



The debate between scale up vs scale out has intensified over the last few years as applications must adapt to unprecedented demands from AI workloads, microservices, database services, and a globally distributed user base. Applications initially deployed with modest resources encounter performance bottlenecks as usage intensifies and implementing an appropriate scaling mechanism – vertical (up) or horizontal (out) becomes imperative.
In Kubernetes, a Pod is an abstraction that represents a group of one or more application containers. In this article, we will discuss two ways to scale your application pods and help you determine which approach works best for different scenarios.
Scaling up (or vertical scaling) is adding more resources—like CPU, memory, and disk—to increase compute power and storage capacity. This approach applies to traditional applications deployed on physical servers or virtual machines as well as containerized applications.
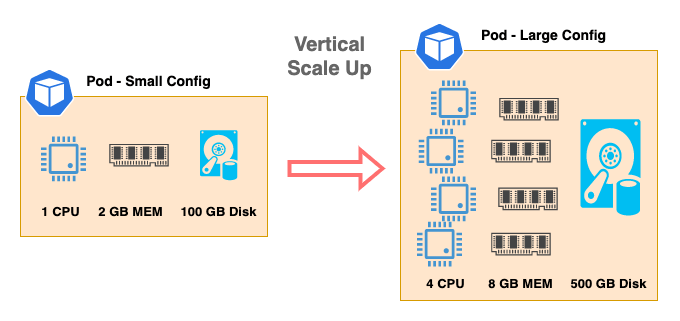
The diagram above shows an application pod that begins with a small configuration with 1 CPU, 2 GB of memory, and 100 GB of disk space and scales vertically to large configurations with 4 CPU, 8 GB of memory, and 500 GB of disk space. Now with more computing resources and storage space, this application can process and serve more requests from clients.
Scaling up suits applications that need to scale to a reasonable size, particularly for database services with intensive memory or processing requirements.
Advantages of Scaling Up
Disadvantages of Scaling Up
With physical hardware limitations, scaling up vertically is a rather short-term solution if your application needs to continue growing.
Scaling out (or horizontal scaling) addresses many limitations of the scale up method. With horizontal scaling, the compute resource limitations from physical hardware are no longer a challenge. You can use any reasonably sized server as long as the server has enough resources to run the pods. This approach works particularly well for software as a service applications with distributed architecture.
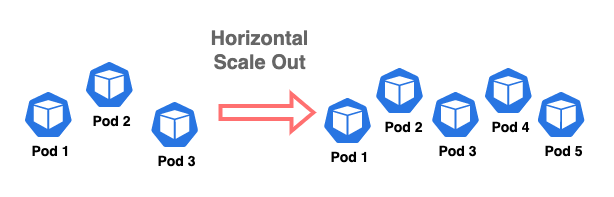
The diagram above shows an example of an application pod with three replicas scaling out to five replicas, and this is how Kubernetes normally manages application workloads in a Kubernetes cluster.
Advantages of Scaling Out
Disadvantages of Scaling Out
Stateless applications do not store data in the application, so they can be used as short-term workers. Kubernetes manages stateless applications very well through horizontal scaling mechanisms.
In Kubernetes, a HorizontalPodAutoscaler automatically updates a workload resource, such as a Deployment, to adjust the number of pods based on the actual demand. This means if the load of application pods increases, the HorizontalPodAutoscaler keeps increasing the number of pods until the load comes back to the normal range.
If the load decreases and the number of pods is above the configured minimum, the HorizontalPodAutoscaler instructs the Deployment to scale back down, conserving resources.
How this works:
Kubernetes implements horizontal pod autoscaling as a control loop that runs intermittently. The interval is set by the –horizontal-pod-autoscaler-sync-period parameter to the kube-controller-manager, with a default interval of 15 seconds.
For more information about Kubernetes HorizontalPodAutoscaler, see the official Kubernetes documentation.
Unlike stateless applications, stateful applications such as databases need to store data in persistent volumes. This makes it more difficult for Kubernetes to manage stateful applications. The storage layer itself is complex and requires careful planning when designing a scalable architecture.
For some stateful applications, you may be able to configure Kubernetes’ HorizontalPodAutoscaler to automate scale out operations, but once data is written, scaling back down becomes difficult without additional orchestration.
For example, when a database grows and storage capacity usage increases, you need to scale up or expand the persistent volume. This operation is usually performed separately from scaling up the compute resources (CPU and memory). The following sections focus on specific approaches for scaling both up and out for stateful database pods in Kubernetes environments.
Understanding the fundamental differences between scaling up and scaling out helps organizations make informed infrastructure decisions. Each method offers distinct advantages and challenges across several critical dimensions.
When comparing scale up and scale out approaches, performance differs significantly. Scale up solutions add more resources to a single system, which can provide faster processing for applications that benefit from shared memory access. Many traditional database systems perform better with vertical scaling because they can leverage larger memory pools without network latency. However,distributed databases are specifically designed for horizontal scaling.
Scale out solutions distribute workloads across multiple systems, which is ideal for applications that can process data in parallel. Web servers and stateless applications typically perform better with horizontal scaling because they can handle more concurrent requests.
The performance ceiling for the scale up approach is limited by the hardware capabilities of single servers, while scale out can continue expanding performance by adding more nodes. However, scale out systems often introduce network overhead that can impact latency-sensitive operations.
Scale up typically involves higher upfront costs for enterprise-grade hardware but requires less complex management. As you add more resources to a single system, the cost per unit of performance often increases non-linearly. This happens because premium, high-capacity components cost disproportionately more than their standard counterparts due to manufacturing complexity, lower production volumes, and vendor pricing strategies. For example, high-density memory configurations or specialized GPU options often command premium pricing tiers. This creates diminishing returns that architects must carefully evaluate against business requirements and budget constraints.`
Scale out architectures often allow for more gradual spending as you incrementally add commodity hardware. This approach can result in better overall cost efficiency, especially for large deployments. Additionally, scale out architectures can utilize cheaper hardware components, though they require more networking equipment and physical space.
Operating costs also differ. Scale up systems typically consume more power per unit but require less cooling infrastructure and simpler maintenance operations. Scale out deployments offer better resilience, potentially reducing downtime costs, but introduce soft costs for patching, upgrades, and managing numerous distributed nodes.
Scale up architectures require robust single-system infrastructure with redundant power supplies, cooling systems, and component-level failover. These systems need fewer rack spaces but demand more power and cooling per unit.
Scale out deployments spread across multiple physical machines, creating inherent redundancy. They require a more comprehensive networking infrastructure and load-balancing solutions to handle inter-node communication. Network bandwidth and latency become critical factors in scale out performance.
Maintenance windows differ significantly between approaches. Scale up often requires complete system downtime for hardware upgrades, while scale out allows for rolling updates that maintain service availability. However, rolling updates across many smaller nodes can extend maintenance operations significantly compared to fewer larger nodes, potentially creating longer vulnerability windows during upgrades.
Scale out provides flexibility for adapting to changing workloads. Adding or removing nodes can happen without causing system-wide failure, though removing nodes redistributes workload to remaining nodes, which must handle the sustained demand. This allows for dynamic capacity adjustments that match infrastructure to actual requirements. Scale up solutions offer simplicity but less agility. Upgrading a vertically scaled system often requires downtime and has physical limits that eventually necessitate a platform change.
Scale out architectures offer better adaptability for unpredictable workloads. They can expand during peak demand periods and contract during quiet periods like low traffic windows, optimizing resource usage. This makes horizontal scaling particularly suited for applications with variable usage patterns.
Major cloud providers have developed comprehensive solutions for both scaling approaches.
Cloud providers provide auto-scaling features, which distribute workloads across many virtual machines depending on performance metrics, or custom rules and schedules. These systems work seamlessly with load balancing technologies to efficiently distribute traffic across resources. Most platforms offer capabilities such as health checks and automated instance replacement to ensure system reliability and resilience.
Cloud platforms offer a variety of virtual machine sizes for resource-intensive workloads, ranging from low-cost solutions to memory- or compute-optimized configurations. Many providers allow for resource adjustments with minimum downtime, while some modifications may require instance restarts. Some providers offer custom machine types that allow for precise CPU and memory capabilities specification, decreasing waste caused by overprovisioning.
Modern cloud infrastructure includes orchestration tools that simplify the management of scalable applications. These tools address many complex challenges traditionally associated with distributed systems through automation and intelligent resource allocation.
Managed Kubernetes services in cloud environments handle much of the scaling complexity using features like:
These capabilities allow applications to scale horizontally and vertically with minimal configuration, allowing developers to focus on application logic rather than infrastructure management.
Horizontal Scaling: Web applications, stateless microservices, containerized workloads, and distributed processing systems
Vertical Scaling: Traditional databases, monolithic applications, memory-intensive analytics, and certain AI/ML workloads
These industry solutions have developed orchestration tools that simplify the management of scaled applications, addressing the complexity challenge traditionally associated with distributed systems. The following sections will explore practical tutorials for implementing these scaling strategies in real-world scenarios.
When you use relational databases like MySQL or PostgreSQL, you can create multiple nodes of database pods to form a cluster to increase high availability and scale the performance. For example, when you create a 3-node cluster of MySQL, one of the nodes is the primary node that accepts read and write requests. Two other nodes are called read replicas, and they only serve the read requests. Since you can only write to the primary node, data consistency can be maintained in the cluster.
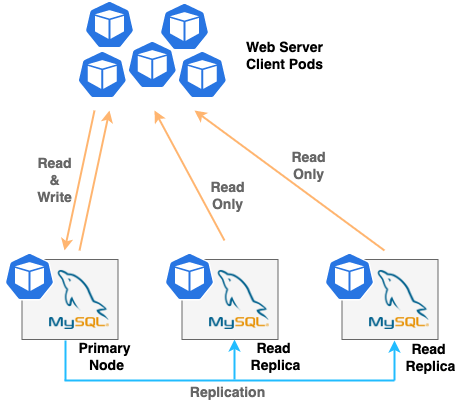
If the demand for read requests increases and write requests stay the same, then you can scale out your database by adding more read replica pods to the cluster. However, if the write requests increase, adding more read replica pods will not help since you can only write to the primary node. In this case, it is much simpler just to scale up your database pod by adding more compute resources. There is a way—called “sharding”—to split a database instance into multiple instances when the database gets too large, but this introduces another level of complexity into the cluster architecture.
If you are using a NoSQL distributed database like Cassandra, you can easily scale out horizontally to meet your demand. Every Cassandra node can perform read and write operations, and this makes a Cassandra cluster a masterless, or peer-to-peer, architecture. In other words, distributed databases are made to scale very large.
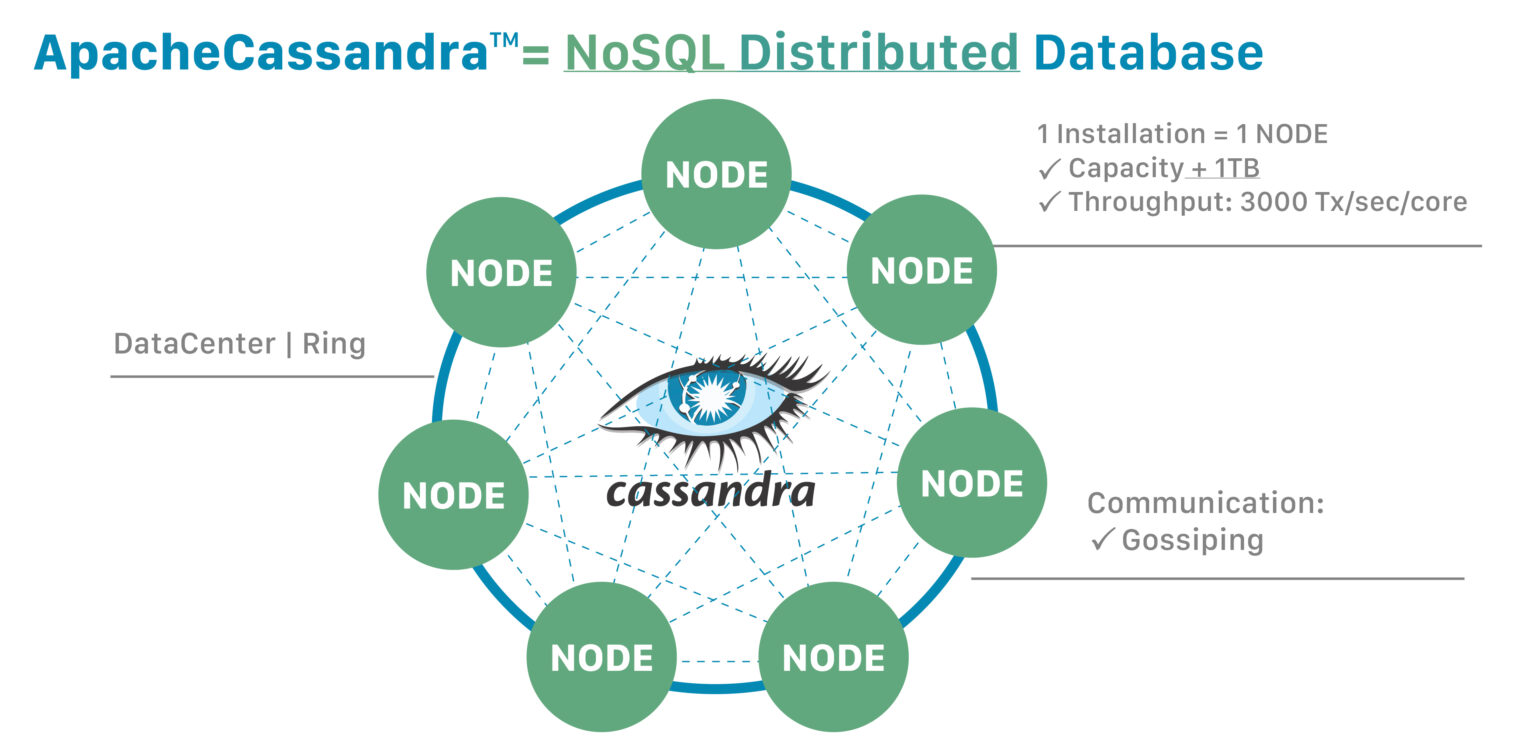
Since Kubernetes usually scales out applications horizontally, Cassandra and other distributed databases are well suited to Kubernetes environments. Adding the pods can increase an application’s TPS (transactions per second) performance and database size linearly.
Refer to the Cassandra documentation for more information.
Portworx Data Services (PDS) allows organizations to accelerate data deployment on Kubernetes by deploying modern data services like PostgreSQL, Cassandra, Redis, Kafka, MySQL, Zookeeper, and RabbitMQ on any Kubernetes cluster that is registered to the PDS control plane. Using PDS, developers and DevOps administrators can deploy a highly available database instance on their Kubernetes cluster. PDS also automates Day-2 operations on your data services layer, such as scale up, scale out, backup, and in-place upgrade.
Understanding the differences between scale up and scale out approaches helps you design more resilient and cost-effective infrastructure. Each strategy serves different needs and comes with unique trade-offs that impact performance, cost, and operational complexity.
For modern applications, especially those running in Kubernetes environments, a hybrid approach often works best. Stateless components typically benefit from horizontal scaling, while certain databases and memory-intensive workloads may perform better with vertical scaling.
Kubernetes can effectively manage stateless applications using the horizontal scale, but stateful applications like databases require more careful planning due to persistent storage requirements. Tools like Portworx Data Services and scale-out object storage simplify this complexity, allowing you to scale both up and out with minimal effort.
By choosing the right scaling strategy for each component of your application, you can optimize resource usage, improve performance, and enhance resilience while controlling costs.
| Characteristic | Scale Up (Vertical) | Scale Out (Horizontal) |
| Definition | Adding more resources to existing nodes | Adding more nodes to the system |
| Best for | Memory-intensive workloads, monolithic applications, certain RDBMS | Web servers, distributed systems, microservices, stateless applications |
| Cost model | Higher upfront costs, premium hardware | Gradual investment, commodity hardware |
| Implementation complexity | Simpler implementation | More complex networking and orchestration |
| Scalability ceiling | Limited by single server capabilities | Theoretically unlimited |
| Resilience | Single point of failure risk | Better fault tolerance |
| Kubernetes support | Supports resource requests/limits adjustment, VPA | Native HPA, cluster autoscaling |
Expanding your knowledge of scaling architectures helps build more resilient and efficient systems. The following resources provide detailed guidance for implementing effective scaling strategies across different environments.
For practical implementation guidance, the Cloud Native Computing Foundation provides resources on scaling containerized applications within Kubernetes environments, focusing on best practices that apply across multiple cloud providers.
Want to learn more about how to effectively implement scaling strategies for your applications? Explore our additional resources on scale up vs scale out architecture or contact our sales team to discover how Portworx can help you build scalable, resilient infrastructure for your critical applications.



