. An example of this is when you have nodes with high powered CPU and large amounts of RAM that are suitable for running database servers that need a performant in-memory cache.
One way of implementing node affinity is to use nodeSelectors – this uses a key-value pair that are attributed to a node and a selector for the pod that will match those nodes based on the key-values you have chosen.
Here is an example of labelling a node with a key-value pair that identifies it as a high-powered machine:
$ kubectl label nodes kubernetes-foo-node-1.c.a-robinson.internal spec=high
If you added a selector using spec=high in your pod spec, Kubernetes will schedule the pod onto a node matching that selector when making scheduling decisions.
The important thing to realise is that if you update the selector in your pod spec, Kubernetes will trigger a re-scheduling event because it has to find a new node that is suitable. In other words – your pods are constantly scheduled onto nodes that fit the nodeSelector criteria.
Another type of nodeSelector is used by the cordon command which essentially disables the scheduling of pods to that node. It’s another way of saying readyForPods={true,false} and is commonly used when maintenance is required for that node and you don’t want any pods to be running on it whilst the maintenance is underway.
In both examples – by changing these values, Kubernetes will trigger a scheduling decision that will assign the pod to another node.
RollingUpdate – where we update a node selector in the pod manifest which in turn triggers a re-schedule to another nodeCordon – a native Kubernetes command (kubectl cordon $NODE) which is used to drain pods from that nodeYou can see how this works in the following diagram:
A TLDR of the problem:
When an event occurs that requires a pod to rescheduled and the scheduler chooses a different node in the cluster, you will not be able to attach the Persistent Volume to a new host if Azure sees the volume already attached to a existing host
We see 90% of Azure issues using Kubernetes happen because of this issue. Because the Azure Disk volume is still attached to some other (potentially broken) host, it is unable to attach (and therefore mount) on the new host Kubernetes has scheduled the pod onto.
An example of the error output when running those operations on a pod:
Warning FailedAttachVolume Pod 31 Multi-Attach error for volume "pvc-8263e685-27cb-11e8-8ccc-0022480745ca"
Volume is already exclusively attached to one node and can't be attached to another
Warning FailedMount Pod 1 Unable to mount volumes for pod "mysql-app-1314707785-zsqm3_ready30rollingupdate(fa38d4cb-27cb-11e8-8ccc-0022480745ca)":
timeout expired waiting for volumes to attach/mount for pod "ready30rollingupdate"/"mysql-app-1314707785-zsqm3". list of unattached/unmounted volumes=[mysql-vol-undefined]
Warning FailedSync Pod 1 Error syncing pod
To understand how Portworx can help you to avoid these problems – please read the main blog-post.
In summary:
An entirely different architectural approach is taken by Portworx. When using Portworx as your Kubernetes storage driver running on Azure, this problem is solved because:
An Azure Disk volume stays attached to a node and will never be moved to another node.
Again, make sure you read the parent blog-post to understand how Portworx can help you to avoid these errors.
Also – checkout the other blog-posts in the Azure series:
Take Portworx for a spin today and be sure to checkout the documentation for running Portworx on Kubernetes!


