




As usage and adoption for containerized apps grow, so does the importance of properly protecting containerized workloads. Data protection remains a critical part of data management. Organizations need to ensure that their containerized applications running on Kubernetes are highly available, fully backed up, and secure from outages or ransomware threats.
Many organizations assume they can approach Kubernetes data protection with traditional solutions, but they mistakenly overlook key distinctions between traditional and containerized applications. Traditional applications run directly on physical or virtual machines and have simpler storage needs than distributed, containerized applications. When looking at the differences of backing up Kubernetes vs virtual machines (VMs), VMs are usually straightforward to back up—especially compared to containerized applications. An application is tied to a single VM or group of VMs, and backing up the VM is usually sufficient to fully protect the application.

Containerized applications are different. They are purpose-built to be highly dynamic, scale rapidly to meet demand, and have components spread out across multiple physical nodes. Traditional methods cannot support these modern architectures. Containers can be ephemeral, meaning they are meant to be disposable and replaceable. Any persistent data must be stored externally on a volume. Therefore, simply backing up a container won’t capture the externally stored persistent data—leading to inconsistent restores.
Containers can also run on a wide variety of infrastructure, giving them flexibility and portability over a VM. Containerized applications, as well as the microservices that comprise them, can be distributed across different environments—whether that is on-premise or in the private or public cloud.
For this reason, applications need to be highly mobile, and they must be able to move or copy data within or between different environments. Application mobility delivers benefits in several key use cases—like high availability, migrations, upgrades, and disaster recovery. Ease of migration also eliminates vendor lock-in, giving organizations the flexibility of choosing preferred deployment models and providers. Since containerized applications produce a huge volume of data, it is necessary to enable easy data migrations between environments. Using a traditional approach is far too complex and time-consuming to meet this challenge.
By using a traditional data protection solution to meet the complexities of containerized workloads, organizations open themselves up to the risk of potential data loss and downtime—all of which can have a negative impact on reputation and revenue. 451 Research found that 30% of organizations have lost more than $1 million as a result of their most recent outage, and 34% of organizations reported that lost data was a top consequence of their outage.[1]
Ensuring high availability for applications is mandatory. Enterprises simply can’t risk the impacts of an outage, and they must prioritize business continuity.
Organizations must fully protect the entire Kubernetes application in order to ensure high availability. However, an app is made of much more than just its data. There are also underlying resources—referred to as objects and configurations—that contain important information to keep pods running smoothly. Kubernetes objects define the application’s desired state, setting policies for lifecycle behaviors and detailing available resources to keep applications running consistently at high performance.
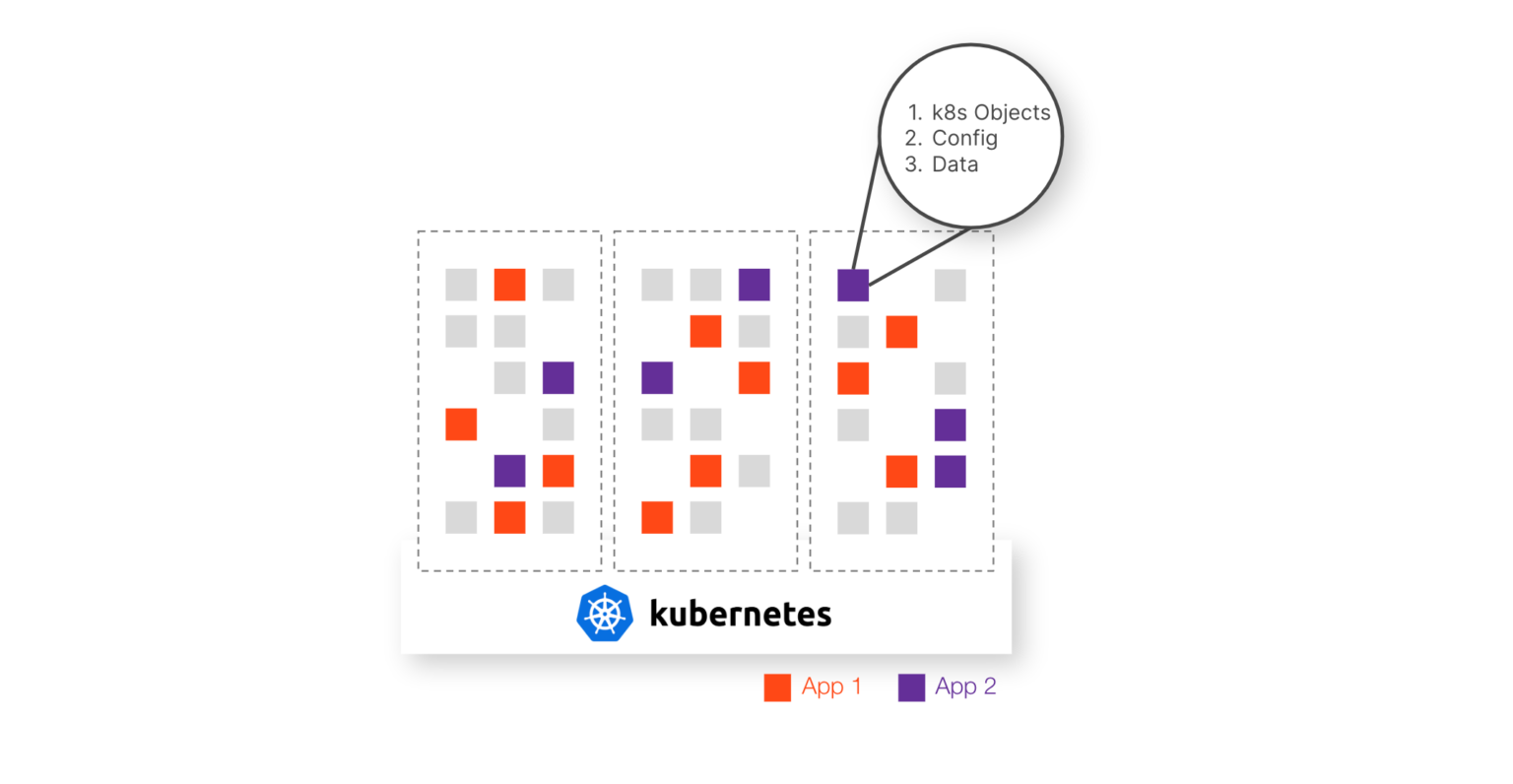
All of this associated application data—including persistent volumes, configurations, and objects—must be backed up for high availability and rapid restores. Backing up at the virtual machine level is likely to result in capturing partial data of multiple applications but missing complete data from any single application. This leads to slow restore times, data loss, and errors that can be difficult to detect.
The key to high availability is an application-aware backup solution that can capture the entirety of the Kubernetes application. At the same time, users need to be able to choose at a granular level which of these associated resources they want to protect—all of them or just a specific subset. Being able to select the precise resources for each application also ensures that the application can be restored quickly and successfully.
In order to enable more automation use cases and deploy applications on-demand, the underlying resources that keep Kubernetes applications running are becoming more complex—and that presents a major challenge in the data protection space. Data protection solutions need to be able to answer that call.
Now, we are seeing common resources shared among multiple namespaces or clusters. When backing up a namespace, most data protection solutions will only back up the data and resources in that particular namespace. If that namespace is using a shared resource, however, you may not know that the backup is incomplete until you need to restore it. This can lead to an incomplete restore with missing data, which can either require manual intervention or result in a non-functioning application. This not only can slow down time to recovery, but it can also add to the underlying cost of recovering from an outage.
To avoid this problem, developers need to manually back up these shared resources separately. This requires them to manually copy over the shared resources from the primary copy to the secondary. However, if the primary goes down before the developer is able to manually back up the shared resources, those specific resources and configurations are lost.
There’s a better way. A true built-for-Kubernetes data protection solution should be able to automatically recognize any shared underlying resources, even if they’re shared in multiple namespaces or clusters. Portworx Backup automates a tedious, manual process that is rife with potential for human error or incomplete restores.
Another key piece of high availability is capturing application-consistent backups. For example, imagine you are taking a snapshot of a database. When doing this, you want to make sure that you are backing up all pending write activity. Often, pending I/O activity will not be flushed down into the backing volume, leaving a delta between the backup file and the primary copy.
Since the pending writes were never copied into the volume, when it comes time to restore, the restore comes from an inconsistent copy of the data. With the resulting data loss, you would likely have no way of knowing which writes did not get properly backed up.
Using a solution that offers application-consistent backups—like Portworx Backup—allows users to define pre- and post-rules based on their data service of choice. These rules inform the application when a snapshot is being taken, so all pending write activity is automatically flushed down to the backend volume. This ensures snapshot consistency—you can always be certain that your backup files contain the most recent changes to your data.
A data protection solution built for Kubernetes ensures backups are done at the container level. Application-aware and container-granular backups lead to complete and rapid restores. Portworx Backup is a solution that can provide application consistency and application-native support, so your organization can trust that your containerized applications will be available when you need them in order to avoid downtime, poor customer experience, or SLA penalties.
Get started by signing up for a free trial of Portworx Backup today.
To learn more about Kubernetes data protection, check out the O’Reilly book, Container Storage and Data Protection for Apps on Kubernetes.
Sources



