


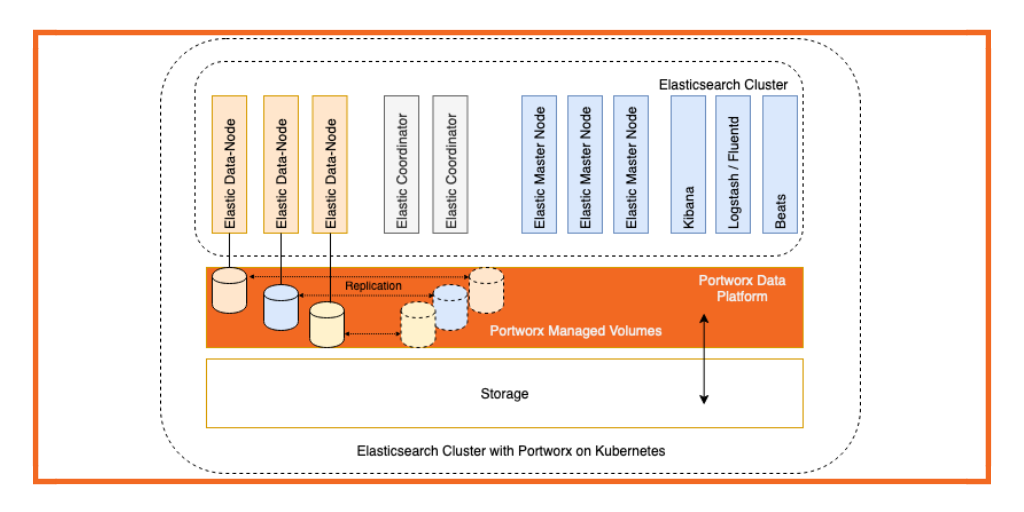

In today’s world data is the new currency. Data and data analysis allows you to make informed decisions that help drive desired business outcomes. Data management brings with it many challenges such as data-pipeline architecture design, data modeling, data governance, data curation, and data lifecycle management. Systems and applications are being developed to address the above mentioned concerns for structured and unstructured data. This blog focuses on one such system: Elasticsearch. We will demonstrate how you can scale your Elasticsearch cluster easily using Kubernetes and improve observability of the data system behind the Elasticsearch cluster.
Elasticsearch is an open source distributed full text search engine capable of indexing vast amounts of structured and unstructured data in real time. Elasticsearch offers a RESTful search and analytics engine based on the Lucene library. Elasticsearch, as the name implies, started with a “You know, for search!” use case, but it continues to expand its application to other use cases. Here are some of the top use-cases:
Elasticsearch, depending on the use case, has become a critical component in business success. You can no longer afford any downtime of the Elasticsearch system. The following is a list of advantages running Elasticsearch in a Kubernetes cluster:
Before we discuss any performance tuning and scaling of an Elasticsearch cluster, we need to understand the data flow inside the Elasticsearch cluster and also understand the integration between the Elasticsearch cluster and the Portworx data platform. When an Elasticsearch client generates data for indexing, the data record passes through a coordinator and/or ingest nodes so that it can be indexed by the data node. Once the data enters the Elasticsearch data node, it is parsed, analyzed, and indexed so that it can be searched using the Kibana front end. In order to save the data, the index is flushed to the storage system. In this instance, the Portworx data platform manages the PersistentVolumes (PV) and commits the index data to the underlying storage medium.
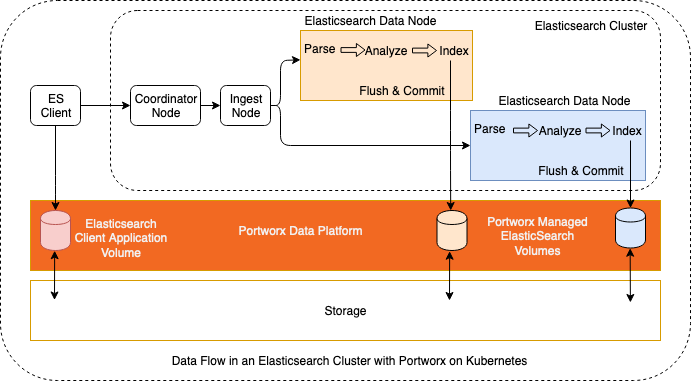
You can find detailed instructions for installing Elasticsearch with Portworx here. In the section below we will focus on describing the best practices for Elasticsearch and how you can scale an Elasticsearch cluster with its persistent storage.
...
- name: "ES_JAVA_OPTS"
value: "-Xms12g -Xmx12g"
...
kubectl scale sts elasticsearch-data --replicas=5
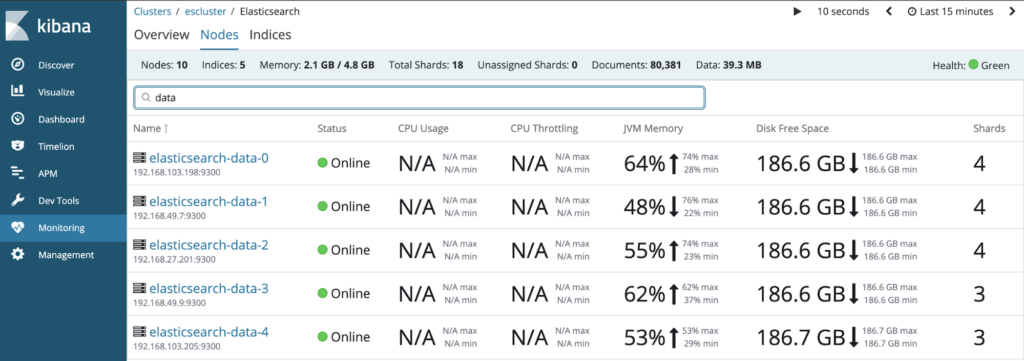 The Portworx data platform automatically scales with the Elasticsearch data nodes and dynamically provisions additional high-IO CoS storage. You can observe the storage performance and capacity using Portworx’s Grafana dashboard and built-in GUI as shown below.
The Portworx data platform automatically scales with the Elasticsearch data nodes and dynamically provisions additional high-IO CoS storage. You can observe the storage performance and capacity using Portworx’s Grafana dashboard and built-in GUI as shown below.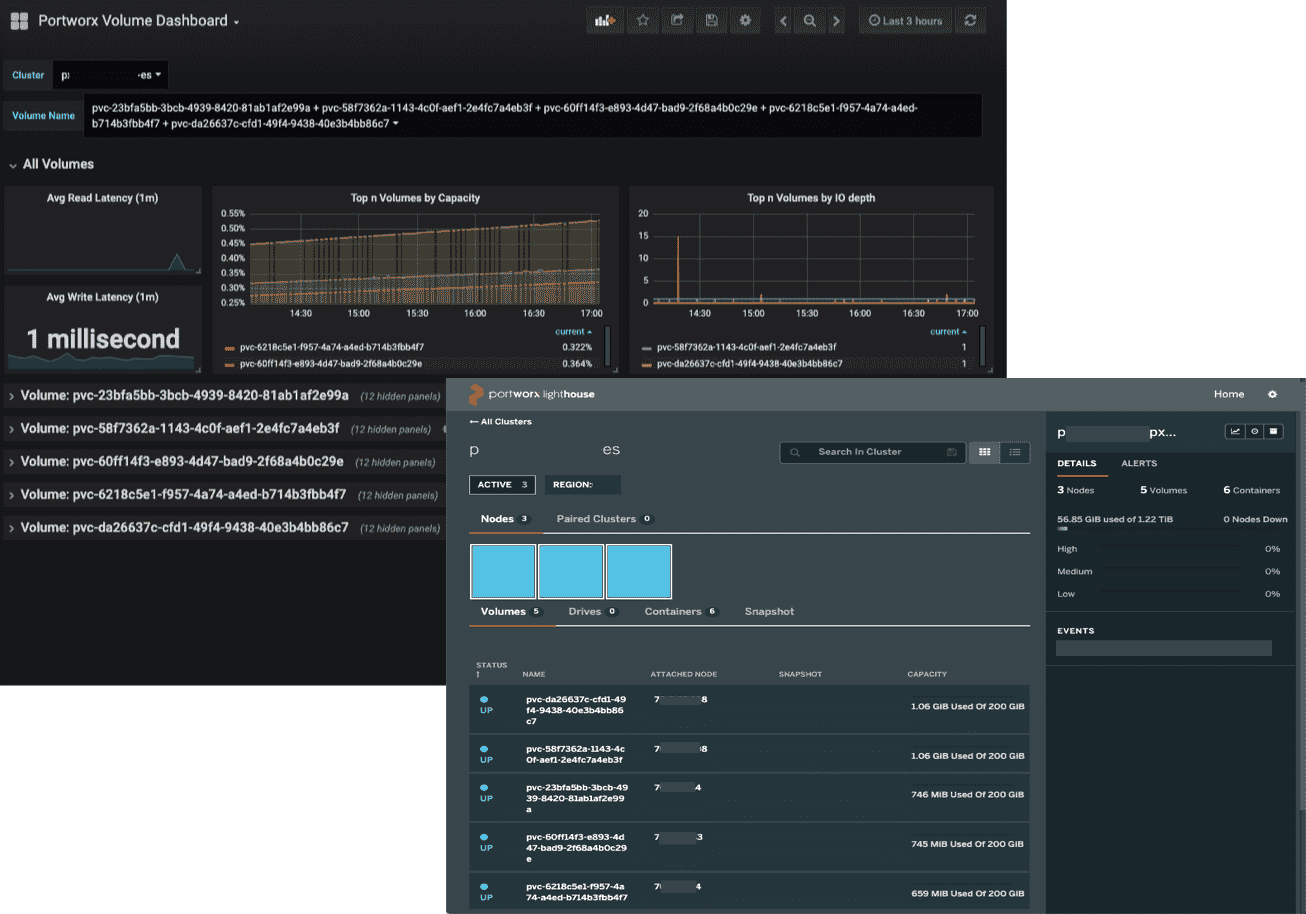
This blog covered use cases of Elasticsearch and topics of deployment, scalability and observability of Elasticsearch with the Portworx data platform. In the next blog post related to Elasticsearch, we will dive deep into a particular use case and show you how you can deploy Elasticsearch with Portworx to reduce recovery time and increase cost savings.
If you would like to learn more about the Portwox Data Platform, please request a demo and talk to one of our Elasticsearch experts. You can also join our slack channel to discuss how Portworx Enterprise can help you run stateful workloads in production.
You can also check out these tutorials on running Elasticsearch on the most popular Kubernetes platforms.


