



A growing number of enterprises and startups—in almost all industry verticals—run their applications on AWS. If you are just starting your company, AWS gives you the fastest and easiest way to ramp up and release your revenue-generating application to your end customers. It is also a great option if you are an enterprise with an on-prem footprint and you are looking for a way to reduce your CAPEX costs and the amount of time you spend on building and maintaining datacenters.
It is important to note, however, that there have been an increasing number of AWS outages over the past few months. In December 2021 alone, AWS us-east-1 region was hit with three different outages, resulting in service disruption for companies like Slack, Asana, Epic Games, and many more. To avoid these disruptions and ensure application uptime, architects need to build data protection and disaster recovery solutions, where they can quickly execute a recovery plan and reduce the recovery time for their applications.
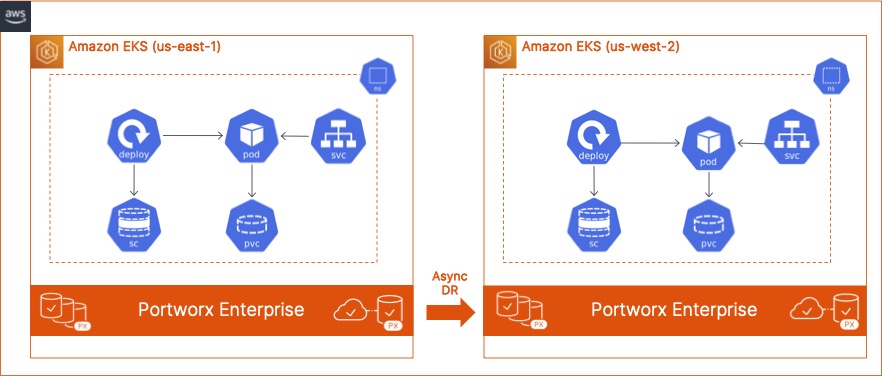
In this blog, we discuss how Cloud and DevOps Administrators can leverage Portworx PX-DR to build an asynchronous disaster recovery solution for their containerized applications running on AWS EKS. Deploying a resilient and robust DR solution using PX-DR can help organizations quickly recover from AWS region outages and bring their applications online in a secondary EKS cluster running in a different AWS region.
To get started with Portworx PX-DR, we will need two EKS clusters.
PX_POD=$(kubectl get pods -l name=portworx -n kube-system -o jsonpath='{.items[0].metadata.name}')
kubectl exec $PX_POD -n kube-system -- /opt/pwx/bin/pxctl status | grep UUID | awk '{print $3}'
/opt/pwx/bin/pxctl license activate <<license-key>>
STORK_POD=$(kubectl get pods -n kube-system -l name=stork -o jsonpath='{.items[0].metadata.name}') &&
kubectl cp -n kube-system $STORK_POD:/storkctl/linux/storkctl ./storkctl
sudo mv storkctl /usr/local/bin &&
sudo chmod +x /usr/local/bin/storkctl
kubectl create secret generic --from-file=$HOME/.aws/credentials -n kube-system aws-creds ### kubectl edit deployment -n kube-system stork ### Add the following under the spec.template.spec section volumes: - name: aws-creds secret: secretName: aws-creds ### Add the following under spec.template.spec.containers volumeMounts: - mountPath: /root/.aws/ name: aws-creds readOnly: true
Note: Do not enable load balancing without authorization enabled on the Portworx cluster.
kubectl edit service portworx-service -n kube-system kind: Service apiVersion: v1 metadata: name: portworx-service namespace: kube-system labels: name: portworx spec: selector: name: portworx type: loadBalancer
storkctl get migrationschedule -n <<demo-namespace>> storkctl get migrations -n <<demo-namespace>>
storkctl edit migrationschedule <<migrationschedule-name>> -n <<demo-namespace>> apiVersion: stork.libopenstorage.org/v1alpha1 kind: MigrationSchedule metadata: name: mysqlmigrationschedule namespace: migrationnamespace spec: template: spec: clusterPair: remotecluster includeResources: true startApplications: false includeVolumes: false namespaces: - migrationnamespace schedulePolicyName: testpolicy suspend: true
kubectl scale --replicas 0 deployment/<<deploymentname>> -n <<demo-namespace>>
storkctl activate migrations -n <<demo-namespace>>
kubectl get all -n <<demo-namespace>> kubectl get pvc -n <<demo-namespace>>
Deploying and building a disaster recovery solution is just that easy with Portworx PX-DR, and now you know how to restore your applications quickly in a different AWS region and avoid bad customer experience if us-east-1 goes down again.
We also captured all these steps in a demo video on our YouTube channel; you can find that below:



