According to the Data on Kubernetes 2022 research report, 84% of the respondents have increased their productivity by running data workloads on Kubernetes. And, if we look closer, 76% of the respondents are running databases on Kubernetes, while 67% are running analytics workloads on Kubernetes.
To serve this growing ecosystem better, Portworx announced general availability for Portworx Data Services—the industry’s first database platform as a service offering—earlier this year. Portworx Data Services, or PDS, allows developers to deploy any supported data service (including databases, messaging queues, etc.) on any Kubernetes cluster running on-prem or in the public cloud, using either the PDS UI or a complete set of REST APIs. Developers can select their target Kubernetes cluster, their database version, and the number of nodes they want in their database cluster, and PDS will orchestrate the deployment of the database on their target Kubernetes cluster. PDS uses a set of best practices that Portworx has built over the years while delivering the gold standard Kubernetes storage and data management platform.
In this blog, we will look at the top 10 tips for running databases on Kubernetes and then demonstrate how PDS can help you customize your data service deployments on your Kubernetes clusters.
Tips for Running Databases on Kubernetes
If you are planning to run databases on Kubernetes, here are a few tips that can help you get started. If you are already actively running them on Kubernetes, these tips will help you optimize your database deployments.
Use Kubernetes Operators. Kubernetes Operators are software site reliability engineers (SREs) that can help you automate Day 0 deployment and simplify Day 2 operations for your databases running on Kubernetes. Learning how to deploy databases manually on Kubernetes and then worrying about performing Day 2 operations—like scale up/out, data protection, upgrades, etc.—introduces a lot of operational overhead inside your organization and does not truly unlock the value of using Kubernetes. By leveraging Kubernetes Operators, users can utilize constructs—like Custom Resource Definitions (CRDs) and the resulting Custom Resource (CRs)—to simplify database deployments on Kubernetes.
Configure for high availability. Configuring your databases for high availability is critical, especially when running on Kubernetes. Unlike bare metal database deployments, where your physical servers rarely go offline, pods on Kubernetes can be rescheduled or respawned on different nodes in the Kubernetes clusters. If you only have a single pod for your database deployment, you might experience downtime when running on Kubernetes. Using Kubernetes Operators, you can use parameters in YAML files to enable high availability. These operators will automatically deploy multiple copies of your pod without any manual overhead. But, in addition to high availability at the database layer (e.g., multiple nodes in a Cassandra cluster or a primary–read replica PostgreSQL cluster), you should also plan for replication at the storage layer. This ensures that you have a volume replica available on different nodes in your Kubernetes cluster, which allows you to remove any data resynchronization tasks in case a node (pod) in your database cluster fails.
Configure resource requests and limits. Kubernetes allows users to configure CPU and memory requests and limits. Doing this guarantees minimum resources to each node (pod) in your database cluster and enforces a maximum limit to the number of resources a specific node can consume. This is to ensure that no application or database running on the same cluster is starved for resources just because you have a noisy neighbor sharing resources on your cluster. In addition to CPU and memory requests and limits, Portworx also allows you to set IOPS or bandwidth limits for your Kubernetes PersistentVolumes, which helps you enforce limits to the amount of storage resources a database can consume. Later in this blog, we will look at how Portworx Data Services allows you to create Resource Setting Templates to ensure your developers are using requests and limits when they deploy databases on Kubernetes clusters.
Use anti-affinity rules. If you have configured high availability for your database deployment, you also need to use anti-affinity rules to ensure that you aren’t running all three nodes of your database cluster on the same Kubernetes worker node. A solution like Portworx allows you to leverage Volume Placement Strategies to ensure your database pods and volumes are spread across different nodes in your cluster—which means that a single worker node going offline won’t bring your entire database down.
Tune your databases. Even after you are running databases on Kubernetes, you will still need to tune them—just like you did when you ran them on virtual machines or bare metal nodes. You will still need to configure your database indexes, see how views are configured, etc. Later in the blog, we will look at how Portworx Data Services allows you to use Application Configuration Templates to fine-tune your databases on Kubernetes.
Scale up/scale out. Whenever you need more performance or capacity from your database deployment, you have to decide what is the best way to scale your database. NoSQL distributed databases like Cassandra allow you to scale out horizontally and add more nodes in your Cassandra cluster, and these nodes can start performing both read and write operations. But, in databases like MySQL, if you perform a scale out operation, you might just be adding more read replicas without doing anything to improve your write performance. In such scenarios, a scale up operation, where you add more resources to your primary node, will help you improve your write performance. Learn more about scaling up vs scaling out by checking out this blog.
Configure pod disruption budgets. Kubernetes allows you to configure pod disruption budgets (PDBs) for objects like StatefulSets, Deployments, and ReplicaSets. PDBs allow you to configure the minimum number of available nodes or the maximum number of unavailable nodes when you are performing updates to your database deployments. Portworx Data Services automatically configures PDBs to ensure that your database performance or uptime isn’t impacted when you are making in-place upgrades.
Secure your databases. Ensuring that your database endpoints aren’t publicly available and following the principle of least privilege are probably the two most important things you can do to secure your database deployments. Using Kubernetes constructs like Network Policies and Secrets to ensure that access to your database is restricted and secured is the way to go. In addition to ensuring secure access to your database, you should also keep track of common variabilities and exposures (CVEs) for the database images that you use inside your organization. You can do this manually and monitor for CVEs using an open source tool like Trivy, or you can rely on a solution like Portworx Data Services, which ensures you are only using images from a curated catalog of images. Vendors like Portworx run scans to catch vulnerabilities and patch up the images in the catalog whenever needed, ensuring you can run databases on Kubernetes securely.
Use encryption. Following up on the topic of security, you should always try to use encryption at rest and in transit. There are Kubernetes Operators—some open-source and some enterprise—that offer you the ability to encrypt your data at rest. But, instead of figuring out which operators support encryption and which ones do not, you can just use Portworx as the Kubernetes storage layer where you can enforce encryption at a cluster-wide level.
Enable backups. Data protection is critical for any application or database that is running in production. You cannot rely on database clustering alone to protect you from outages. You need to ensure that you have a local or a remote backup of your database so you can recover from scenarios like accidental deletions, data corruption, etc. PDS makes enabling scheduled backups on Day 0 or Day 2—or taking ad-hoc backups anytime—easy.
At this point in the blog, you should have the ammunition you need to start running databases on Kubernetes manually. But, if you want to learn more about how Portworx Data Services allows Database Administrators or DevOps Admins to use the different configuration options to make sure your developers are using these best practices during deployment, keep reading.
Portworx Data Services offers the simplest experience to developers who just want to run databases on Kubernetes using a connection string, without learning anything about Operators or how to configure Kubernetes StorageClasses or pod disruption budgets. But, for administrators who want to customize database deployments, PDS offers the following constructs:
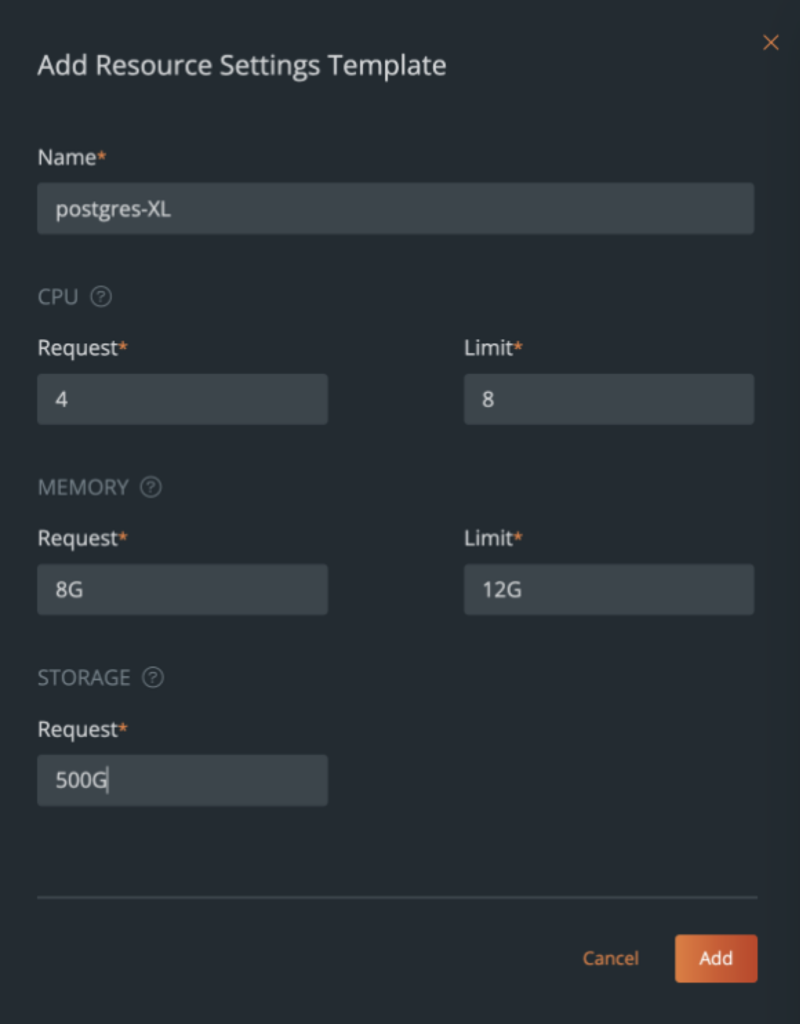
Resource Setting Templates: These templates allow administrators to configure the pod requests and limits for CPU and memory and configure the size of the PersistentVolume that gets deployed for each database node (Kubernetes pod) in your cluster. You can either choose to create a new Resource Setting Template from scratch or copy one of our existing templates as a starting point and build on it.
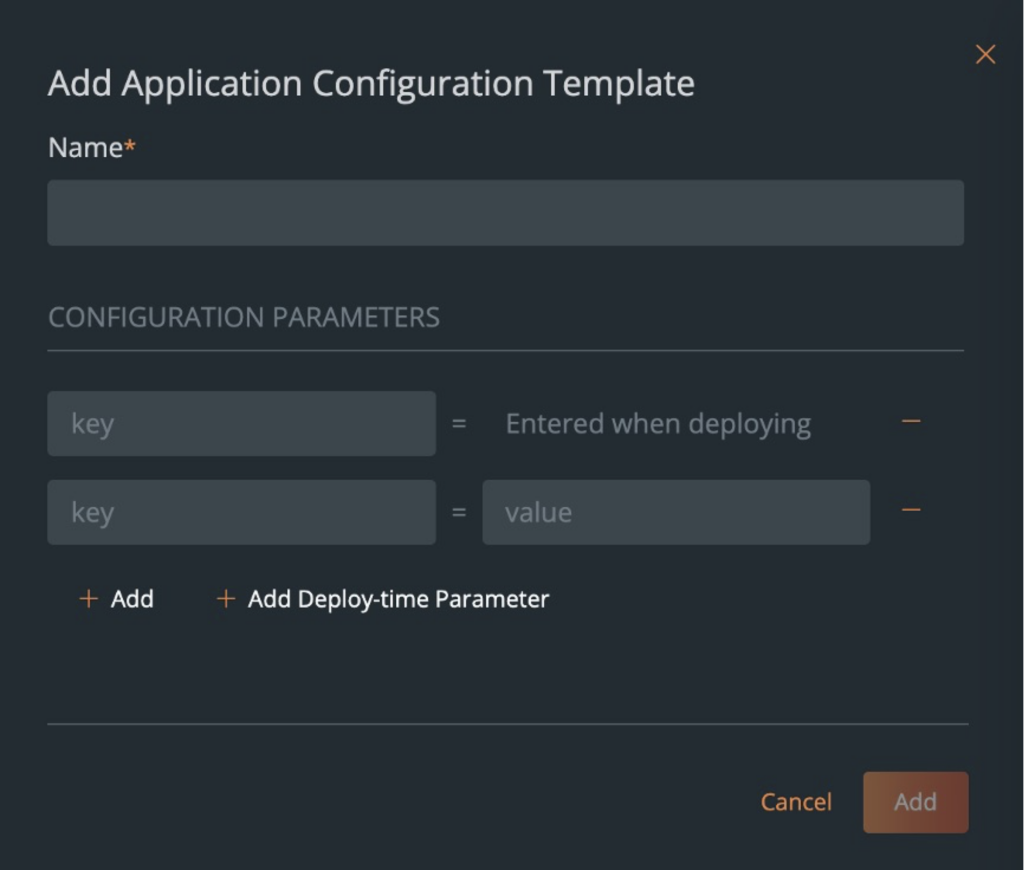
Application Configuration Templates – These templates allow administrators to change the configuration parameter that are used during database deployment. These parameters are configured as key:value pairs, and the administrator can either choose to specify both the key and value inside the template, or just specify a key and allow the developer to enter a value for the key as a deploy-time parameter. This allows administrators to run the database being deployed on Kubernetes using PDS. Below are a few examples of things you can configure in an App configuration template:
Postgres – PG_DATABASE, PG_USER, PG_PRIMARY_PORT, etc.
Cassandra – CASSANDRA_DC, CASSANDRA_RACK, etc.
Kafka – DEFAULT_REPLICATION_FACTOR, BROKER_RACK, etc.
RabbitMQ – HOSTNAME, CLUSTERED, DEFAULT_VHOST, etc.
ZooKeeper – INIT_LIMIT, SYNC_LIMIT, etc.
If you want a full list of all the environment variables, you can check out our documentation site.
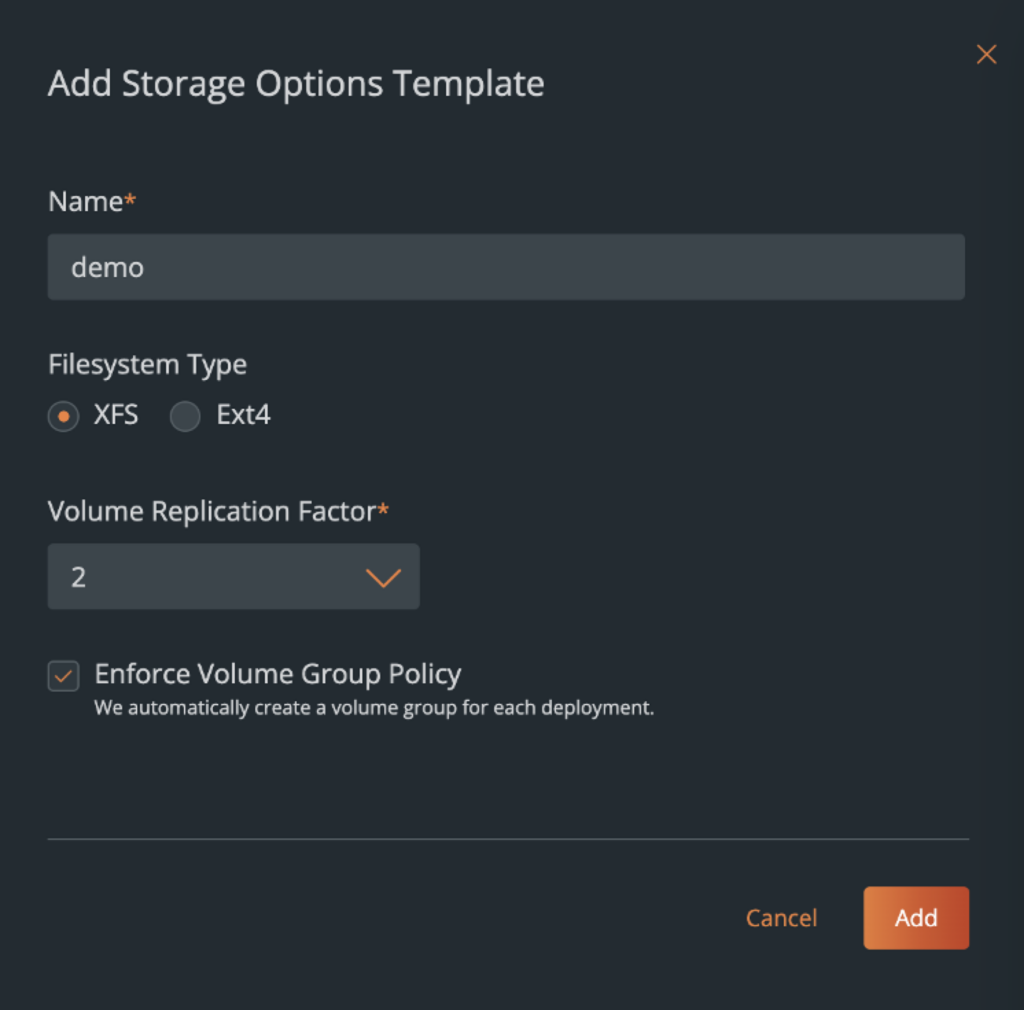
Storage Options – PDS abstracts away a lot of best practices at the Kubernetes storage, but still allows administrators to control a few things when it comes to the type of storage configured for databases. Using Storage Options, Administrators can select the type of file system (XFS + EXT4) for your databases, the replication factor at the storage layer for additional high availability, and whether you want to enforce anti-affinity for your database nodes.
Volume Group Policy will fail a database deployment, if you check forced spread, and PDS can’t orchestrate all the database nodes across your Kubernetes cluster. Or if you select Best Effort spread, it will try it’s best to enforce anti-affinity, but if it can’t, it will continue with the database deployment. So, based on your organizational requirements, you can customize your storage options.
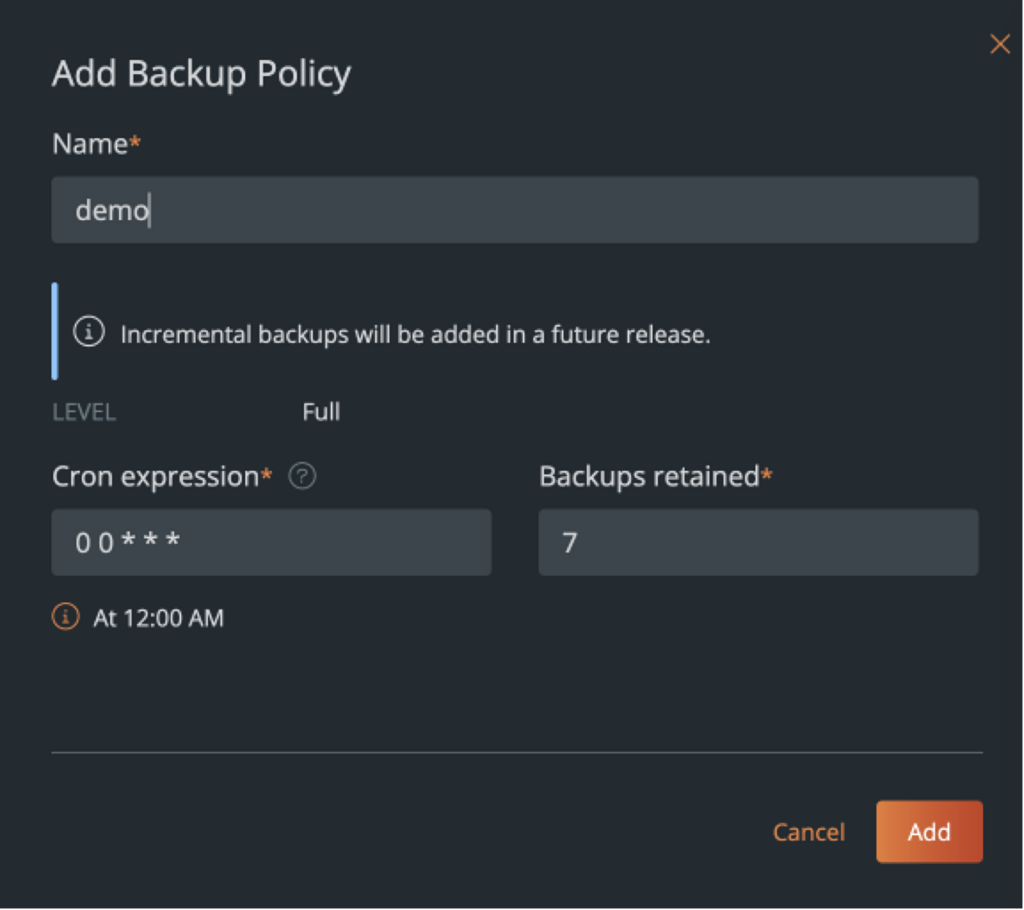
Backups – As we discussed in the top 10 tips for running databases on Kubernetes, backups are absolutely essential for mission critical applications running in production. PDS allows administrators to add backup locations and configure backup schedules. Adding backup locations in different geographies, ensures that organizations are always compliant with local regulations and aren’t storing backups outside a region.
Backup locations are basically an S3 or S3-compatible object bucket that can be used to store your database snapshots. These can be in AWS, Azure, Google Cloud, or any other S3-compatible solution that you might be using.
Backup Schedules allows you to configure a cron-job based schedule that can be selected from a drop-down list by your developers when they want to enable scheduled backups for their databases. This reduces the operational overhead, where the administrators must go back and enable backups for each database that might be deployed in their organization.
PDS allows developers to enable scheduled backups during deployment or after the fact, and it also allows developers to take an ad-hoc backup using the UI or a set of REST APIs if they want to.
Summary
As we saw in the Data on Kubernetes research report 2022, running Databases on Kubernetes can be valuable, as it helps increase your developer productivity, and also helps increase your revenue gains. But, you need to be careful when running Databases on Kubernetes. Not following best practices, might lead to unplanned consequences, which might result in data breaches or application outages. Using a solution like Portworx Data Services helps you worry less about building and operating your database platform inside your organization, and allows you to spend more time building differentiators for your business.
If you want to see a demo of how PDS can help you customize your database deployments on Kubernetes, watch the youtube video below: