



Enterprises have to constantly adapt and evolve their enterprise architecture strategies in order to deliver the desired business outcomes. The evolving architecture patterns may involve business processing of sales transactions with a human in the loop or they may involve machine to machine data processing using automation. Enterprises earlier adopted a request-driven model where microservices made a call to a service and the service responded to the request being made. In this request-driven model, you run into challenges around flexibility as you try to scale your global deployment footprint.
A new approach, that is quickly gaining adoption in enterprises is called the event-driven architecture. In the new approach, you are able to increase application agility and flexibility by allowing for multiple data producers to coexist with multiple data consumers and you process data only after an event or state change. In this enterprise architecture, the producers and consumers of data can be quickly extended to deliver better flexibility and agility as you scale your operation globally. Examples of event-driven solutions are available in a hosted managed format from most cloud providers today. In this blog post, we will look at a Kafka solution running in a Kubernetes cluster and how you can make sure persistence is achieved for the solution. This approach is running at customers in production today supported by Confluent and Portworx.
With the advent of 5G technology, a vast amount of data will be generated by sensors, devices, systems, and humans in the loop to track, manage and achieve business outcomes. The use case for Event-Driven architectures may include the following:
Apache Kafka is a scalable, fault-tolerant messaging system that enables you to build distributed real-time applications with an event-driven architecture. Kafka delivers events, with fast ingestion rates, and provides persistence and in-order guarantees. Kafka adoption in your solution will depend on your specific use-case. Below are some important concepts about Apache Kafka:
Kafka needs Zookeeper to be deployed as a StatefulSets in Kubernetes. Kafka Brokers, which maintain the state of the topics and partitions also need to be deployed as StatefulSets which should be backed by persistent volumes.
Let’s walk through a Kubernetes node failure scenario on a Kubernetes cluster where a Kafka application is running and is backed by Portworx volumes.
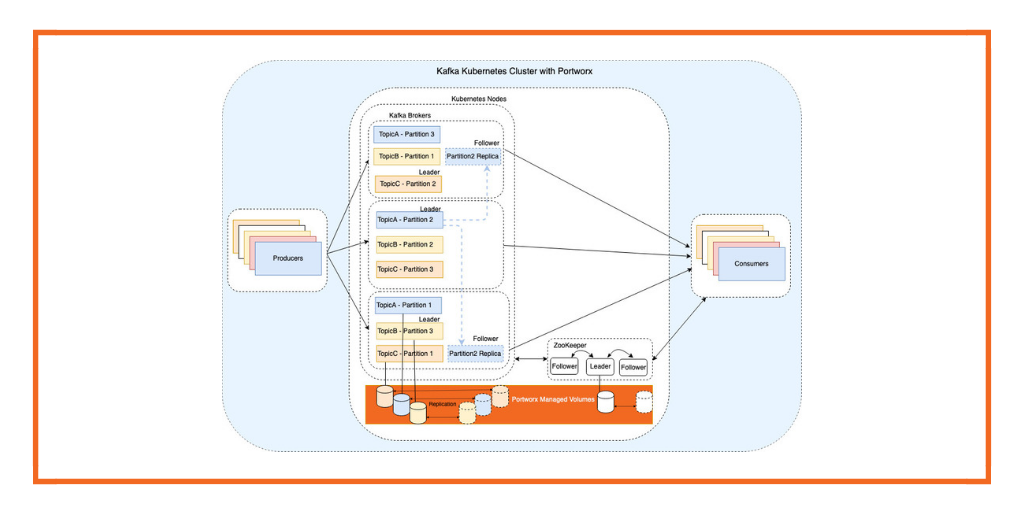
Figure 1: We will describe the deployment of Kafka and Portworx on a 5 node Kubernetes cluster. In the image below, you can see that the Kafka deployment has 3 Brokers, each with 2 partitions and a replication factor of 2. For the Portworx data platform, we have volume replication factor set to 3 for each volume.
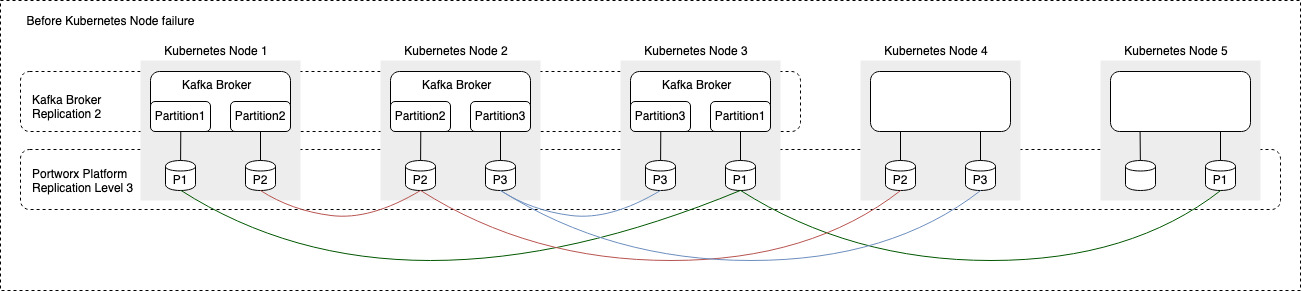
Figure 2: We will describe a node failure event. In the diagram below, we have simulated a node failure and identified the Kubernetes worker node 2 has been taken out of production. Kubernetes worker node 2 contains a Kafka broker with 2 partitions and 2 Portworx persistent volumes.
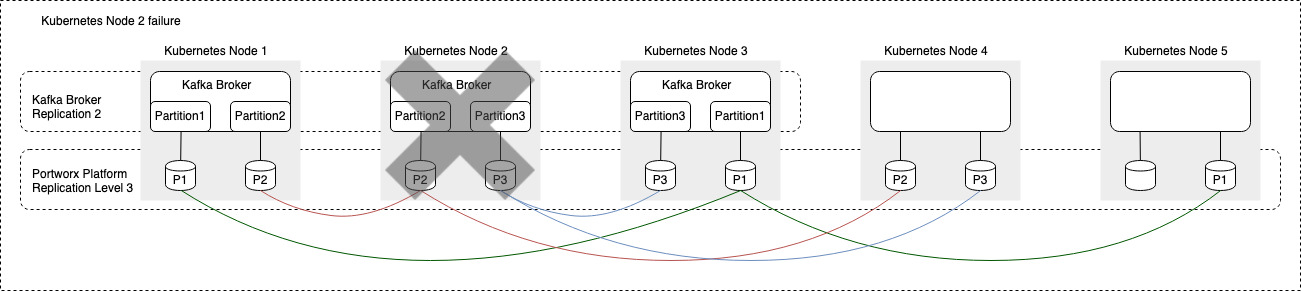
Figure 3: Once Kubernetes node failure is detected by the Kubernetes API server, the Kaffka broker is deployed to a node with available resources. The Portworx Platform has the ability to influence the placement of the broker on a Kubernete node. Since Kubernetes node 4 already has a copy of Kafka Broker’s persistent volumes, Portworx makes sure that the Kafka broker is deployed on Kubernetes node 4. On the Portworx platform’s recovery side, the volumes are also created on other nodes in order to maintain the defined replication factor of 3.
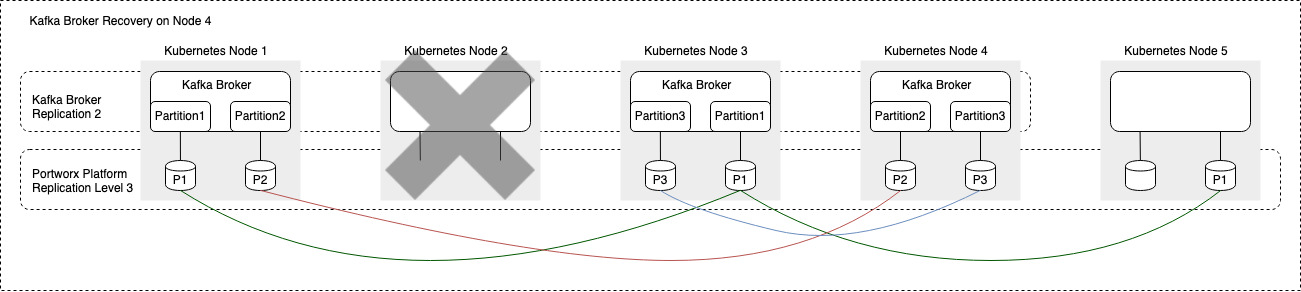
Figure 4: Once the failed recovery node is back in production use, the Kaffka application does not get scheduled on the recovered node since the application is already at the desired number of Kafka brokers. On the Portworx platform side, replicated volumes are placed on the recovered Kubernetes node to maintain the desired replication factor for the volumes.
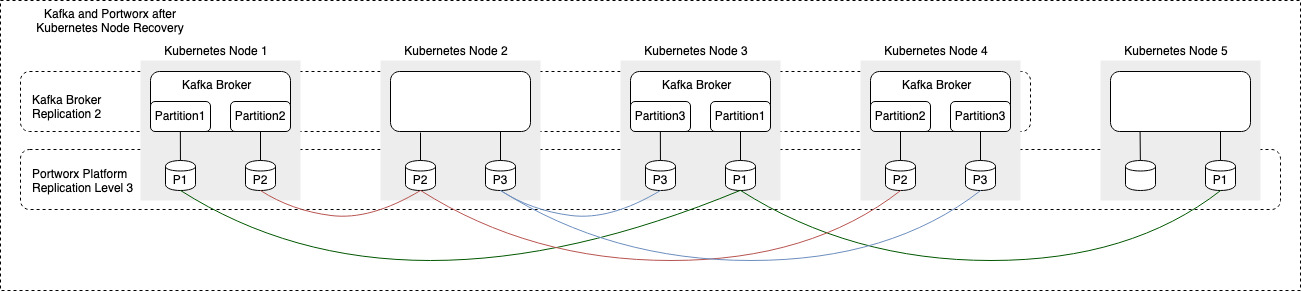
The Portworx platform can help speed up recovery of Kafka broker after it is rescheduled on a different Kubernetes node. You can learn more about running Kafka on Kubernetes with Portworx on various Kubernetes distributions here. For vendor-backed Apache Kafka, Portworx is working with Confluent to verify the integrations mentioned here.
If you have questions about how Portworx Enterprise can help your organization with data protection and data portability when running on cloud native container orchestrators, please reach out to one of our Portworx experts and request a demo.


