
We take great care to ensure our critical business transactions work properly. We build in redundancy for our applications, ensure our solutions are highly performant, and try to create a delightful user experience. But what about the moments after a transaction is committed? What level of effort is taken to protect those transactions after they’ve been stored? It’s important to strive for low or zero RPO, as any data loss can have serious consequences for a business and its operations.
In this blog, we’ll discuss how a Recovery Point Objective (RPO) is a critical component of any disaster recovery (DR) and business continuity (BC) plan and how Kubernetes presents challenges for organizations around DR/BC. RPO refers to the maximum amount of data that can be lost during a disaster before it affects application requirements, service level agreements, or regulatory requirements. In other words, it’s the point at which the organization or application can no longer function due to the amount of data lost.
To achieve low or zero RPO, organizations need to have robust disaster recovery and business continuity plans in place. These plans should include regular backups, testing of the recovery processes, and the use of storage replication to ensure that data is always available at multiple locations. Combined with proper compute, network, and storage sizing, organizations can achieve the same type of performance, resiliency, and availability of their applications and data inside Kubernetes that they have become accustomed to when using virtual machine-based or bare metal architectures.
Your organization expects their business transactions to be protected if disaster occurs. The list below represents five reasons why a low or zero RPO matters to your business.
While Kubernetes was originally meant to be stateless, stateful applications are now commonplace within modern application architectures. Organizations are incorporating stateful data within Kubernetes to eliminate the need for multiple infrastructure architectures to support their modern applications. Deploying virtual machine or bare metal infrastructure alongside Kubernetes infrastructures means multiple processes, procedures, and architectures are necessary to maintain high availability and protection of data and application services.
Enabling modern applications to consume stateful data within Kubernetes provides several benefits, such as:
When organizations choose to incorporate stateful data and applications into Kubernetes in order to reap these benefits, having options for different levels of RPO in the case of a disaster or infrastructure outage is critical. They can no longer rely on simple backup and restore operations in order to achieve availability of their stateful data. Solutions that lock organizations into a single cloud provider or location simply don’t provide the flexibility needed with dynamic infrastructure such as Kubernetes. To fully realize this flexibility, organizations require the capability to provide low or zero RPO solutions across multiple cloud providers, whether on-premises or in the public cloud.
Historically, zero and low RPO solutions have been limited to the laws of physics and require less than 10ms of network latency between the two protected sites. They also require storage hardware from the same manufacturer in order to perform the synchronous or asynchronous storage replication that was necessary to support low or zero RPO capabilities. Solutions such as VMware Metro Storage Clusters, VMware Site Recovery Manager, and Microsoft Cluster Server all required similar storage hardware or attachment to the same storage hardware in order to take advantage of the low or zero RPO benefits they provided to an organization.
While this worked great for on-premises infrastructure where similar storage hardware was available, it created vendor lock-in for an organization that wanted to take advantage of these types of capabilities across multiple locations. This was great for the storage hardware vendors–it created situations where organizations were purchasing multiple storage devices from the same vendor in order to have access to common capabilities surrounding replication and data availability. But what happened when the organization wanted to expand to public clouds and create a multi or hybrid cloud platform for its applications?
Organizations that wanted to move to the cloud found out quickly that each public cloud provided similar yet different native storage capabilities that were available for them to use–and this limited the data availability and replication options that they were accustomed to in on-premises environments. Want to configure storage replication between on-premises and your public cloud provider? Good luck. Want to replicate data easily and efficiently between Amazon EBS volumes and Azure disks? Have fun. While niche solutions attempted to solve this problem, they became mash-ups that had to be independently managed and stitched together in order to become what organizations had become used to in on-premises infrastructure solutions. This has simply proven to be not good enough, especially for organizations or industries running mission-critical applications that require resiliency, availability, and flexibility in order to meet service level agreements and compliance regulations–with downtime leading to millions of dollars of lost revenue or fines.
The need to meet low or zero RPO for organizational or application data in public clouds has become a massive challenge due to geographic locations of cloud region facilities. While latencies between availability zones within cloud regions remain low enough to maintain synchronous replication capabilities, what if the entire region goes down? Is it possible to configure more advanced three-legged replication topologies that combine synchronous and asynchronous replication in order to have data available not only within a cloud region but also across the globe to another region at the same time?
While some solutions–such as Portworx Backup, Kasten K10, Commvault Metallic, and Velero–provide robust backup and restore, ransomware protection, and data protection capabilities, the bottom line is that these solutions do not address an organization’s needs surrounding low or zero RPO in multi or hybrid cloud environments. Backup and restore of persistent volumes and Kubernetes objects is simply not a robust disaster recovery or business continuity solution, especially in dynamic Kubernetes environments that are distributed across multiple locations and providers.
What’s truly needed to achieve these RPO goals is a common storage layer that can provide replication capabilities–regardless of the underlying physical storage devices–and something that provides multiple RPO options for the organization. This is where Portworx Data Platform comes in.
Portworx Data Platform consists of three main products–Portworx Enterprise (cloud native storage), Portworx Backup (Kubernetes data protection), and Portworx Data Services (Database Platform-as-a-Service).
Portworx Enterprise provides organizations with a common cloud native storage solution for their Kubernetes clusters as an abstracted data layer between the Kubernetes worker nodes and the underlying storage hardware. With Portworx Enterprise, you can present Fibre Channel LUNs from an enterprise storage array, local disks from a hyper-converged server, or cloud volumes from your cloud provider for Portworx Enterprise to consume, and you can still get the same consistent enterprise storage features across any Kubernetes cluster on any platform at any location.
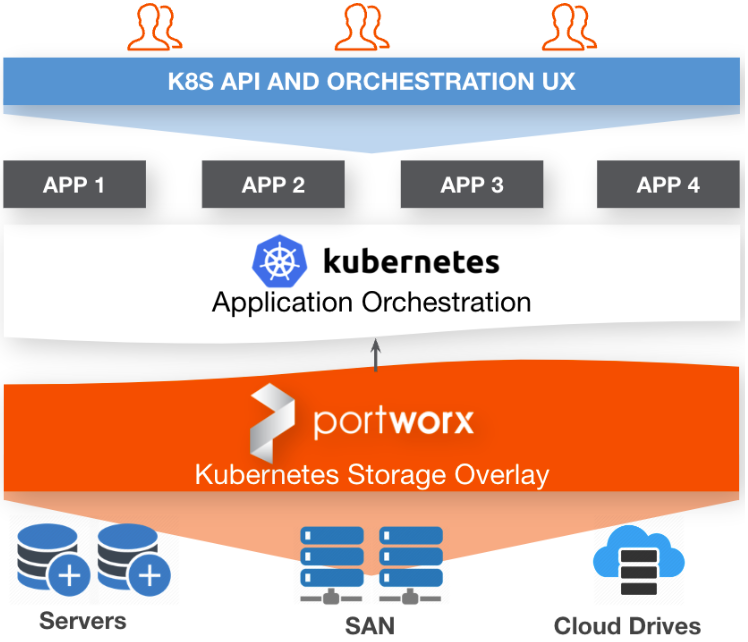
This solves a major challenge of vendor lock-in at the hardware or cloud layer, reduces your costs by using the hardware that is best for each location, and reduces staff overhead by preventing the need to learn multiple technologies, processes, and capabilities depending on the infrastructure being used.
One of the major features of Portworx Enterprise is PX-DR. It provides multiple synchronous and asynchronous replication capabilities for the persistent volumes used within your Kubernetes cluster, and it can replicate any Kubernetes objects associated with the applications using those persistent volumes–such as configmaps, secrets, deployments, pods, services, and more. There are currently two types of replication that PX-DR supports:
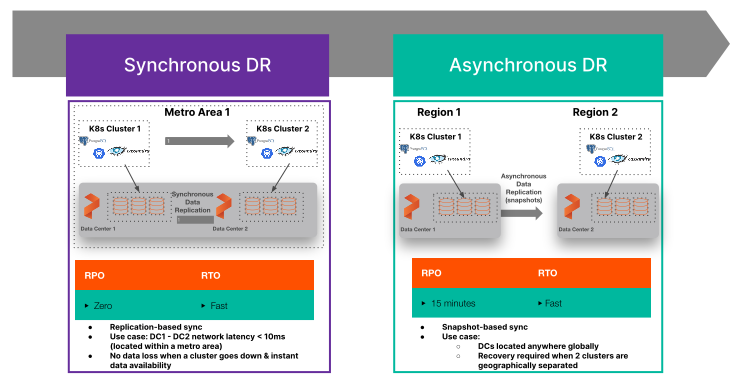
Using PX-DR allows you to configure synchronous and asynchronous replication topologies across on-premises, cloud availability zone, and cloud regions regardless of the cloud provider or location. You can even configure a Sync DR cluster for metro/AZ zero RPO solution and hang a “third leg” of asynchronous replication to another on-premises location on another continent/public cloud region for a “3DC” topology that is commonly used by mission-critical applications today in virtual machine or bare metal environments.
As we discussed earlier, establishing disaster recovery and the proper RPO for your data and applications are only two pieces of a comprehensive disaster recovery or business continuity plan. Performing regular, comprehensive backups of your applications and data, following the 3-2-1 rule (3 copies of your data on 2 different media with 1 copy off-site for emergencies), and taking immutable backups to mitigate ransomware attacks are critical requirements for any production environment. These, combined with a resilient and flexible storage layer with multiple replication and RPO capabilities, provide a comprehensive foundation for your Kubernetes persistent volume, replication, capacity management, data protection, and ransomware protection needs.
Portworx Backup delivers enterprise-grade point-and-click backup and recovery protection for all applications running on Kubernetes, even if they are stateless, and it supports a 15-minute RPO. Built exclusively for containerized applications, Portworx Backup protects your applications–data, application configuration, and Kubernetes objects–with a single click at the Kubernetes Pod, Namespace, or Cluster level. Portworx Backup provides native integration with major Kubernetes platforms and any storage system, including major cloud block storage systems such as Amazon EBS, Google Persistent Disk, Azure Managed Disks, any CSI-compliant File and Block storage, and Portworx Enterprise. Portworx Backup supports many enterprise features–such as ransomware protection, 3-2-1 backup, and RBAC support–and is available as a managed service with a cloud control plane or a self-managed on-premises Helm deployment.
Many Global 2000 Companies already use Portworx Data Platform to achieve resiliency, availability, and data protection needs for their modernized applications. This includes several major financial services and other industry vertical organizations that require low to zero RPO in order to keep their applications and data available at all times.
We’ve discussed quite a bit in this blog:
If you’d like to see how Portworx Enterprise Sync and Async DR work in action and how they can provide low or zero RPO, please check out our YouTube videos:
Portworx Enterprise has a free 30-day trial edition as well as a feature-limited, free forever version if you’d like to try it out for yourself. Simply head over to Portworx Central, sign up, and start using it today! If you need some guidance, check out our documentation site to help get you up and running.
If you’d like to see the capabilities of Portworx Backup and see our managed service in action, please check out our YouTube demo:
Portworx Backup has a free forever managed service version with up to 1TB of data capacity if you’d like to try out our data protection solution. It’s also located within Portworx Central and only takes a few minutes to create your own dedicated Portworx Backup instance for free. Again, if you need some guidance on using Portworx Backup, you can find information on our documentation site.
Using the PX-DR feature of Portworx Enterprise allows you to maintain a low or zero RPO on any Kubernetes cluster running on any cloud at any location. By taking the necessary steps to achieve a zero to low RPO, you can safeguard against potential disruptions and losses–especially for mission-critical data and applications. By combining PX-DR with Portworx Backup, you have a solution from a single vendor that can provide comprehensive resiliency, availability, and protection of your modern applications and data when running on Kubernetes.