
Under the Hood: How Portworx is Bringing Advanced VM Operations to Kubernetes
As VMware costs rise and organizations reevaluate their virtualization stack, many CIOs are asking a simple question: “Can we truly run VMs on Kubernetes without losing the operational maturity we’ve built on VMware?”
For the platform engineers, VMware admins, and architects tasked with making that shift real, the questions become more tactical:
- How do we keep VM uptime during host failures and maintenance?
- How do we migrate hundreds of VMs onto Kubernetes without weeks of manual work?
- Can we get Storage vMotion / DRS–style behavior in a KubeVirt world?
- How do DR, backups, and encryption translate when VMs run on Kubernetes?
While these challenges need to be addressed for a successful migration to Kubernetes, embracing Kubernetes sets enterprises up for long term success as a new standard for application development.
This blog post dives into the technical foundations behind our announcements this week at KubeCon 2025 including: Kube Datastore, Enhanced Storage Migration, Automated Storage Rebalancing, and Rapid VM Migration. These new capabilities highlight how Portworx is addressing these challenges to make it easy for technical teams to successfully drive this shift to Kubernetes.
Operating at Scale: Why a Software-Defined Data Platform Matters
Running a handful of VMs on Kubernetes is easy. Running hundreds or thousands—and upgrading the cluster, rotating nodes, and handling failures—is where architectural differences show.
Traditional external CSI-only model:
- Every volume is a LUN, quickly leading to host connection limit issues as applications scale
- Every VM move means multiple operations: attach, detach, rescan, remap, leading to significant CRUD churn
- Based on internal Portworx testing, a 500 VM / 1,500 volume cluster, a rolling upgrade can generate ~11,000 storage operations (node-side rescans plus array-side exports) just to move volumes around.
With Portworx and Kube Datastore:
- Volumes live inside a software-defined data platform running within Kubernetes
- Portworx, leveraging KDS, handles mobility and replication inside the cluster; arrays don’t need to constantly remap LUNs.
- The same rolling upgrade scenario generates limited LUN operations—volumes remain available and Portworx handles replication and failover behind the scenes.
This software-defined storage and data layer is what makes Portworx fundamentally different from external CSI drivers—it’s a full-stack storage platform purpose-built for Kubernetes and VMs.
Kube Datastore: The Storage Foundation for VMs on Kubernetes
Most cloud-native platforms utilize a shared-nothing storage model: each node uses its own disks, and replication across nodes provides high availability. That’s great for stateless microservices and low-cost local disks.
But in large enterprises, the story is different:
- You already have shared storage arrays (SAN) providing data reduction, erasure coding, and high availability.
- You now want to consolidate enterprise VMs and containerized applications on that same shared infrastructure.
Trying to layer a shared-nothing architecture on top of a shared array prevents enterprises from taking full advantage of the underlying arrays they’ve invested in:
- 2–3x storage overhead across worker nodes.
- 3–5x network I/O amplification as each write is fanned out across the cluster, only to be deduped again by the array.
You pay twice: once in your Kubernetes cluster and again on the SAN.
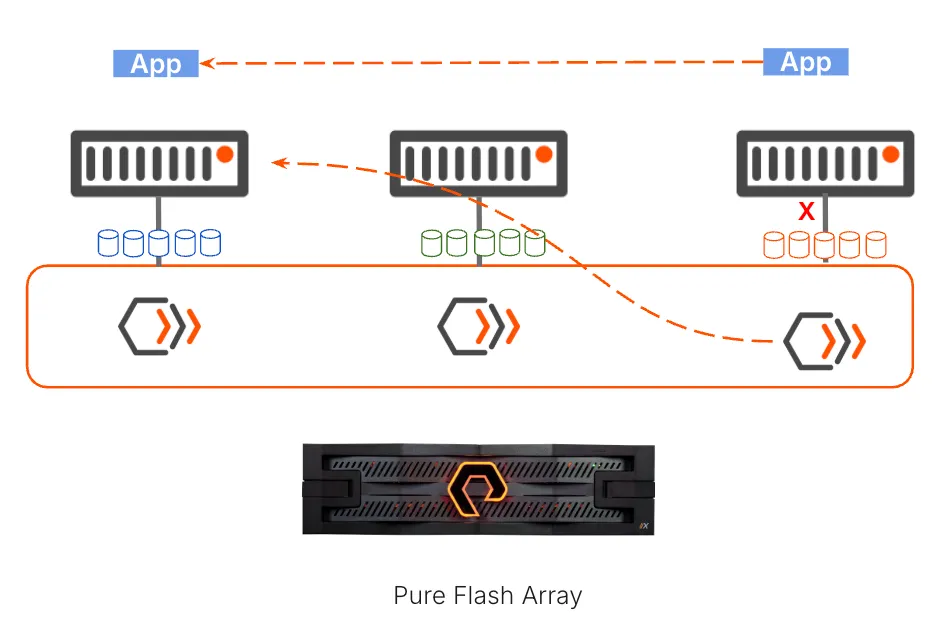
Kube Datastore (KDS), a new VM data architecture optimized for a cloud-native environment, is designed specifically to fix that mismatch. KDS aligns Kubernetes storage with the shared storage backend, letting you reuse the array’s built-in resiliency, high performance, data reduction, and failover behavior directly from Kubernetes.
At its core, a Kube Datastore is a logical grouping of Portworx storage pools carved from a homogeneous shared storage backend starting initially with Pure FlashArray, available in Q1 2026..
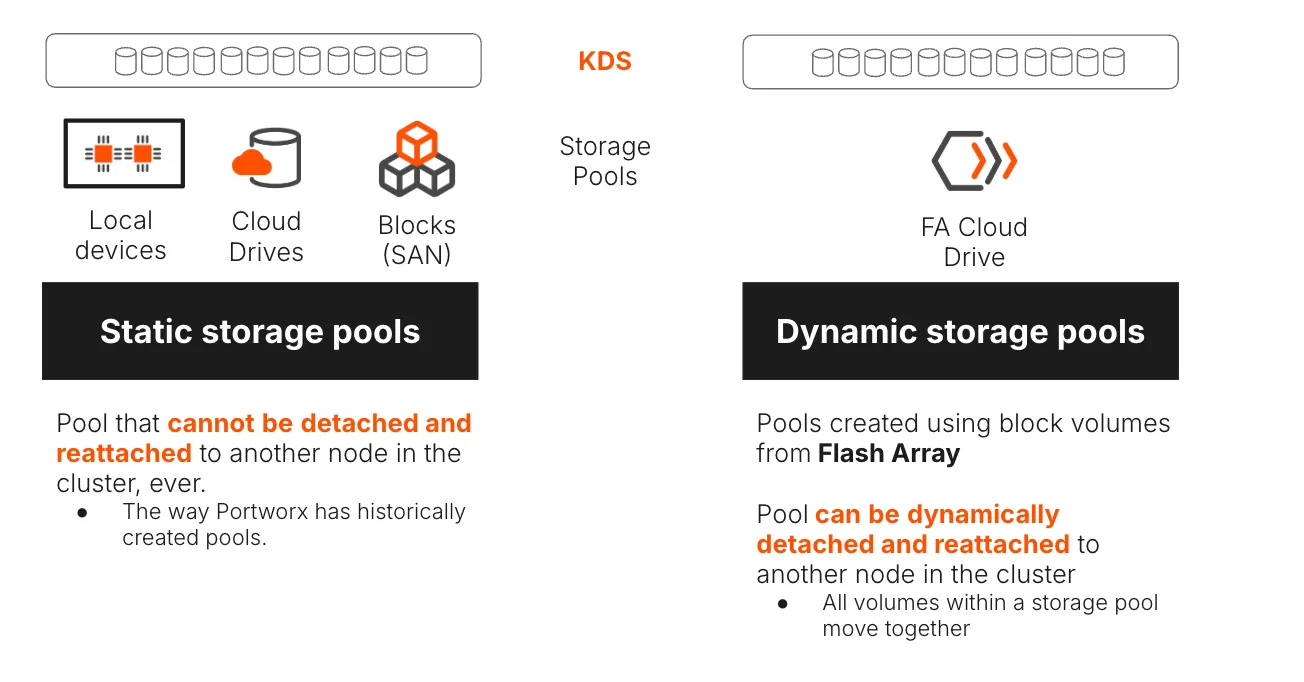
KDS: Support for both Static and Dynamic Pools
KDS supports both static and dynamic storage pools, giving operators flexibility to optimize for local performance or shared-array mobility depending on their application tier
- Static pools
- Created from local devices (e.g., NVMe in the node).
- Not easily moved between nodes.
- High availability is achieved via replication (repl2, repl3) across nodes.
- Ideal fit for lower tier applications that don’t have the same failover SLAs as tier 0 and tier 1 applications
- Dynamic pools
- Created from homogenous shared storage (FlashArray volumes, cloud drives, or SAN LUNs).
- Volumes can be detached from one node and reattached to another during failures or maintenance.
- Allow highly available repl1 volumes, because the backing storage itself is shared and can move with the workload.
A Kube Datastore is then built from one or more pools from the same backend—e.g., a set of FlashArray volumes grouped into a datastore that can be mounted by multiple nodes. All volumes in a pool move together, which makes failover and maintenance fast and predictable.
Why This Matters for VMs
- Familiar “datastore” semantics for VM disks, not just raw PVCs.
- Fast failover without data copy: detach/reattach of pools instead of re-replicating data across nodes.
- Better efficiency by offloading resiliency and data reduction to FlashArray instead of duplicating it in Kubernetes.
In other words, KDS gives VM admins something that feels like a traditional VM datastore but is implemented in a Kubernetes-native way.
Advanced VM Workflows: Familiar VM Operations built on Kubernetes
Building on Kube Datastore, Portworx introduces a suite of VMware-style workflows natively integrated into Kubernetes.
1. Enhanced Storage Migration – Storage vMotion for KubeVirt
Enhanced Storage Migration is designed for scenarios where VM disks need to move to a different storage backend—new arrays, retiring hardware, or performance tiering—without VM downtime.
What it provides:
- Non-disruptive VM storage mobility across Kube Datastores.
- Performance and capacity rebalancing by moving VMs to pools that better match IO profiles or free capacity.
- Granular control to migrate individual VM disks (not just entire VMs) based on workload needs.
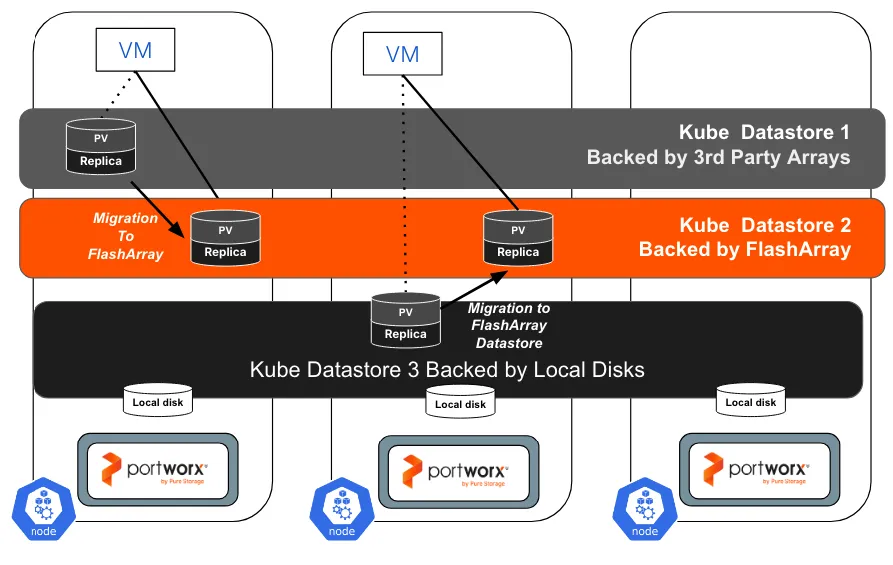
From a VMware admin’s perspective, this parallels the functionality and workflow of Storage vMotion but implemented in a manner that leverages Kubernetes and the storage context that Portworx provides.
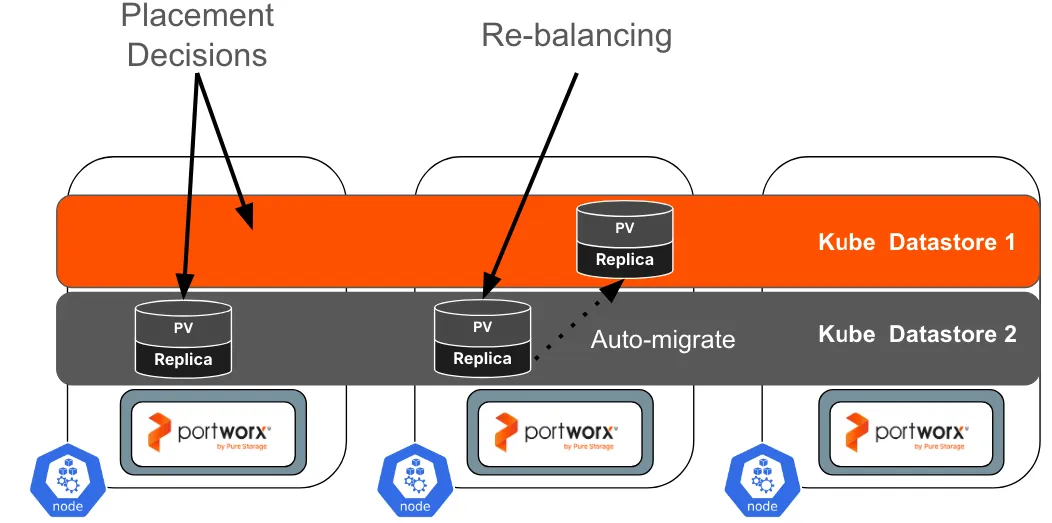
2. Automated Storage Rebalancing – Storage DRS for Kubernetes
Static placement decisions don’t work in the real world. Utilization and IO patterns drift over time. Real-world applications often see thousands of storage operations even for something as simple as a migration between two nodes, causing application slowdowns and other performance impacts Automated Storage Rebalancing continuously monitors datastore capacity, latency, and IOPS, and moves VM disks between Kube Datastores when thresholds are breached.
Key benefits:
- Policy-driven automation via Portworx Autopilot rules (e.g., rebalance when a datastore exceeds 80% capacity or crosses a latency threshold) drastically reduces manual overhead
- Continuous optimization rather than one-time placement decisions.
- Integration with KDS so that rebalancing is non-disruptive to running VMs.
From a VMware admin’s perspective, this functionality is conceptually similar to Storage DRS, but implemented with Kubernetes CRDs and policies instead of vCenter configuration.
3. Single File Backup & Restore
In traditional virtualization, recovering a single file often requires restoring an entire virtual disk—slow, inefficient, and disruptive. With Portworx Backup, administrators can now browse VM backups and restore individual files or directories without a full VM recovery.
This new Single File Restore capability introduces file system–level visibility within backed-up KubeVirt VMs, enabling granular recovery that’s both fast and secure. Users can restore files directly to a running VM or export them for external use, all with minimal overhead and full compatibility across common VM disk formats and file systems.
Key capabilities include:
- Granular restore of individual files or folders
- Restore to original or alternate locations
- Cross-platform compatibility with multiple file systems and storage backends
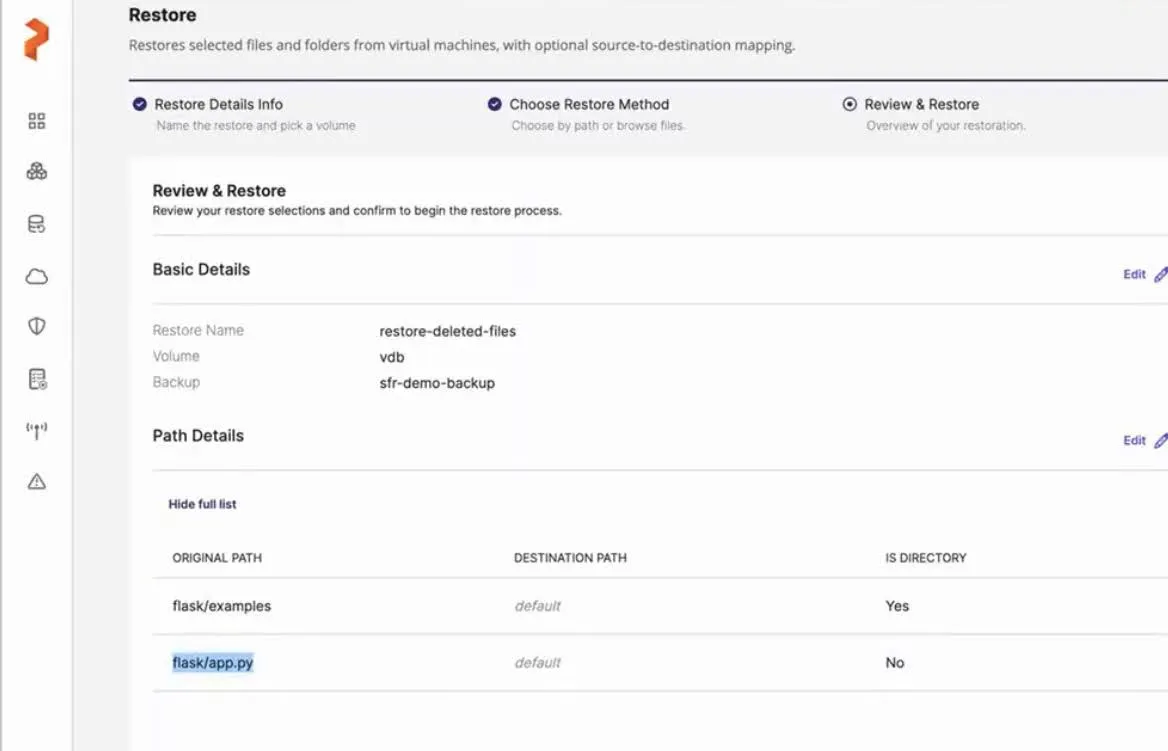
Whether it’s restoring a deleted config file, replacing a corrupted log, or extracting data for audit or debugging, Portworx Backup delivers the fine-grained recovery flexibility virtualization teams expect—now built natively for Kubernetes.
4. OpenShift UI Enhancements
We’re excited to introduce enhanced user interface capabilities that make managing storage for OpenShift Virtual Machines even easier. With the latest updates, users can now drill down to the individual VM level and access a dedicated Portworx tab directly within the OpenShift UI.
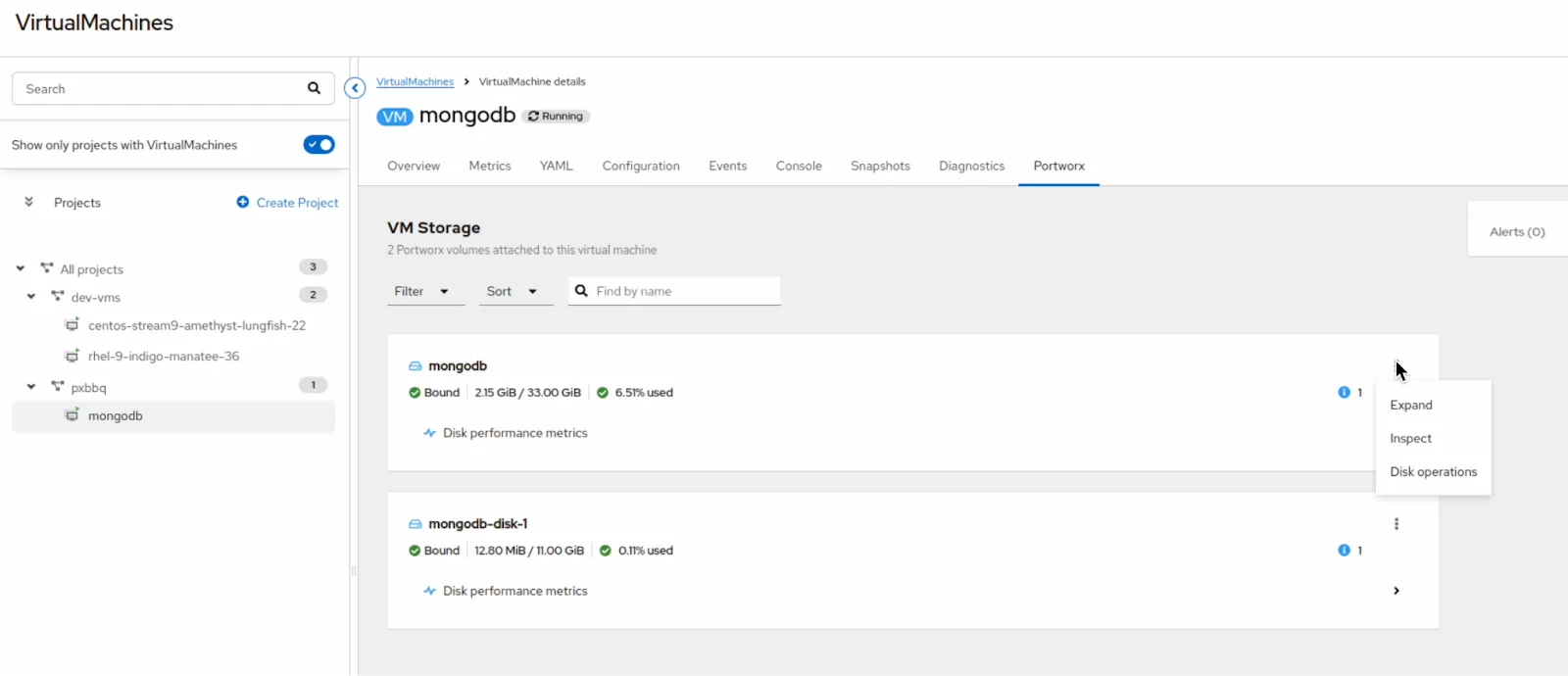
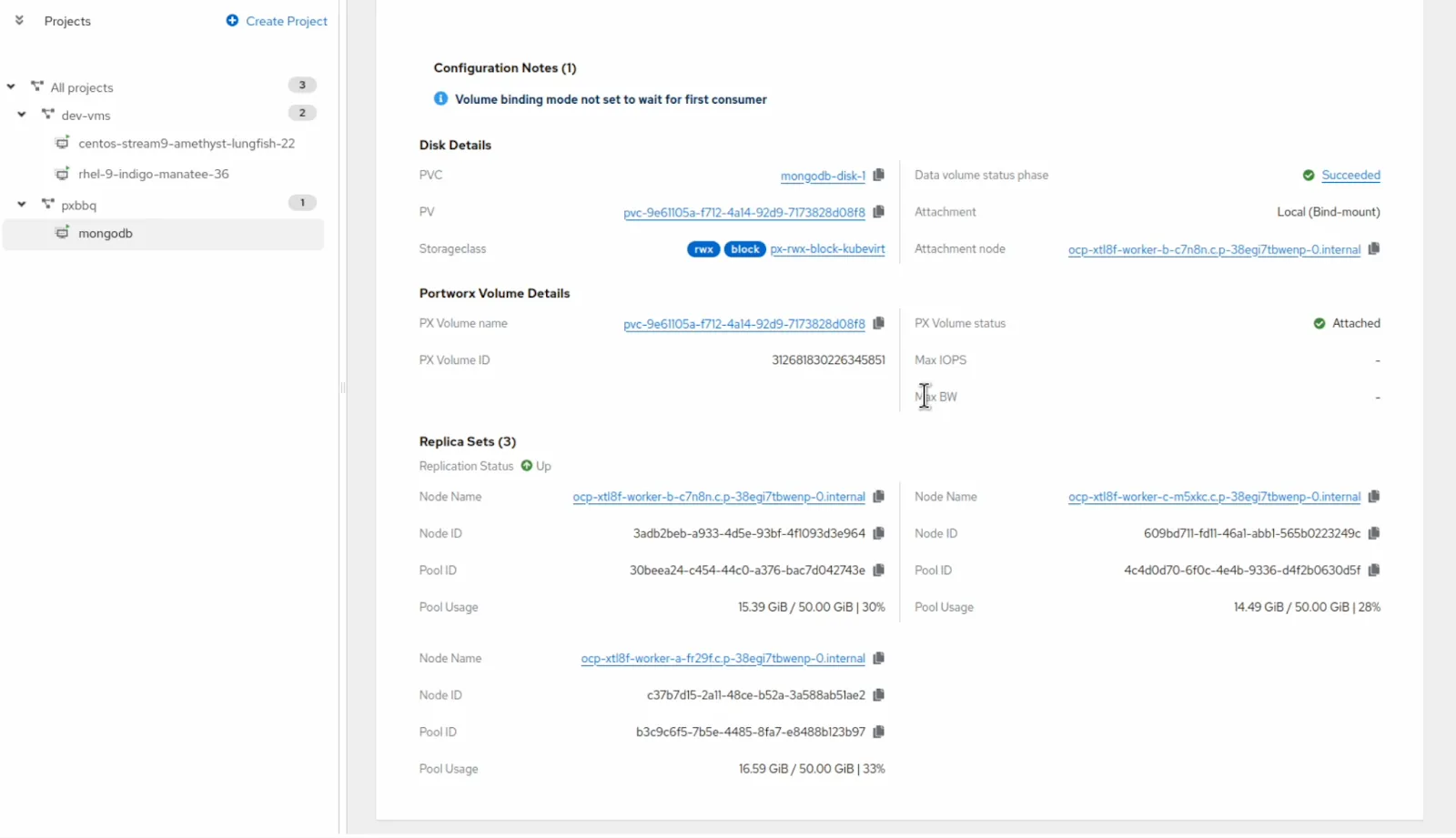
This new view provides deep visibility into the disks used by each VM, including details on the node, storage pool, replicas and live performance metrics. Even better, you can take direct action on disks from this streamlined workflow, making it simpler than ever to monitor, analyze, and manage storage for virtualized workloads.
Pure + Portworx Better Together: Rapid VM Migration for FlashArray
One of the most challenging steps in modernization is efficiently migrating existing VM data from vSphere into Kubernetes at scale. While Enhanced Storage Migration optimizes movement within Kubernetes, Rapid VM Migration accelerates the move from VMware to Kubernetes.
The Rapid FlashArray VM Migration capability—jointly delivered by Pure FlashArray and Portworx—offloads migration from ESXi hosts and the network to the FlashArray controllers themselves.
In a default Migration Toolkit for Virtualization (MTV) workflow:
- VMware’s VDDK copies data over the network from vSphere to the storage backing the Kubernetes volumes.
- Host CPU, memory, and network all take the hit.
With Rapid VM Migration:
- Pure uses array-native XCOPY to move data internally within FlashArray.
- Kubernetes volumes are populated without network-intensive host copies.
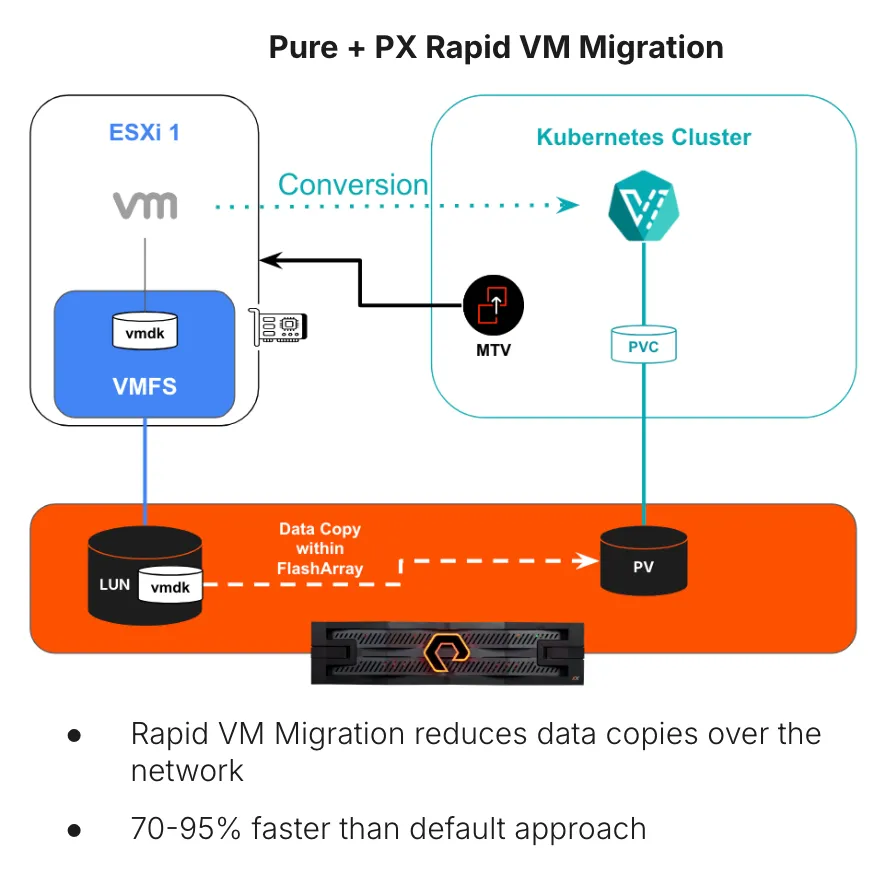
In internal testing, typical results yielded 70-95% faster migrations for large VM disks, dropping migration times by tens of minutes or hours when compared to default methods.
The practical impact: organizations can realistically plan large-scale VM migrations during controlled windows without risking migration window overruns or degraded service.
Conclusion
Together, these innovations—anchored by Kube Datastore—redefine what virtualization looks like in a cloud-native world. Built for KubeVirt, the Portworx platform delivers a unified, high-performance data layer across Kubernetes clusters.
By combining the reliability and predictability of traditional virtualization with the agility of Kubernetes, Portworx empowers enterprises to run VMs and containers side by side, at scale, under a single consistent platform.
Learn more about Portworx for Modern Virtualization and see it in action at our KubeCon 2025 sessions or join us for an upcoming Hands-on Lab.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!



