



DevOps methodologies have remarkably improved our agility, enabling rapid development, deployment, and transformation of our applications. By fostering collaborative environments, breaking down silos, and automating deployments with CI/CD pipelines, we’ve learned how to rapidly iterate on our applications in response to changing conditions. Containers were also a big improvement for agility, allowing us to move our applications anywhere a container can run. But our data cannot be easily redeployed, moved to another cloud/datacenter, or automated. Because our data can’t be redeployed from a git repository like our apps can, Platform Engineers need to leverage storage solutions capable of reacting to an unknown future without being re-architected, all while being protected from threats. Put another way, our storage needs to be dynamic yet secure so that our agile applications aren’t constrained by the data they create and consume.
We know certain obstacles will be thrown at our applications over their entire lifetime. What areas can we plan for when deploying our applications with persistent storage? Let’s look at each of the topics individually.
Platform Engineers understand that failures are inevitable. Hardware malfunctions, power outages, or operating system faults can cause an interruption of service. These failures are inevitable, so redundancies are built behind load balancers to manage a temporary outage. Just as applications are built with redundancies, data storage solutions must provide resiliency and high availability across data centers, ensuring uninterrupted access to critical data.
Accurate capacity planning is a challenge, and requirements can change unexpectedly. Platform Engineers need to account for what happens when the original capacity estimates are no longer accurate. When it comes to applications, Platform Engineers can leverage autoscaling solutions to handle increased traffic. The storage layer should also be able to automatically expand to account for additional storage requests and capacity management.
Containers have made mobility a real possibility for Platform Engineers. Applications, packaged into a sleek container form factor, can be run on any container host in any environment available. This is a tremendously powerful capability for teams who manage applications, but the storage for the applications should also be dynamic enough to be moved around. Without a way to move the storage between environments, the portability of the applications becomes limited to wherever it can access the data. Platform Engineers need a dynamic storage solution that can move workloads and the data associated with them between environments when requirements change.
It’s an operations team’s worst nightmare. An unplanned datacenter outage with an unknown time to resolution (TTR). All the applications that are critical to the business need to be brought back up at another site as quickly as possible. Just like with mobility, applications might be simple to redeploy, but the data needs to be brought along, as well. Platform Engineers need a storage solution that will replicate persistent data offsite or between clusters so that it can be brought up in an emergency. Ideally, this replication can be enabled easily through an Internal Developer Platform.
The entire application and its deployment code are stored in version control and managed through GitOps these days. Not only can Platform Engineers redeploy the applications if something accidentally gets deleted, but they can even deploy different versions of our application. The data, of course, can’t be redeployed. The data needs to have a solution that can not only backup the data, but also store it offsite in case something happens. Platform Engineers need a dynamic backup solution that can automatically protect new applications even if they’re redeployed, and store the backups off-site for added protection. Platform Engineers may also look for solutions that can offer self-service restoration capabilities so that developers can restore their own environments.
Applications often come with role based access controls (RBAC) built in. About every website you visit has an option to login to save your personal preferences in a profile. We depend on RBAC to ensure that everyone doesn’t have access to your personal information. But at the storage layer we need a mechanism to make sure only authorized applications can access the persistent data they need to use. Platform Engineers have to ensure that the storage resources deployed are secured from other applications, purposefully or accidentally mounting their data.
Data encryption is fundamental to a storage solution and should be used in almost all situations. Developers use TLS to protect the network traffic to our applications because we know there are entities looking to sniff our connection strings. Platform Engineers need to also encrypt data when it is at rest so we can ensure that data can’t be accessed without having the proper encryption keys. Platform Engineers need this capability without adding a lot of overhead to managing encryption keys across environments.
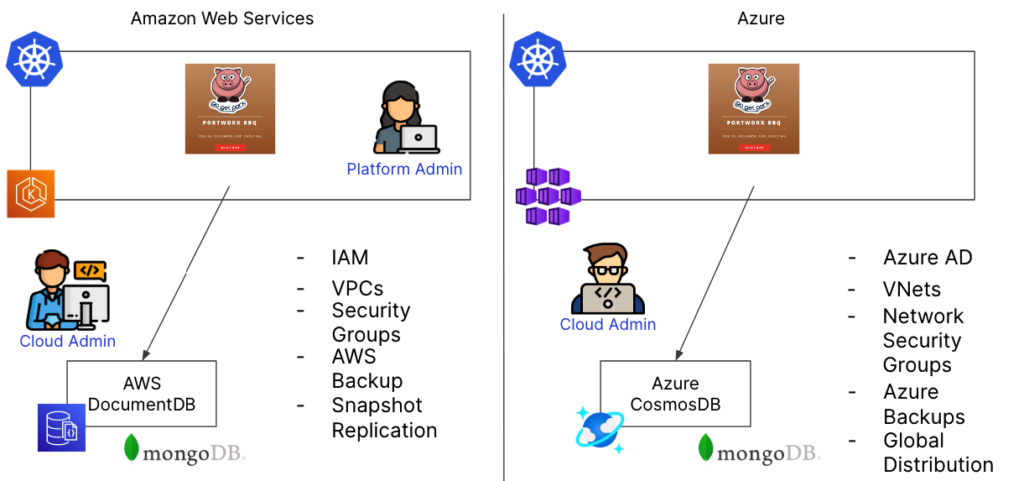
The capabilities discussed in the previous sections might seem overwhelming to some people. Face it, we’ve discussed a bunch of capabilities that need to “just work” without adding too much complexity or technical debt to the deployment pipelines. It might feel like the solution to this problem is to outsource all these functions to a managed service solution from a cloud provider. Managed databases might seem like the perfect solution to ignore having to figure out high availability, capacity planning, disaster recovery, authorization, or encrypting data, but these same issues still exist for managed solutions. It might seem like all you’d have to do is add a line to a config file to enable these capabilities from a managed service, but for Platform Engineers who are placing these services behind an Internal Developer Platform, these all become customizations that have to be managed. If the organization uses ten different database flavors for their applications, Platform Engineers likely have to figure out how 10 different managed services work before they can be made available. Of course, if they’re in two different clouds, that becomes twenty different managed services to figure out. And a managed service like a hosted database isn’t the only thing that needs additional thought. Using a managed service from a cloud provider might mean you have to make changes to your Identity and Access Management (IAM) procedures, or get creative with how you connect your virtual networks to your managed services, and each one of those services might have a different disaster recovery method that needs to be maintained. This puts a high load on the Platform Engineering team to manage all of these options.
Platform Engineering teams are trying to provide the services that development teams want, while working with the constraints put in place by governance teams who are tasked with managing costs or compliance. The more bespoke solutions that are added, like individual managed database services, the more work that’s required to maintain them and takes their time away from adding other pressing features that are being requested of them.
Platform Engineers are heavily using Kubernetes as a platform to run their containerized applications, and the primary reason is that it’s a consistent platform no matter where it’s been deployed. It comes with its own set of capabilities, such as availability, load balancing, secrets management, service discovery, etc. Platform Engineers can add these Kubernetes capabilities to their Internal developer platforms and leverage them across any environment. Portworx was built specifically for Kubernetes to add enterprise-level storage capabilities for a containerized environment that can all be managed by platform teams.
Portworx knows that your storage needs to be dynamic enough to handle agile applications deployed on Kubernetes. In the same way that Platform Engineers can count on Kubernetes capabilities always being available, they can count on Portworx capabilities to also be available across any infrastructure it’s running on.
High Availability is provided out of the box with Portworx Enterprise to ensure your data is always accessible, even in the event of a host or availability zone outage by making replicas available across topologies.
Capacity Planning becomes easier for platform teams by leveraging Portworx Enterprise’s Autopilot solution that can automatically expand volumes and storage pools when they are low on space (with guardrails to watch for run-away increases), and in conjunction with the Cloud Drives feature can be used to increase the total storage capacity for the cluster automatically as well.
Mobility is built into Portworx Enterprise through the PX-Migrate functionality. It’s assumed that you will want to move your data to another location because of changing business requirements, but also maybe you want to move your data around as part of your deployment pipelines to do integration tests.
Disaster Recovery is one of Portworx’s greatest strengths. Your applications and data may need to fail over to another location at any moment, and you need to be ready for this. Portworx can provide both zero RPO synchronous replication and low RPO asynchronous replication, depending on your use case needs. Portworx can then orchestrate the failover of your containerized apps and/or the persistent volumes that back those applications.
Data Protection is built in to all of Portworx’s products. Snapshots can be automated and stored on an external S3-capable bucket for restores later on. The Portworx Backup tool can also make sure that new applications are automatically backed up without additional intervention by users, and provides self-service access to developers to restore data when needed — taking further load off of the platform teams.
Authorization is a core capability in Portworx Enterprise ensuring that only the authorized pods deployed in a Kubernetes cluster can mount the persistent data for their solution. Other pods won’t be able to access these Persistent Volumes unless they’ve been granted specific access.
Encryption can be added to any persistent volume deployed in your Kubernetes cluster running on Portworx. It provides customers with the flexibility to use a unique secret for each encrypted volume, or enable it cluster-wide to ensure all data is protected.
Managed Databases are also possible using Portworx Data Services (PDS). If you’re in a situation where you just want to select a database type, deploy it, and have it work in a dynamic and secure manner, then try running your databases in Kubernetes with Portworx Data Services.
Your data isn’t as agile as your application deployment methodologies. As DevOps processes became more mature with companies, data management has remained relatively static. Platform Engineers need to find ways to make the storage layer dynamic so that it can respond to changing conditions securely without requiring a heavy lift from the platform engineering teams. Portworx provides dynamic and secure storage capabilities in Kubernetes so that Platform Engineers can add these capabilities to their Internal Developer Platforms once and run them anywhere.



