


Enterprises are increasingly moving applications to containers, but many teams also have a huge investment in applications that run virtual machines (VMs). Many of these VMs often provide services to new and existing containerized applications as organizations break the monolith into microservices. Enterprises are diving headfirst into their container platforms, which often provide seamless integration of computing, storage, networking, and security. Portworx provides the data management and protection layer for these containerized applications. OpenShift Virtualization uses KubeVirt to offer a way for teams to run their VM-based applications side by side with their containerized apps as teams and applications grow and mature. This provides a single pane of glass for developers and operations alike. In this blog series, we’ll show you how Portworx can provide the data management layer for containers and for VMs. You can think of Portworx much like the v-suite of products in vSphere. Portworx can provide disks to VMs like vSAN, and data protection like vMotion but for both VMs and containers on OpenShift Container Platform.
Some Legacy Virtualization provides the capability to failover Virtual Machines from one datacenter to another whenever is needed. When moving Virtual Machines, failing over Virtual Machines from one Kubernetes cluster to another becomes a problem that Portworx Metro-DR solves.
Portworx Metro-DR allows you to create a single Portworx cluster across two data centers and failover Virtual Machines from one cluster to another whenever there is a need to do so.
First, on our source cluster let’s create a DataVolume. We will use this Sharedv4 StorageClass to provision our DataVolume. RWX volumes are required by kubevirt for live migration within the same OCP cluster, so we chose this StorageClass to allow for Live Migration in addition to DR migration across two OpenShift clusters.
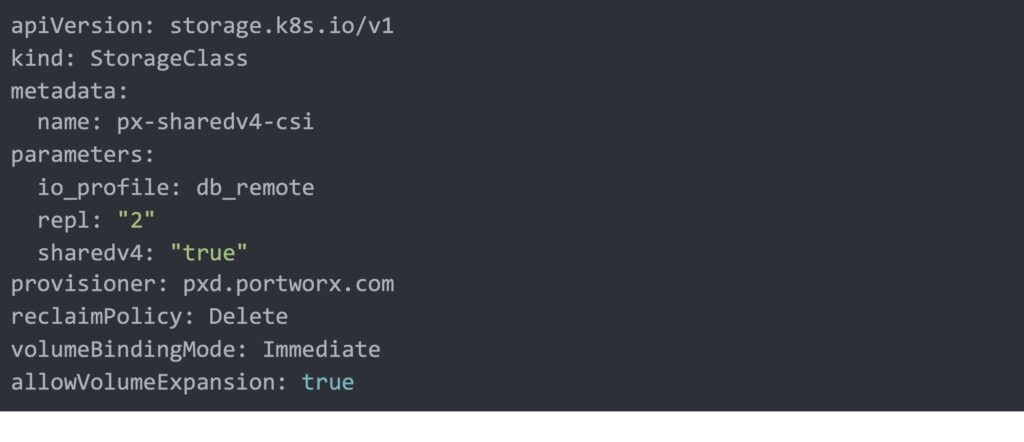
Create DataVolume in our `vm-dr` project
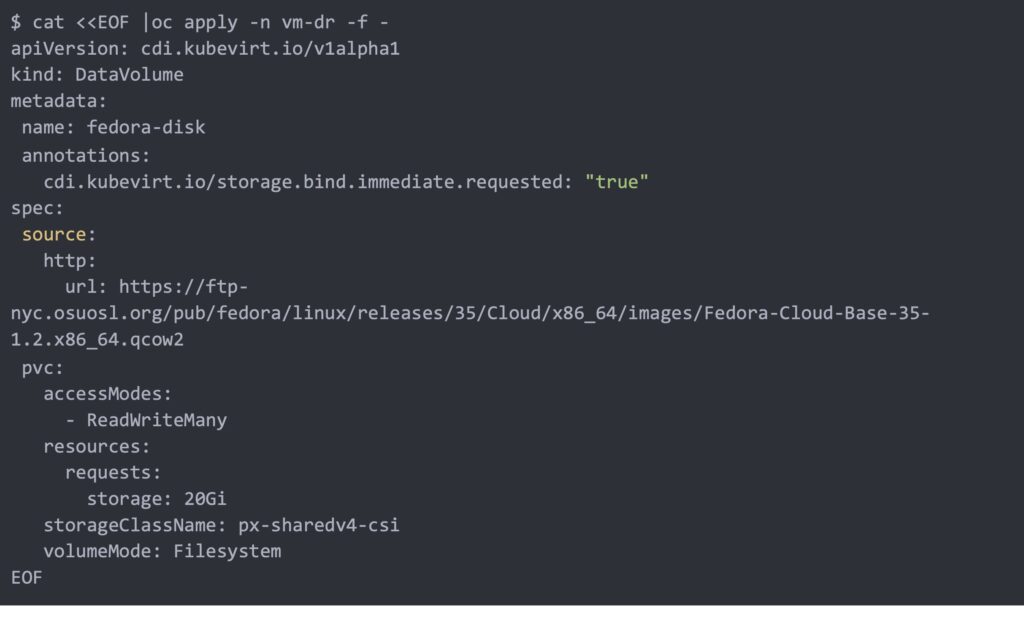
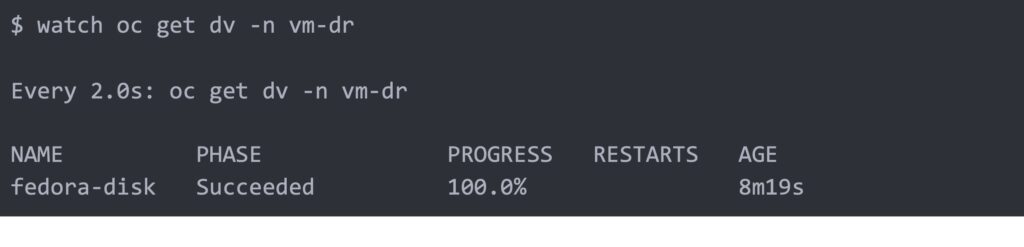
Watch the DataVolume import progress until it is completed
Once the image is fully imported we can go ahead and roll out a simple Fedora Virtual Machine using the `fedora-disk` DataVolume we created.
$ cat <<EOF |oc apply -n vm-dr -f - apiVersion: kubevirt.io/v1alpha3 kind: VirtualMachine metadata: labels: kubevirt.io/vm: fedora-vm1 name: fedora-vm1 spec: runStrategy: "Always" template: metadata: labels: kubevirt.io/vm: fedora-vm1 spec: domain: devices: disks: - disk: bus: virtio name: datavolumedisk1 - disk: bus: virtio name: cloudinitdisk machine: type: "" resources: requests: memory: 1Gi terminationGracePeriodSeconds: 0 volumes: - name: datavolumedisk1 persistentVolumeClaim: claimName: "fedora-disk" ## imported fedor disk name - cloudInitNoCloud: userData: |- #cloud-config user: fedora password: fedora chpasswd: { expire: False } name: cloudinitdisk ∙ EOF
Verify the VM is up and running.

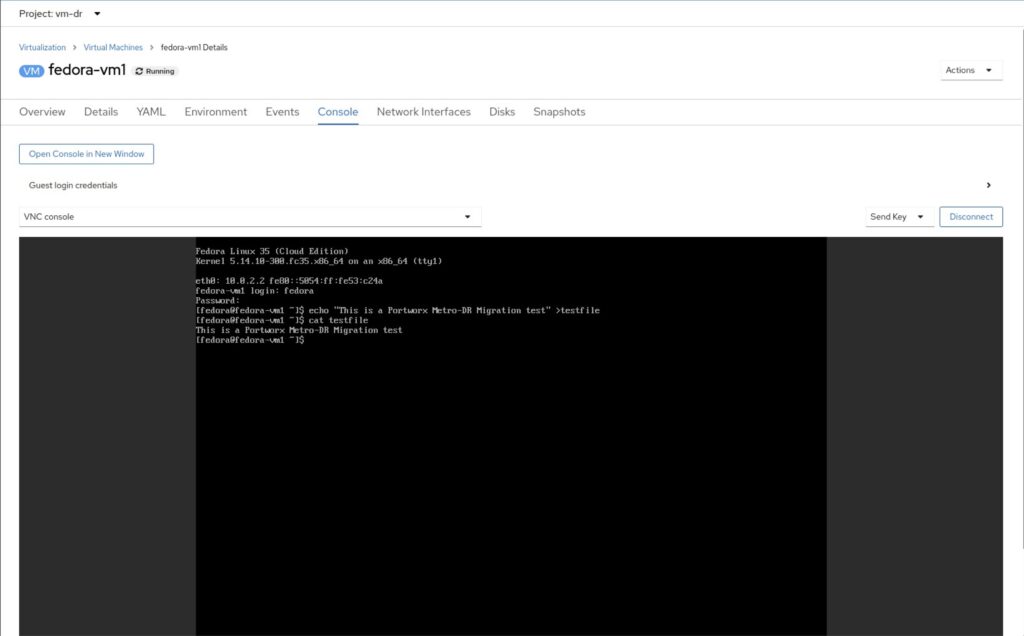
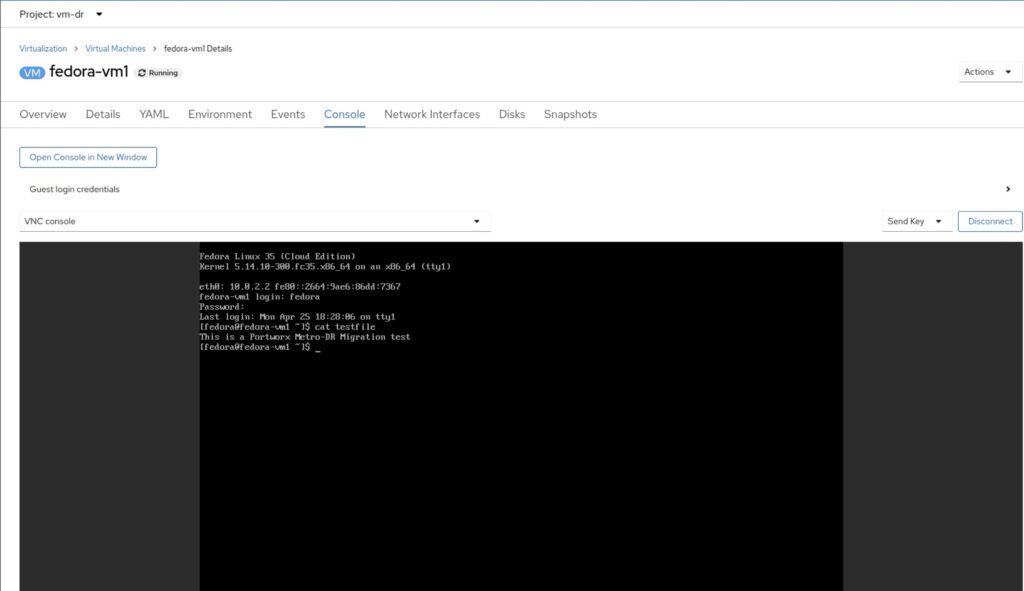
Open VNC connection to the VM either from the OpenShift GUI or using virtctl and write some text to a file on the root disk.
Now we have the virtual machine up and running on our source cluster we will need to create a migration schedule to move the virtual machine from one datacenter to another.

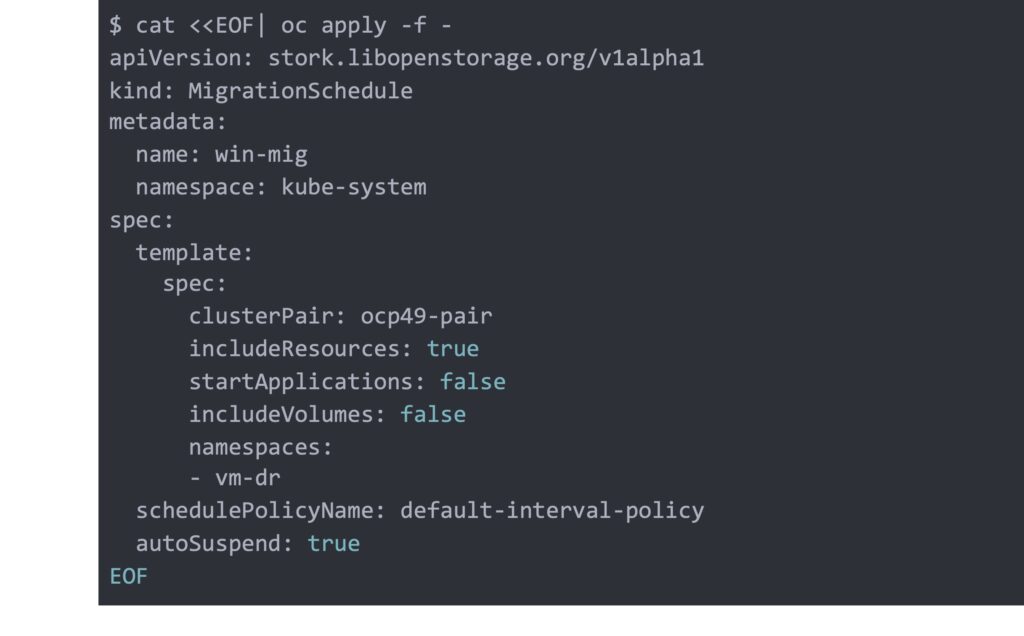
Now let’s apply our migration schedule, note we have `autoSuspend` set to true which will suspend the migration automatically once the migration is deactivated on the source cluster.
Check on the migration progress
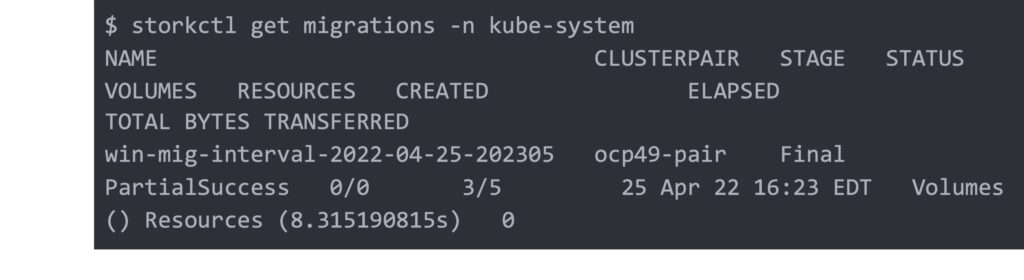
The partial success is not an issue and it is because the volume already exists in the DR site which is expected. We are also not able to update the kubevirt.io/ labels this does not affect the virtual machine failover and will be addressed in future stork releases.
Check on the destination cluster and verify the project got created and the VM is in Stopped state.


Note if you are using the OCP GUI to failover the virtual machine, you will need to suspend the migration manually before failing over the virtual machine
oc patch migrationschedule win-mig -n kube-system –type=json -p='[{“op”: “replace”, “path”: “/spec/suspend”, “value”: true}]’
Check the virtual machine status and verify it is in a stopped state on the course cluster. Then on the destination cluster let’s bring the virtual machine online and verify the text file we wrote on the source site exists.

For a while, failing over virtual machines across datacenters was limited to some hypervisors. With Kubevirt and Portworx Metro-DR, it became possible to move that experience to a cloud-native platform like Kubernetes.


