




This post explores the concepts used by Kubernetes to manage storage for stateful containers. It is part of a new series on debugging Kubernetes in production. After reading this post, you will be able to answer the question “How do I use Kubernetes storage?”.
With the news at Dockercon EU Copenhagen that Kubernetes support is officially coming to the Docker toolkit, Kubernetes Volumes are becoming the canonical way to manage storage for containers in production.
Kubernetes manages these volumes and containers using a collection of metadata to describe what our intended system should be.
The metadata is essentially our desired state – Kubernetes will constantly converge to this state. This means you only ever need to think what you want to have running and leave the harder question of what do I need to change to get there up to Kubernetes.
The metadata is created in the form of manifests which are small YAML documents each with a focus on a specific type of object. The important objects for running stateful containers are:
Before we move on to discuss controllers and kubelets – let’s take a look at each of these object types:
Kubernetes represents the entities in your cluster as a collection of low level primitives. There are higher level abstractions for managing distributed databases – such as StatefulSets.
We will cover those in a subsequent blog-post, for now lets take a look at those related to low level storage.
Deploying a stateful pod on Kubernetes will always involve a Persistent Volume (PV). They represent the backend storage entity that a pod might consume – think about the PersistentVolume as some meta-data that represents the existence of some storage.
In the following we example – we have manually created an EBS volume:
$ aws ec2 create-volume --size 100
vol-867g5kii
We create a PersistentVolume manifest that is the information Kubernetes needs to know about our EBS volume:
kind: PersistentVolume
apiVersion: v1
metadata:
name: task-pv
spec:
capacity:
storage: 100Gi
accessModes:
- ReadWriteOnce
awsElasticBlockStore:
volumeID: vol-867g5kii
fsType: ext4
Note the awsElasticBlockStore and volumeID: vol-867g5kii lines which references our EBS volume.
Then we use the `kubectl` command to submit this configuration to the Kubernetes masters:
$ kubectl apply -f pv.yaml
There are various types of volume you can use to back a Kubernetes PersistentVolume.
The example above uses EBS but there are drivers for various other Providers (Portworx included!)
Also – there is the FlexVolume driver which makes it easy to write your own drivers to support some other type of storage.
Persistent Volume Claims represent the exclusive usage of a Persistent Volume by a particular Pod.
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: task-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
Note how we don’t explicitly name our PV but instead make some requests for storage. In this case we are asking for a volume that has 100 Gigabytes of storage and Kubernetes will pick an appropriate PersistentVolume to meet that claim.
In our example – we already have a PersistentVolume that is not currently used and has 100Gi of storage so Kubernetes will automatically pick that volume and claim it.
Let’s take a look at a Pod manifest that will make use of our task-pvc claim. Our example is a MySQL container that will have our EBS volume mounted at /var/lib/mysql
kind: Pod
apiVersion: v1
metadata:
name: task-pod
spec:
volumes:
- name: task-volume
persistentVolumeClaim:
claimName: task-pvc
containers:
- name: task-container
image: mysql:5.6
ports:
- containerPort: 3306
name: "http-server"
volumeMounts:
- mountPath: "/var/lib/mysql"
name: task-pvc
The claimName: task-pvc field is the key link between a pod and our PV Claim (and by extension the PV we created).
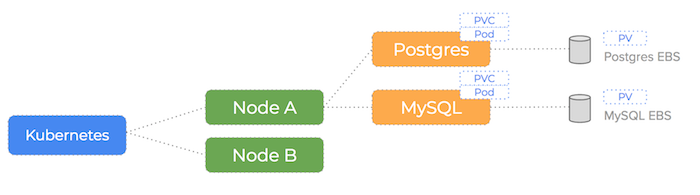
We know how to manually create an EBS volume and tell Kubernetes about it, but what if we wanted a fully automated version of that process?
Kubernetes can dynamically provision volumes for an incoming claim. To do this – it needs to know what type of storage to create and so uses the concept of a StorageClass:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
zone: us-east-1d
iopsPerGB: "10"
Notice the provisioner field – this means Kubernetes will perform the $ aws ec2 ec2 create-volume –size 100 we used earlier to dynamically create an EBS volume.
The parameters field gives us the chance to send options to that provisioner for our volume. In our case, we are telling AWS about the type of volume (SSD or spinning), the zone it lives in and the IOPS it can consume. The parameters you specify will depend on the type of dynamic provisioner that you are using.
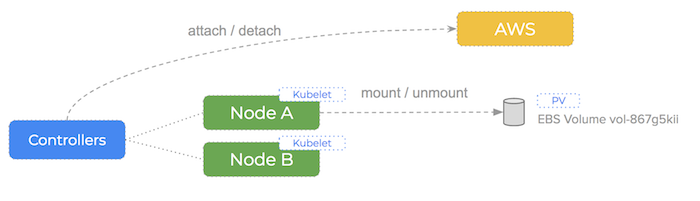
Kubernetes has a number of controllers that run on the masters, monitor the state of the cluster and initiate actions in response to events.
It also runs a kubelet process on all of the worker nodes. The kubelet stays in constant contact with the controllers, submitting metrics about current running pods and listening for new instructions.
The kubelet itself performs the low-level mount and mkfs commands when instructed by the controller.
So in conclusion, to use Kubernetes storage, you need to:
Portworx has excellent support for running PersistentVolumes on Kubernetes and we have made our installation process pretty streamlined.
Head on over to our documentation and you can install it today or learn more about why we think Portworx is the best storage for Kubernetes!


