




When it comes to choosing your Kubernetes backup and restore strategy or designing a disaster recovery solution, there are varying levels of business and technical requirements to consider. To help you better understand these differences, we’ll walk you through what we think Kubernetes backup and restore should contain and how it compares to what Kubernetes disaster recovery should provide. Ultimately, we’ll explain why it is often necessary to have both for proper data protection.
Let’s begin with some really useful definitions provided in this article written by writer Siobhan Climer of Mindsight.
“Disaster Recovery (DR): A strategic security planning model that seeks to protect an enterprise from the effects of natural or human-induced disaster, such as a tornado or cyber attack. A DR plan aims to maintain critical functions before, during, and after a disaster event, thereby causing minimal disruption to business continuity.”
“Backup: The copying of data into a secondary form (i.e. archive file), which can be used to restore the original file in the event of a disaster event.”
As you can see, these two strategies are not the same, even though they both provide vital solutions for protecting applications and data. Let’s dive into how these apply to Kuberenetes.
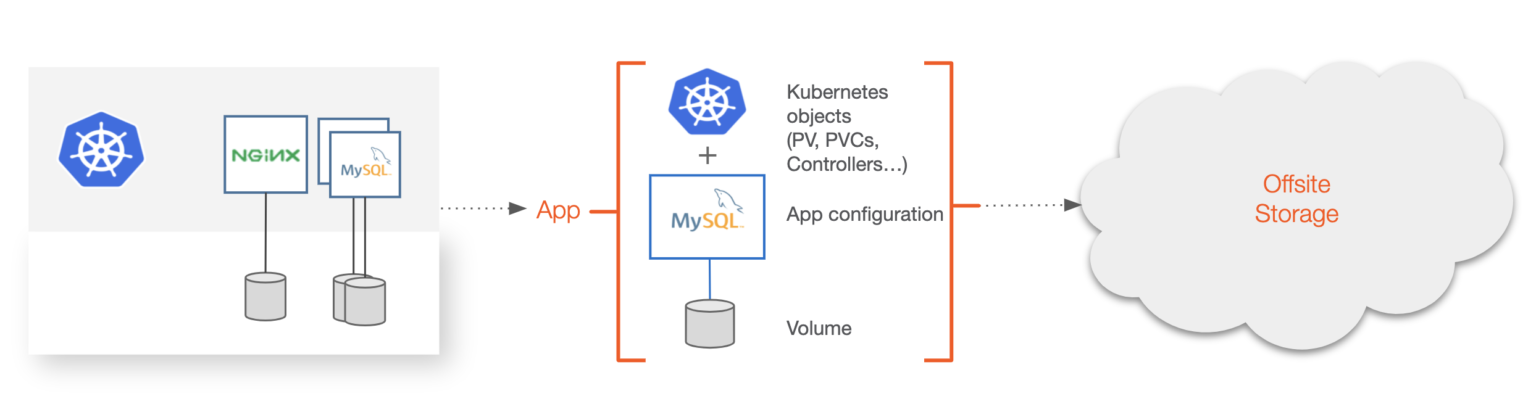
Backup and recovery for Kubernetes should be focused on the backup of the entire application from the local Kubernetes cluster to a secondary location, which is often offsite. A secondary location could be object storage in public or private clouds or storage available on-prem in different regions or failure domains. Backup solutions can also have multiple backup targets and are often configured to protect from system failure or to complete a compliance or regulatory checklist for an application. When it comes to understanding what a “backup” is for Kubernetes, it means that the backup software is able to understand the semantics of what makes up the application, such as Kubernetes YAML resources—e.g., secrets, service accounts, stateful sets, CRDS, app config—and persistent data as one. Only backing up data is not sufficient for a Kubernetes-level backup.
Backup and restore for Kubernetes should contain the following:
See Kubernetes Backup Tools: Comparing Cohesity, Kasten, OpenEBS, Portworx, Rancher Longhorn, and Velero for an overview of Kubernetes backup options.
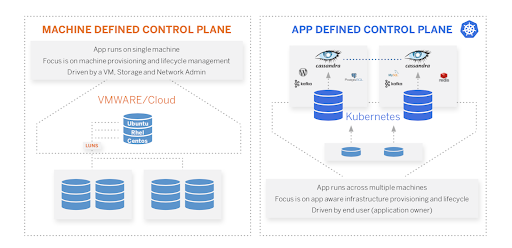
First, let’s define “traditional.” What we mean by this is a system that is focused on the hypervisor and server layers, not the microservice layer. These systems are in no way useless; however, they cannot be dropped into a Kubernetes environment and expected to work seamlessly. These systems typically operate at a higher-level object, such as a virtual machine (VM) or server. While systems that target VM and server-based workloads are valuable, they do not translate well to Kubernetes. Targeting the VM, server, or disk the application is using is not enough anymore—the backup system must understand these differences. Kubernetes-focused solutions still need certain aspects of traditional backup systems, though, such as schedules, jobs, retention, encryption, and tiering.
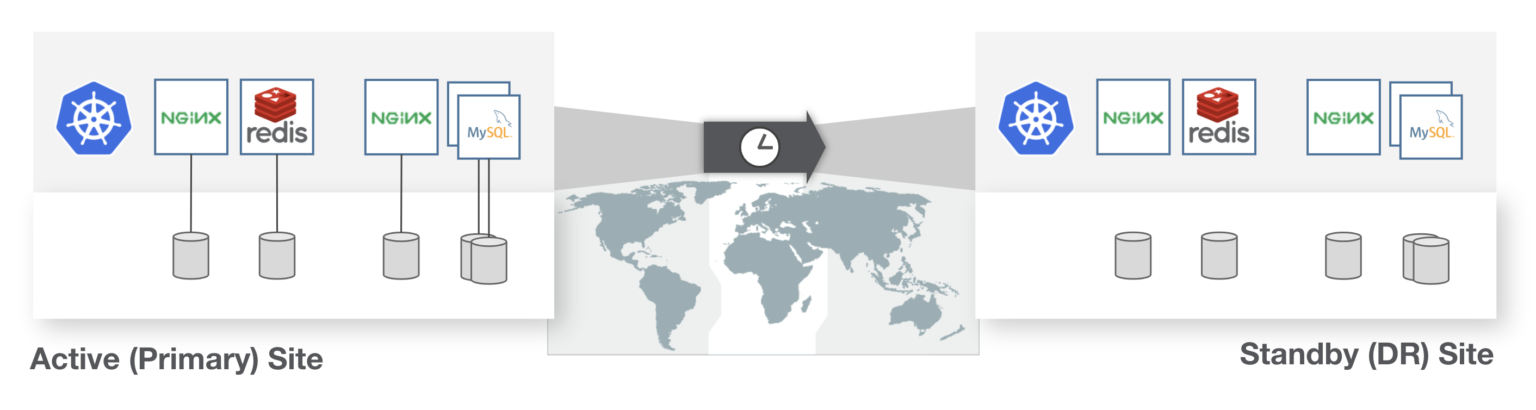
Disaster recovery (DR) for Kubernetes should focus on the nuances of recovery time objectives and recovery point objectives that translate to how much data loss and downtime a business critical application can endure while keeping critical functions available. DR disaster recovery solutions must also treat the Kubernetes YAML resources and persistent state as a single entity to protect from applications available from a primary site to a DR site. The DR system must also handle the varying levels of RPO and RTO and, depending on the cost and business requirements, protect at these different levels, such as including mechanisms for custom schedules and data replication configurations to meet the varying requirements.
One example of this would be Zero RPO. These are cases where applications cannot incur data loss or downtime. Another example would be low RPO, where requirements are a bit more relaxed and RTOs of hours may be suitable.
The DR system must also (to some degree) understand how the application is configured to be run in the recovery site. This means it should be able to understand metadata—such as labels or replica numbers—so the recovered application will start properly in the DR site without human intervention. If these types of Kubernetes APIs are not understood, this could lead to disjointed recovery and functionality and ultimately downtime or data loss.
DR for Kubernetes should contain the following:
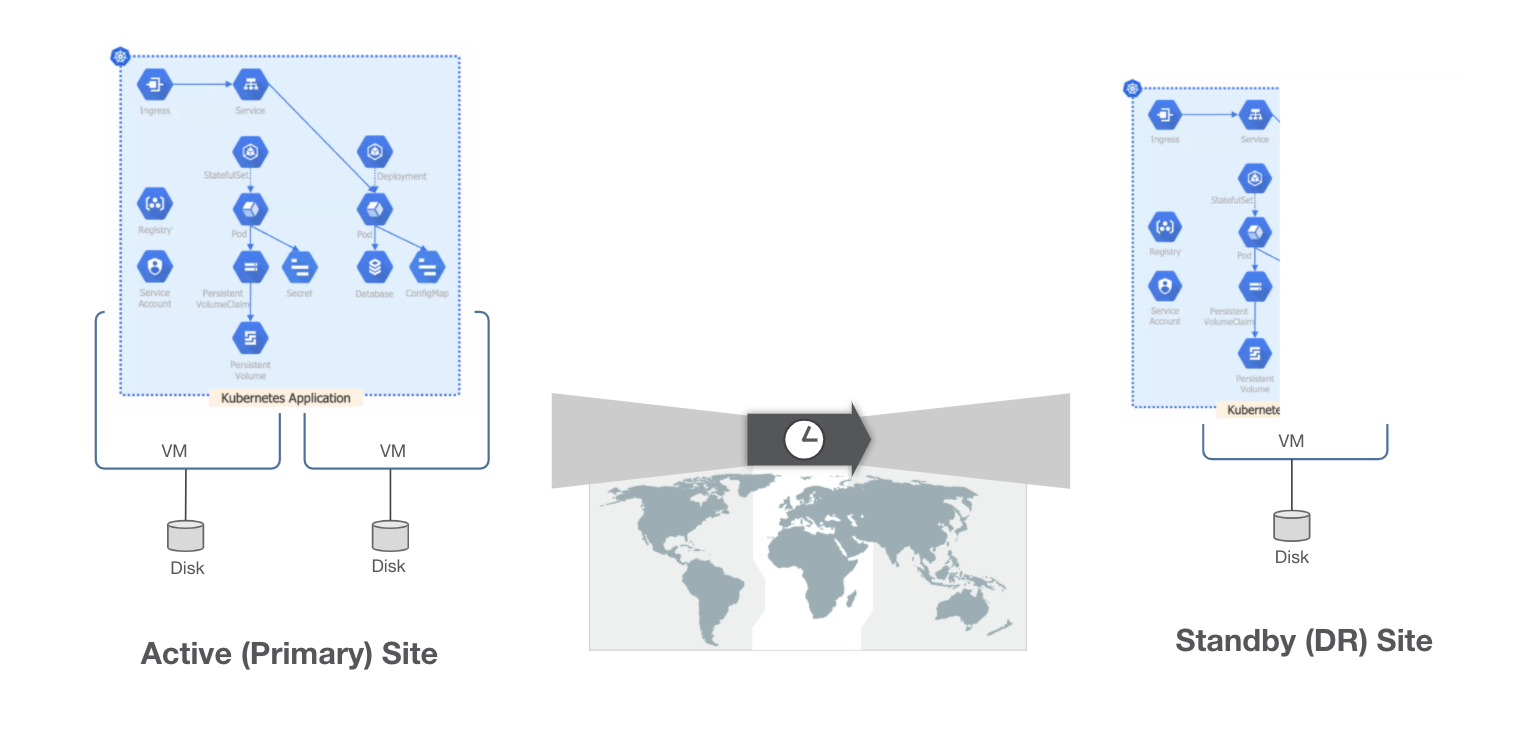
Disaster recovery in the era of Kubernetes and containerization means that traditional systems cannot target “an application” or “a namespace” in Kubernetes because moving a VM or disk from one site to another means there is no insight into whether that VM or disk has what an application needs. Abstractions in orchestrators today mean that DR solutions must be able to capture and move application metadata that the orchestration system can understand as well as link it to the persistent state the application may be using. Lastly, the DR systems must be able to bring those pieces up in the DR site as a cohesive unit. Systems that protect at the VM and Disk level miss the mark and need the finer details of what makes up an application on Kubernetes. DR for Kubernetes still needs many aspects of traditional solutions, though, such as schedules, witness procedures, and replication policies to attack RPO and RTO requirements from the business perspective.
Kubernetes is in production and is here to stay. Given this, applications on Kubernetes need proper backup and restore as well as disaster recovery when the business requirements call for it. Not all applications are the same, and not all budgets are the same, so it’s imperative that we understand the differences between what can be achieved with backup and DR techniques with Kubernetes. Kubernetes demands a new approach to application and data protection, and there are emerging technologies that can do this, including PX-DR and PX-Backup, but it is important to understand the application and business requirements first and apply the solutions you need.


