



Today we are excited to announce the release of STORK (STorage Orchestrator Runtime for Kubernetes). STORK is an open source project that takes advantage of the extensibility of Kubernetes to allow DevOps teams to run stateful applications like databases, queues and key-value stores more efficiently on Kubernetes. STORK has been implemented to communicate with storage drivers through a plugin interface, so it can be extended to work with any storage driver for Kubernetes, not just Portworx. Contributions to STORK are welcome and encouraged from the Kubernetes community.
STORK allows stateful applications to take advantage of scheduler extenders in order to enjoy the benefits of storage-aware scheduling via Kubernetes in production at scale. Using a scheduler extender, STORK provides hyperconvergence, failure-domain awareness, storage health monitoring and snapshot-lifecycle features for stateful applications on Kubernetes. STORK was developed in collaboration with customers running large scale stateful applications in production in order to address operational issues inherent to data services.
Instructions to install Stork with Portworx can be found here.
Stork v1.0 has three major features intended to make running stateful applications in production on Kubernetes bulletproof.
Read on to learn more about STORK and how you can get involved.
Modern stateful applications like Cassandra, Kafka, ElasticSearch and more scale out to increase capacity and perform best when each instance runs in close proximity to its data. Having local direct storage access reduces latency and improves the response times of these databases. For this reason, it is ideal to schedule a pod on a host where its data is located. Today, DevOps teams have to use techniques such as labels, constraints or affinity/anti-affinity to ensure data locality. These rules are hard to manage when running applications at scale across a large number of servers and data centers, increasing room for error.
The reason for this is that since the Kubernetes volume plugin infrastructure has been written with generic concepts to work with all kinds of Kubernetes storage solutions – SANs, cloud storage (like AWS and GCE) as well as cloud-native storage – it does not support primitives which can be used to optimize location of pods. For example, when using iSCSI LUNs for persisting data in pods, how would the Kubernetes scheduler decide which node to use for optimized access to the data? For such iSCSI LUNs, the node where the pod gets scheduled does not make a difference since there will always be at least one network hop (which adds latency) from the Kubernetes cluster to the SAN. Similarly for cloud storage like EBS, there isn’t much information available for Kubernetes to decide which EC2 instance would have better performance when accessing EBS disks.
To get around these issues, you could use labels to indicate which nodes have data for a Persistent Volume Claim (PVC) and then use that label in affinity rules for your application.
While this strategy works to a certain degree, it does bring up a couple of issues:
Working with customers running stateful services on Kubernetes in production, we saw all of these limitations with labels. That is why we created Stork and are agree to expand it with the help of the Kubernetes community.
Stork overcomes these by implementing a Kubernetes scheduler extender which can be used to influence pod scheduling based on the location of volumes that a pod requires. The advantage of implementing Stork as an extender is that you do not need to update Stork everytime you upgrade your Kubernetes cluster since the extender defines an interface which will remain the same across versions.
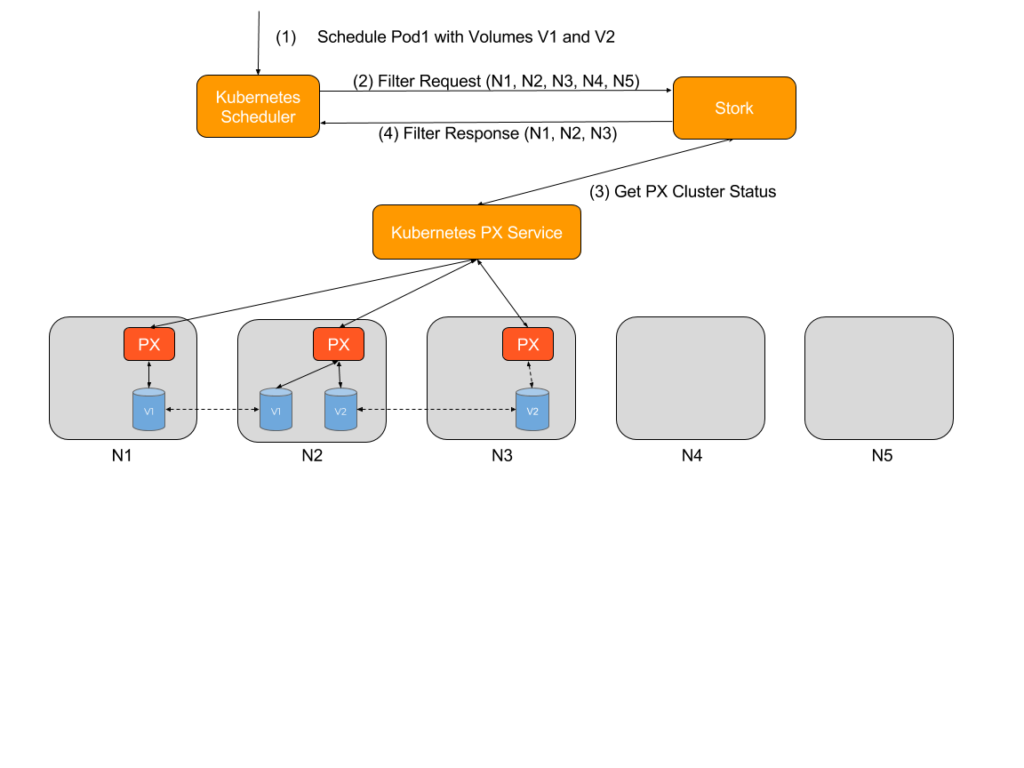
When a Kubernetes scheduler is configured to use an extender, two REST API calls are made by the scheduler before every scheduling decision: Filter and Prioritize
Stork uses the Filter request to filter out nodes where the storage driver is not running or is in error state. Kubernetes does not have this information natively so it might actually try to (unsuccessfully) attach and mount volumes on a node where a storage driver is not running. So this helps reduce the number of failed attempts by the scheduler and therefore results in pods getting scheduled faster.
For example, consider a five node cluster with nodes named N1,N2,N3,N4 and N5, where Portworx is installed on N1,N2 and N3. A user asks the scheduler to start a pod (P1) using two volumes V1 and V2 (both with a replication factor of 2), where V1 is located on nodes N1 and N2, and V2 is located on nodes N2 and N3. For the filter request, Stork will filter out nodes N4 and N5 since Portworx is either not installed on those nodes or is offline.
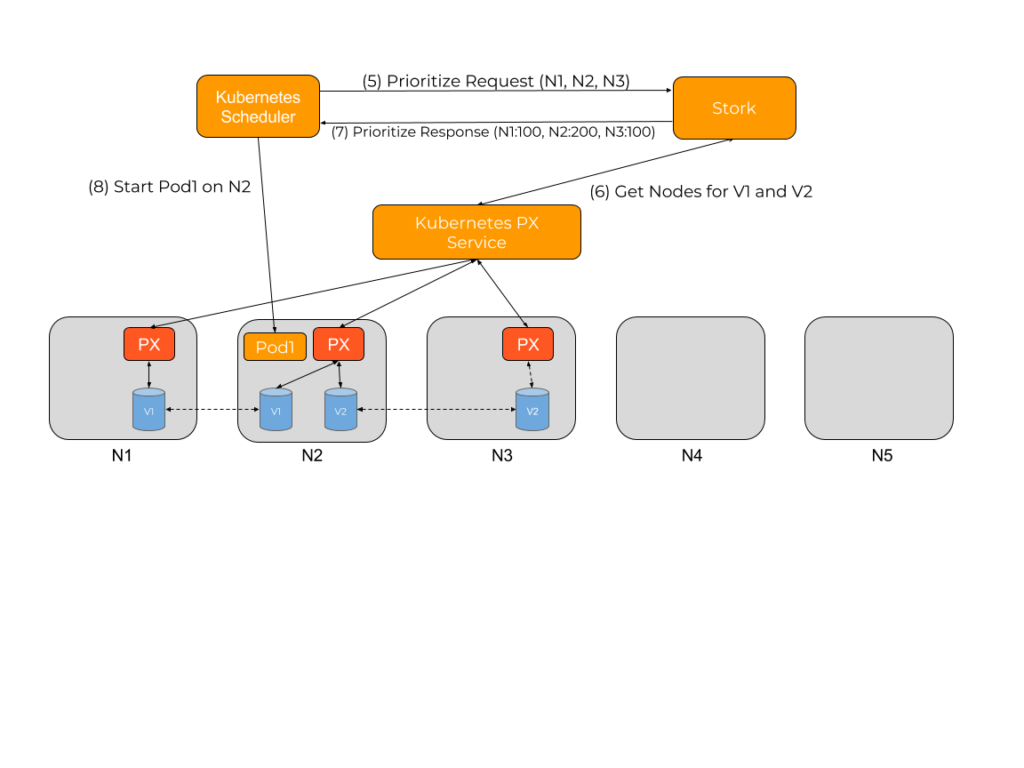
When Stork receives the Prioritize request, it checks which PVCs are being used by that pod, then queries the storage driver for the location of the pod’s data. Stork then uses this information to stack rank the various nodes based on which node would provide the best performance when accessing persistent storage from that pod.
In this case the following scores would be allocated by Stork:
N2 gets the highest score because it has copies for two of the volumes and can provide the best performance for the pod. Stork would use this prioritized list to reply to the scheduler asking it to prefer N2 followed by either N1 or N3.
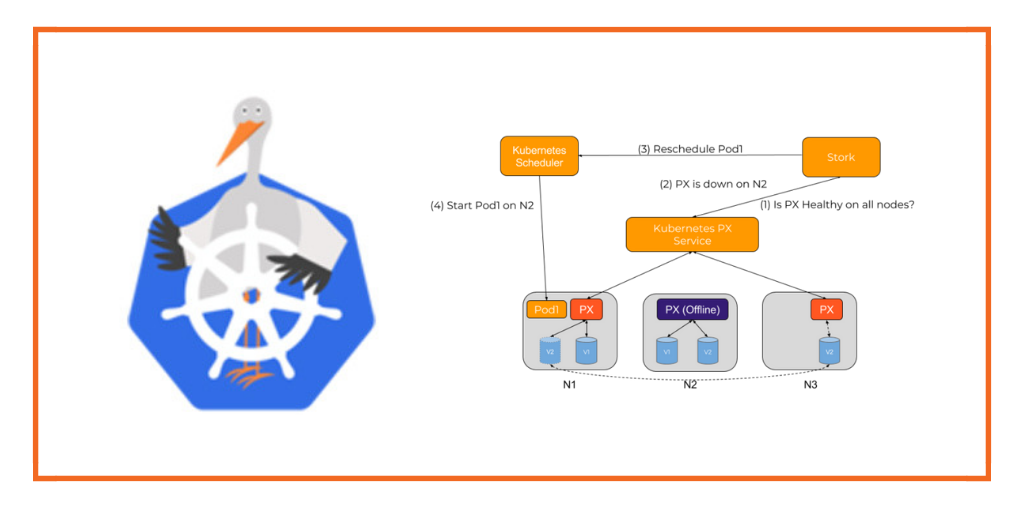
A common issue with stateful applications is the wear and tear induced by the storage fabric. The overall health of a pod will be subject to this wear and tear over time. This can result in pods not being able to be rescheduled to healthy hosts if a storage driver experiences a failure, resulting in application unavailability.
For example, consider a pod that has been started with a volume provisioned and mounted by a storage driver. If at this point the storage driver hits an error condition, the health checks for the application could continue to be successful even though it can not read or write to its persistent store. At the same time, the volume being used by the pod could have another replica available on the cluster allowing it to be able to function properly.
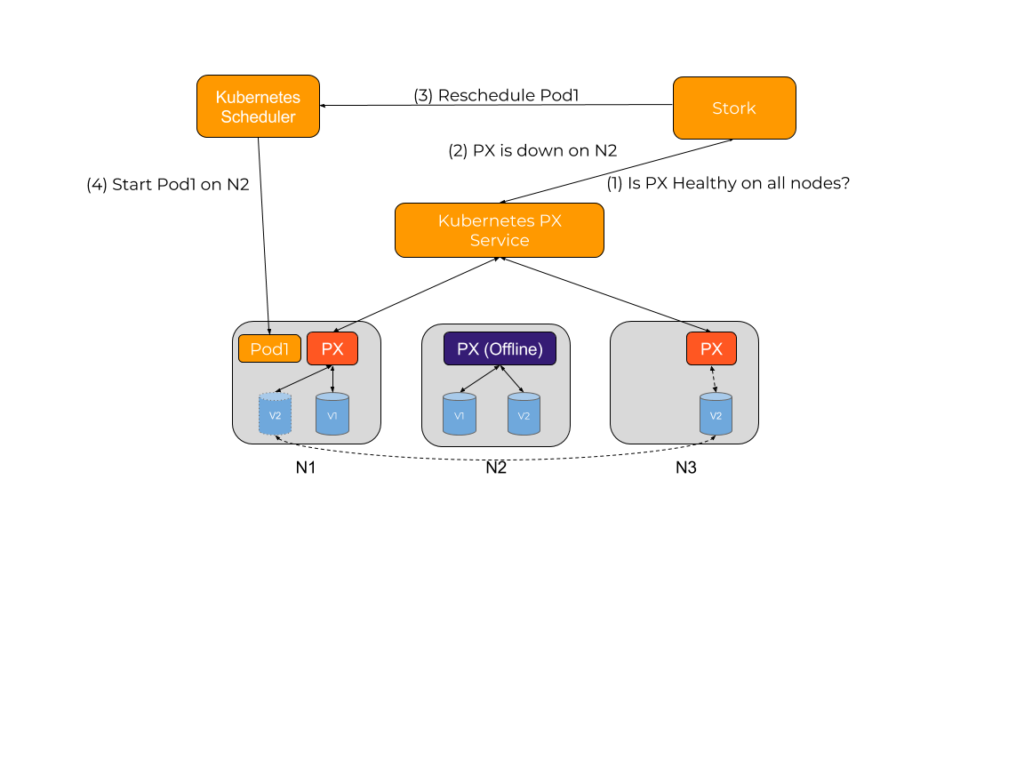
Stork helps in these cases by failing over pods when the storage driver on a node goes into an error or unavailable state. This allows your applications to be truly Highly Available without any user intervention.
Stateful applications have a complex life cycle that needs to be managed. Snapshots provide a key management tool for data recovery or duplication of an environment for testing. Today, DevOps teams have to manage these life cycle operations using the tools provided by the storage provider instead of directly through Kubernetes, reducing the automation benefits of the Kubernetes platform for complex data workflows like DR, testing, upgrades, and blue-green deployments.
STORK adds support for orchestrating volume snapshots through Kubernetes. This allows users to take snapshots of PVCs and then restore those snapshots to other PVCs all through Kubernetes. This allows users to automate complex data workflows, all through Kubernetes.
For example if you have a PVC called mysql-data which has been provisioned by Portworx, you can create a snapshot for the PVC by applying the following spec:
apiVersion: volumesnapshot.external-storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: mysql-snapshot
namespace: default
spec:
persistentVolumeClaimName: mysql-data
You can then check the status of the snapshots using kubectl:
$ kubectl get volumesnapshot,volumesnapshotdatas
NAME AGE
volumesnapshots/mysql-snapshot 6s
NAME AGE
volumesnapshotdatas/k8s-volume-snapshot-179503e6-f979-11e7-971d-627221250ade 4s
You can then create PVCs from this snapshot by using the snapshot name and the stork-snapshot-sc storageclass.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-snap-clone
annotations:
snapshot.alpha.kubernetes.io/snapshot: mysql-snapshot
spec:
accessModes:
- ReadWriteOnce
storageClassName: stork-snapshot-sc
resources:
requests:
storage: 2Gi
Once you apply the above spec you should see a PVC created from the snapshot by Stork.
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql-data Bound pvc-d8959cf1-f978-11e7-9319-0214683e8447 2Gi RWO px-mysql-sc 5m
mysql-snap-clone Bound pvc-853f549b-f979-11e7-9319-0214683e8447 2Gi RWO stork-snapshot-sc 56s
You can see a demo of the snapshot feature in action below.
Stork has been implemented so that it is easy to add support for other storage drivers. If you’re interested in adding a storage driver to Stork, get involved here.
Now that we have laid the foundation for the this framework we will continue expanding on it. Some of the features that we are planning to add in the next release include support for availability zones so that the prioritization of nodes will take into account the zone and rack that data is located on. We will also add support for taking backups to the cloud using the same interface as snapshots.
We also welcome suggestions on any new features that users and the community would like to see in future releases.


