


Organizations have key business objectives such as better customer self-service, higher revenue targets or other business considerations as they grow their business. Technology selection, like microservice adoption or container orchestrator selection, has to support these key business outcomes. Organizations expect their container platforms which may run revenue generating applications to perform in a reliable and consistent manner. The Portworx data platform, Portworx Enterprise, plays a critical role in running stateful applications on container orchestrator like Kubernetes.
The reliability of the container platform and its subsystems should be observable and must generate monitoring data in order to track progress towards the business outcome. In this blog post, we will look at Portworx Enterprise’s observability via generated metrics and look at the included dashboards that can help you observe the reliability and performance of your application.
For a cloud native data solution like Portworx, with its scalability, security and API-driven nature, observability is a non-negotiable requirement. Let’s look at the key components of what makes an observable platform:
Portworx provides cloud native storage and data management for applications running on Kubernetes. If your stateful Kubernetes applications, backed by Portworx Enterprise, are generating revenue, you want to ensure your data platform is running reliably and is observable so that you are able to take corrective action quickly. Portworx Enterprise observability is achieved by:
As the Kubernetes platform owner, you want to achieve a business reliability target, typically known as service level objective (SLO) and create a service level agreement (SLA) between the platform team and the customer – the developers on the platform. We can further break down SLOs into key quantitative measures called Service Level Indicators (SLIs) such as availability, response time, frequency, error-rates, saturation rates, and others.
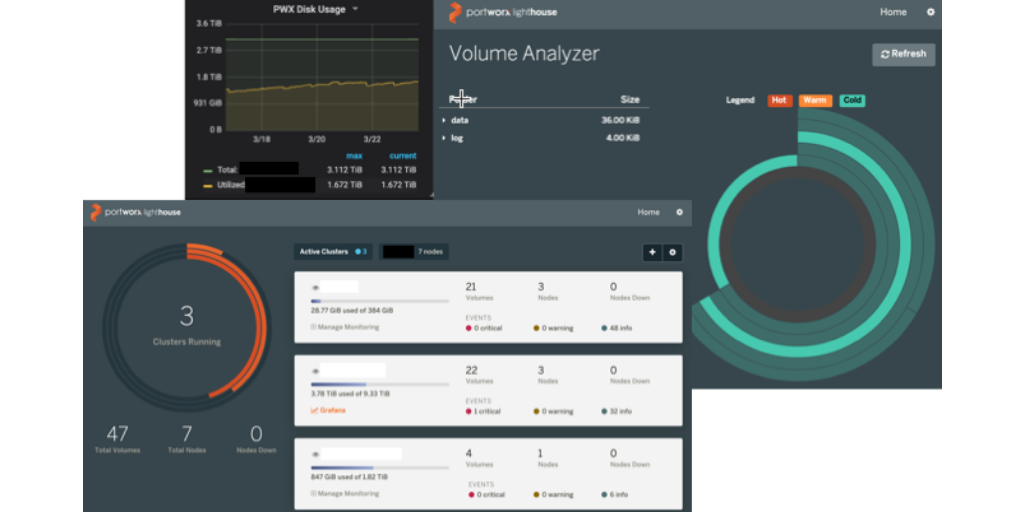
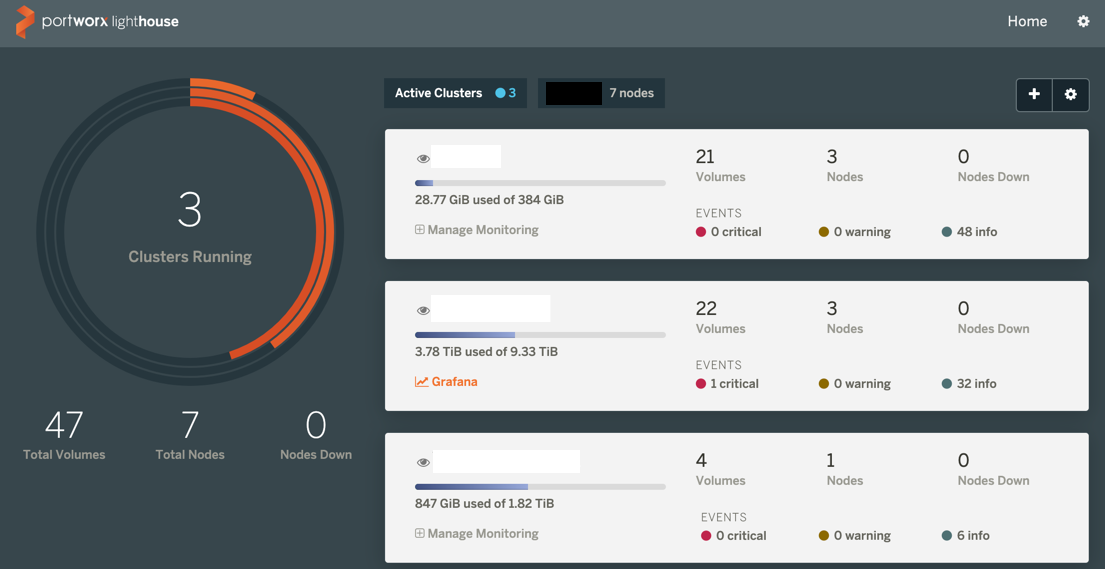
Portworx data platform comes pre-built with Grafana dashboards to help you track your SLAs and business objectives. You can find the Portworx cluster dashboard Grafana template here and the Portworx Volume dashboard Grafana template here. Using the Portworx data dashboards, you can observe the RED metrics of the data platform:
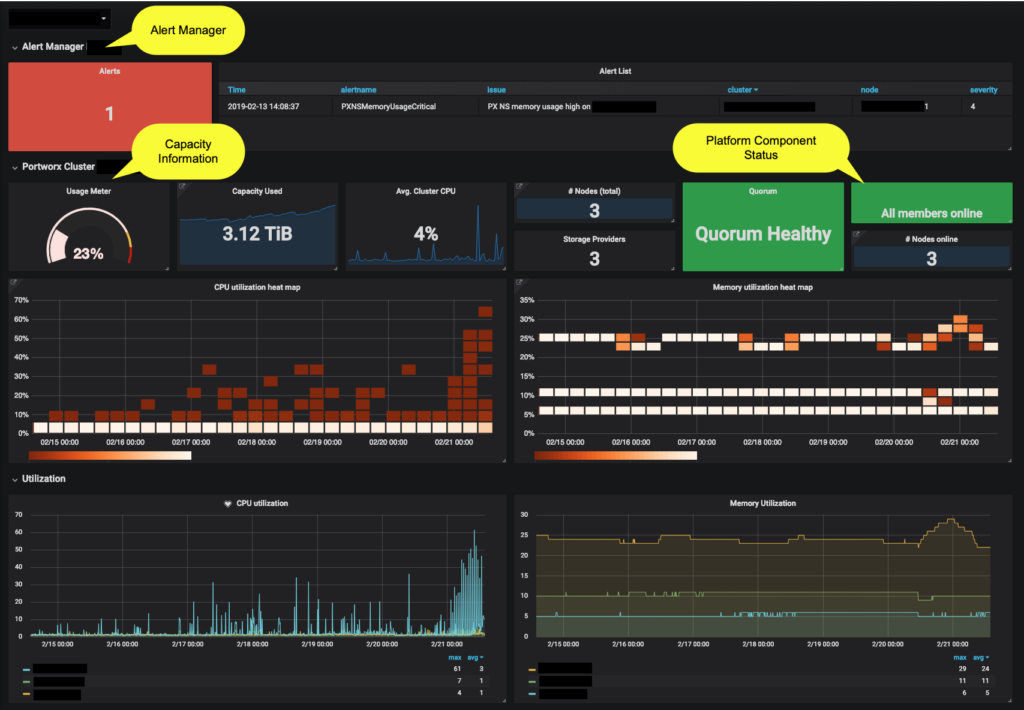
In the Portworx cluster dashboard image above, we wanted to highlight
Visualization of your platform’s metrics is a great step towards understanding, observability and efficient operation of your platform. On your dashboards, make a conscious decision about sections & metrics which will act as “information-emitters” versus sections and metrics which will be actionable. Mixing information-emitters with actionable metrics and not setting proper alerting thresholds can lead to “alert-fatigue”. Finally, make sure your dashboards flow up to the business outcomes the organization is trying to achieve (uninterrupted revenue generation from your Kubernetes applications).
Once you emit and collect data from your platform components, you are in a position to introduce a rule-based decision engine and or develop an AI/ML-based solution engine to automate routine tasks like adding capacity to your platform.
If you have questions about how Portworx Enterprise can help your organization with data protection and data portability when running on cloud native container orchestrators, please reach out to one of our Portworx experts and request a demo.


