


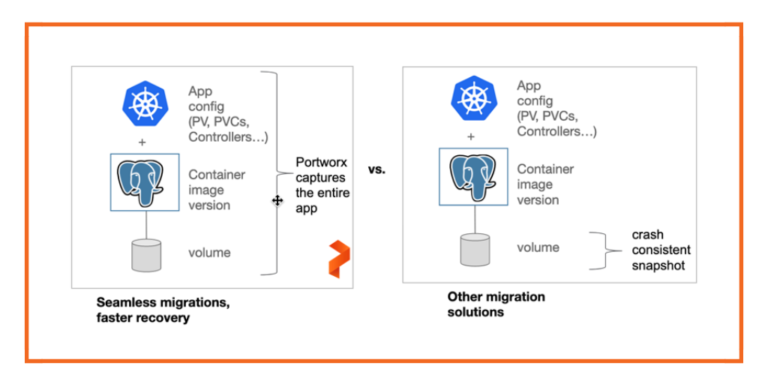
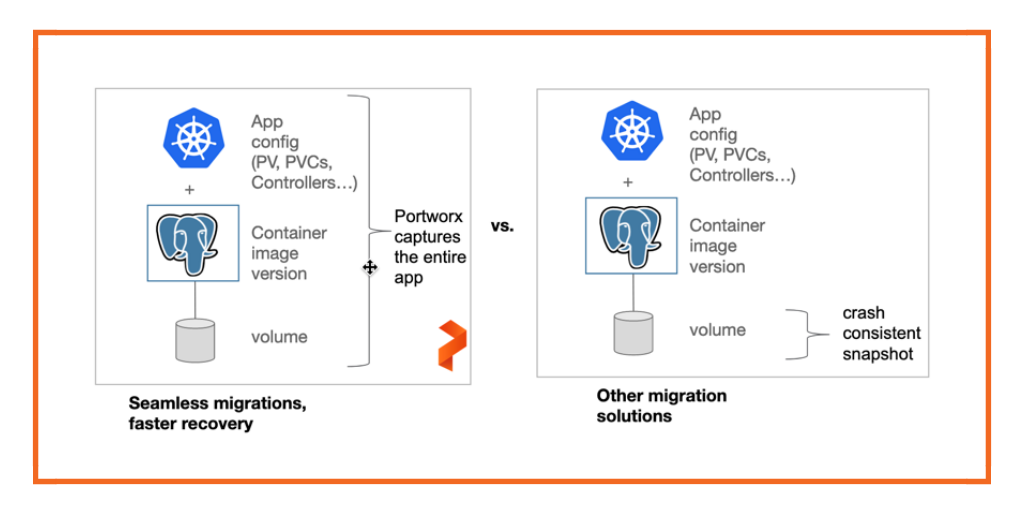
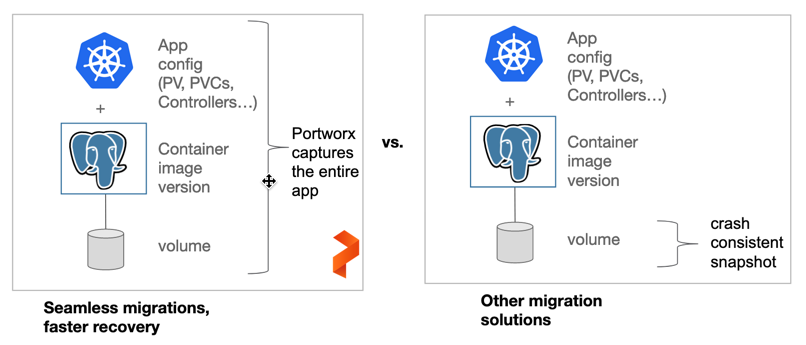
One of the motivations for moving to cloud-native architecture is the promise of portability. Even though Kubernetes makes it easy to move applications across different deployment targets and environments, the promise of portability is confined to stateless applications. Portworx augments the power of portability to an entire application, including the stateful services such as relational databases and NoSQL databases.
This article looks at the ability of Portworx to move data between environments, enabling the promise of hybrid and multi-cloud environments.
The meteoric rise of Kubernetes is attributed to its ability to run and scale applications reliably across environments. The new breed of applications designed to run on Kubernetes are termed cloud-native applications.
Cloud-native apps are built as services packaged in containers, deployed as microservices, and managed on elastic infrastructure through agile DevOps processes and continuous delivery workflows.
Cloud-native apps have fewer dependencies on the underlying infrastructure exposed by cloud vendors or on-prem data centers. Kubernetes acts as an abstraction layer decoupling the applications from the infrastructure. The artifacts and deployment units defined by Kubernetes don’t have the visibility or the knowledge of the infrastructure that may run on physical machines or a set of virtual machines in the cloud—they don’t need to.
Kubernetes effectively abstracts away the compute, storage, and networking resources. For example, an application deployed on Kubernetes asks for a load balancer to expose a public-facing service without negotiating with the cloud provider. Similarly, the number of CPU cores and memory requested by a microservice is provided by Kubernetes from a pool of compute resources.
The abstraction provided by Kubernetes brings ultimate portability to cloud-native applications, delivering the promise of code once, run anywhere. A set of microservices running on Google Kubernetes Engine can be easily moved to Azure Kubernetes Service with almost no changes.
The promise of portability delivered by Kubernetes is not just confined to public cloud environments. Platform vendors such as Google, IBM, Red Hat, and VMware offer a hybrid cloud platform based on Kubernetes.
Enterprises are considering Kubernetes as the consistent platform across the data center and the public cloud. By standardizing on Kubernetes, IT teams can reduce infrastructure management complexity and maintenance costs. Developers and operators can focus on application reliability and availability instead of dealing with infrastructure. They get a standard, consistent application deployment mechanism within the data center and the public cloud.
The compelling value proposition of portability has made Kubernetes the choice for enterprise hybrid cloud platforms.
The portability of workloads running on upstream Kubernetes comes with a caveat—it is mostly restricted to stateless applications that don’t deal with persistence. But enterprise line-of-business applications are backed by relational databases such as Oracle, Microsoft SQL Server, DB2, and MySQL. Many of the contemporary workloads use NoSQL databases, including MongoDB, Cassandra, and HBASE.
Unlike compute and networking resources that are easily decoupled by Kubernetes, storage resources are tightly coupled with applications. For example, to make a MySQL database available in a different cluster, two elements need to move—the database engine packaged as a set of Kubernetes pods and objects like PVCs, controllers, service accounts, etc., and the persistent volumes associated with the pods. While the pods are extremely portable, the storage volumes are not.
When a stateful pod requests Kubernetes for a persistent volume, it talks to the infrastructure provider’s block storage service to provision the volumes. For example, on AWS, Kubernetes provisions EBS volumes while dealing with persistent disks in Google Cloud Platform. Since these resources are specific to the cloud provider, it is hard to migrate the volumes.
To overcome the limitation associated with lack of portability of stateful workloads, DBAs and administrators rely on traditional storage operations, such as exporting and importing the data manually. These operations are performed out of the band that executes outside of the Kubernetes context, leading to data corruption and inconsistent data. Additionally, because deploying a Kubernetes application requires not just a pod, but a series of Kubernetes objects that define application configuration, even if you can move the data between environments, you still need to recreate and remap your application configuration to the new environment. This makes spinning up Kubernetes applications in the new environments a complex, manual task.
This limitation reduces the portability of Kubernetes workloads in hybrid and multi-cloud environments.
Kubemotion (formally known as PX-Motion) is one of the features introduced with Portworx 2.0. It is designed to extend the portability of Kubernetes to even stateful workloads such as databases.
With Kubemotion, Portworx solved the critical problem of data portability of applications running on Kubernetes by enabling customers to migrate application data and configuration between clusters across hybrid- and multi-cloud environments.
Kubemotion is built on the solid foundation of the Portworx storage cluster, known as PX-Store. Similar to Kubernetes, PX-Store decouples storage resources from stateful workloads that consume those resources. During the installation of Portworx, storage resources attached to each host of the Kubernetes cluster are aggregated and pooled to create logical volumes. These volumes abstract away the block storage service specific to the infrastructure provider. Applications that need persistence storage talk to the container-native storage fabric exposed by the Portworx storage cluster. These services don’t have visibility or dependency on the underlying storage primitives or block storage services.
Due to the abstraction offered by Portworx, applications, along with associated volumes, can be moved to any Kubernetes environment that has Portworx installed.
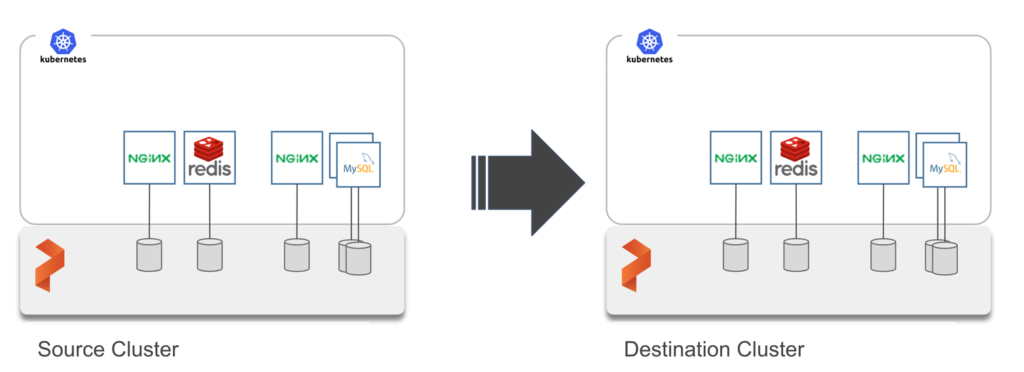
Kubemotion is the technology that enables the movement of storage volumes and application configuration across Kubernetes clusters in hybrid and multi-cloud environments. Storage admins can perform migration tasks that are aligned with agile, cloud-native DevOps processes.
Kubemotion extends the promise of Kubernetes portability to stateful workloads.
Kubemotion takes advantage of the Portworx building block technologies such as STORK. One of the obvious prerequisites is to have Portworx installed on both of the Kubernetes clusters running in the hybrid cloud.
Portworx encrypts the data at rest and in transit during the migration. To maintain the keys, certificates, and secrets, Kubemotion relies on a key management server, such as Hashicorp Vault or AWS KMS. Customers need to configure the KMS before using Kubemotion for migration.
It is also important to ensure that both of the Kubernetes clusters running in the hybrid environment are connected. The destination cluster should have ports 9001 and 9010 open.
Each Portworx cluster running in Kubernetes has a unique cluster token. The token of the destination cluster is retrieved and paired with the source Kubernetes cluster. This step brings visibility to Kubemotion. It tells Kubemotion that the clusters are participating in the migration.
Once the pairing of clusters is established, operators can run a single command to initiate the migration of storage volumes and application resources. The tool allows either migrating all the volumes belonging to a namespace or a specific volume associated with the workload.
Depending on the size of the volumes and the network bandwidth, the migration may take a few seconds to hours. After it is complete, the storage volumes become available at the destination cluster.
When the stateful workload is launched on the destination cluster, it sees exactly the same volumes populated with data. And because application configuration has also been moved, starting up the applications at the destination cluster is as easy as running the kubectl -f apply command.
The above process can be easily automated via the Portworx API.
Kubemotion reduces the friction involved in moving stateful workloads in hybrid and multi-cloud scenarios.
Kubernetes is rapidly becoming the preferred hybrid cloud platform. Large platform vendors are investing in building a consistent hybrid platform that seamlessly connects on-premises Kubernetes clusters to the public cloud.
Portworx can run on any flavor of Kubernetes, including the upstream distribution, managed containers as a service (CaaS), custom deployments in public cloud, and on-premises environments. Here are some of the most popular options:
Google has announced the availability of Anthos, a hybrid and multi-cloud platform based on Kubernetes. Customers can extend GKE On-Prem to GKE in the public cloud. Anthos comes with centralized configuration and policy management, traffic routing, and centralized logging, monitoring, and tracing capabilities. Portworx, along with Cisco, VMware, NetApp, and others, is a launch partner for Anthos.
IBM has invested in IBM Cloud Private, a hybrid cloud Kubernetes platform. It is an integrated environment for managing containers that include the container orchestrator Kubernetes, a private image registry, a management console, and monitoring frameworks. IBM Cloud Private has been certified for primary infrastructure (server, network, & storage) providers, including Dell, NetApp, Cisco, and Lenovo, as well as IBM Power Systems and IBM Z.
Red Hat OpenShift is an enterprise Platform as a Service (PaaS) built on top of Kubernetes. OpenShift can be deployed within the data center or in public clouds, including AWS, Azure, and GCP. Enterprise customers are running Red Hat OpenShift in hybrid environments.
VMware and Pivotal are delivering PKS, the hybrid Kubernetes platform that runs on vSphere and vCenter environments. With VMware becoming available in IBM Cloud, AWS, Azure, and hyper-converged infrastructure, customers are deploying PKS for running cloud-native applications in hybrid environments.
Portworx and Kubemotion are supported in all the environments, including Anthos, IBM Cloud Private, VMware Enterprise PKS, Red Hat OpenShift, and other distributions of Kubernetes.
Kubemotion can seamlessly move data and stateful workloads across the on-premises clusters and cloud-based Kubernetes clusters configured in a hybrid environment.
No matter which environment and Kubernetes platform you deploy, Portworx and Kubemotion form the storage fabric of your hybrid cloud.



