



Authors:
OpenShift 4 added installation and operational benefits for cluster admins and operations teams including the expanded use of Operators which automates the configuration, deployment and maintenance of Kubernetes-native applications. However, one topic that still remains a pain for OpenShift teams is how to achieve Disaster Recovery, Data Migration, and Data Protection in a DevOps friendly way. Cloud Native and DevOps solutions should include ease of configuration, APIs for automation and mechanisms to manage backup and recovery techniques in a Kubernetes-native way such that these concepts fit easily into existing pipelines and management. Today, this is hard to achieve with OpenShift alone, so we’ll walk you through a solution which combines best of breed orchestration from OpenShift 4.2 and data management from Portworx to achieve cross-cloud backup, restore and disaster recovery.
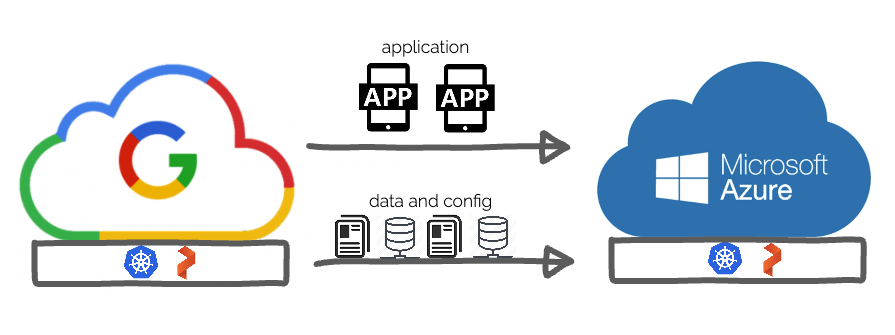
For our demo, we’ll be using two OpenShift 4.2 clusters, one deployed in Microsoft Azure in the US West region and the other deployed on Google Cloud Platform(GCP) in the US East region. Our primary cluster will be the one running in GCP and we want to set up backups and migrations of our applications over to Microsoft Azure in the US West region which helps to protect from two main things.
Historically this has been a very complex problem to solve because we are dealing with application and cloud attributes and concerns such as the following examples.
Being able to abstract these cloud specific items is key, and we can achieve this by running a cloud native Kubernetes distribution such as OpenShift. OpenShift still needs cloud specific setup, but once setup, applications running on it can deploy on top of Kubernetes and have common objects for LoadBalancing, Secrets, Metadata and more. This helps us run applications on Azure or Google, however, data will still be stored separately. This is where it is also critical to run Portworx which gives you the same common abstraction for storage that Kubernetes gives you for applications. Using OpenShift and PX-DR and Backup solutions, we can achieve cloud-agnostic migrations for your Kubernetes applications that use storage.
Let’s dig in.
In the image below we can see two OpenShift deployments, one in Google Cloud Platform (left) and the other Microsoft Azure(right).
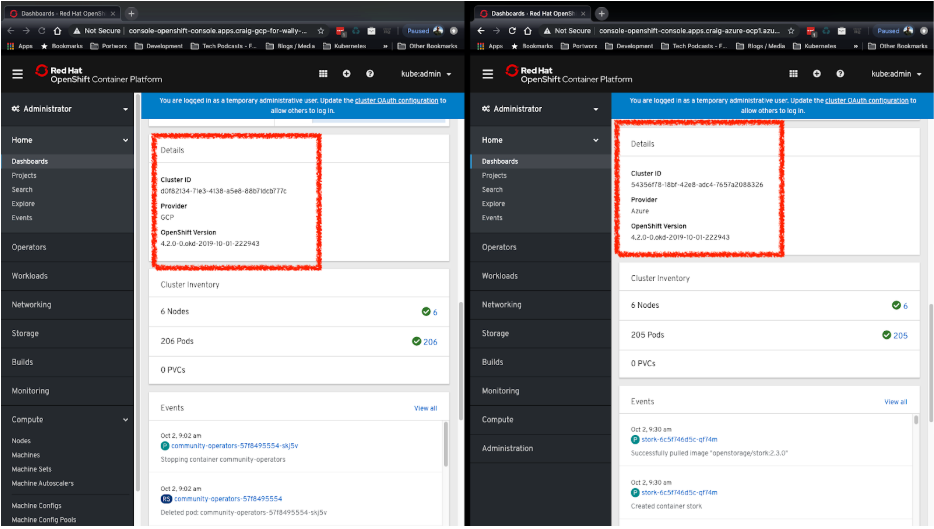
These clusters were set up using openshift-install, OperatorHub, and PX-Central. openshift-install is a Terraform-based utility provided by RedHat which allows you to quickly provision a working OpenShift cluster. In the latest version of openshift-install, OpenShift 4.2 can be provisioned in AWS, GCP, and Azure. We used this tool to quickly provision two clusters, one in GCP and one in Azure. Provisioning an OpenShift cluster is as easy as running this one command:
$ openshift-install create cluster
For each cluster, we used the OpenShift UI to install the Portworx operator from OperatorHub:
After that, we used the PX-Central Spec Generator to generate StorageCluster specs for each cluster.
On each cluster, in the section of the Openshift UI for the Portworx Operator, we used the Create Storage Cluster option entered the spec to provision Portworx:
Once Portworx is ready to go, we installed a few applications in our primary OpenShift cluster running in GCP. These applications are a MySQL database, a Postgres database and a web application that allows users to click on the screen while it stores coordinates of the clicks as data in the aforementioned Postgres database. We’ll be using these applications to showcase the backup and restore process of our migration from GCP to Azure.
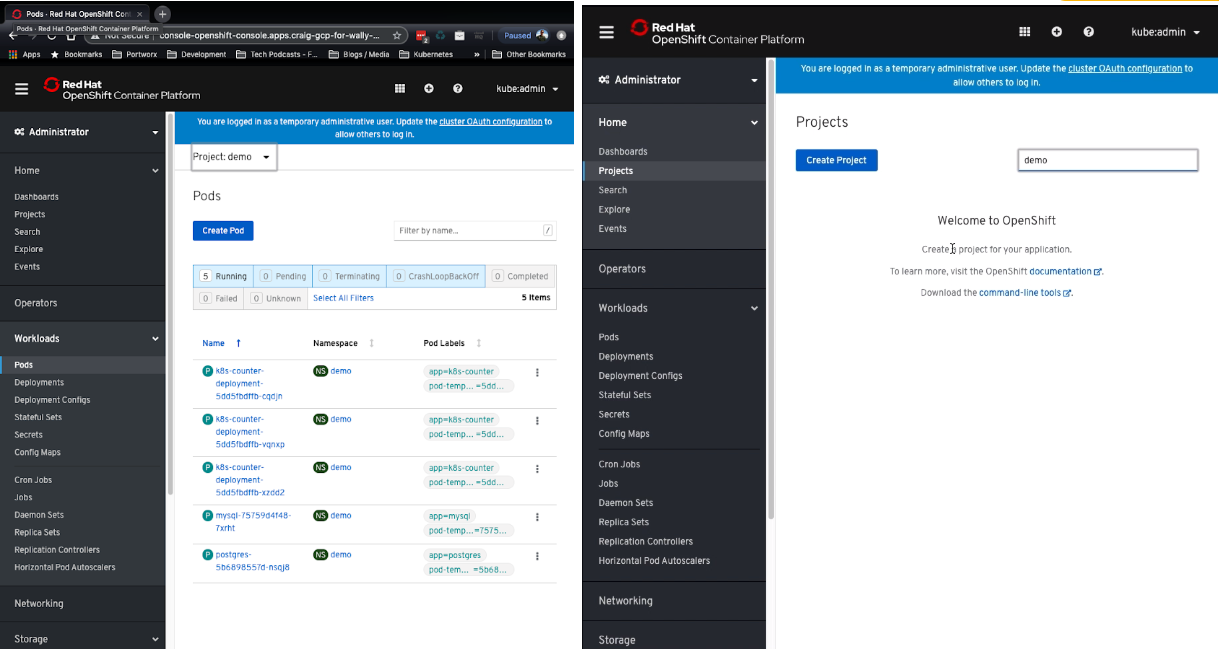
From the Pods view in the demo namespace you can see these applications running on the left hand side which is our GCP OpenShift cluster, on the right is our Azure cluster which shows there are no active demo namespace or pods. This is what we want as we have not initiated any movement of data or applications yet.
In order to migrate applications from one OpenShift cluster to another, we will need to create a Portworx cluster pair. Cluster pairs tie the storage and application ends of two separate clusters together so they have a way to move from one to the other. Read more about setting up cluster pairs in the Portworx documentation. Below, we can see that we have a cluster pair setup up called “remote-azure” which connects to our Azure cloud.
GCP: storkctl get clusterpair -n demo NAME STORAGE-STATUS SCHEDULER-STATUS CREATED remote-azure Ready Ready 02 Oct 19 12:19 EDT
We’ll be using recurring backups so we can run backups on a schedule. Once the clusters are paired, you need to configure a few things in order to set up recurring backups. The first is a SchedulePolicy.
$GCP: cat migration-schedule.yaml apiVersion: stork.libopenstorage.org/v1alpha1 kind: SchedulePolicy metadata: name: migration-policy namespace: demo policy: interval: intervalMinutes: 15 daily: time: "10:14PM" weekly: day: "Thursday" time: "10:13PM" monthly: date: 14 time: "8:05PM"
The next thing is a MigrationSchedule which connects the specified policy above to a migration which targets applications. In this case, we will target the entire demo namespace and include our volumes but we wont start the applications on the Azure cloud, we’ll run that manually.
> Pro tip. You can include “selectors:” under the “namespaces:” parameter if you only want to migrate certain resources within a namespace such as a label on a specific PVC and using that to select just one PVC instead of everything in the namespace.
$GCP: cat migrate-demo-ns.yaml apiVersion: stork.libopenstorage.org/v1alpha1 kind: MigrationSchedule metadata: name: demo-migration-schedule-to-azure namespace: demo spec template: spec: clusterPair: remote-azure includeResources: true startApplications: false includeVolumes: true namespaces: - demo schedulePolicyName: migration-policy
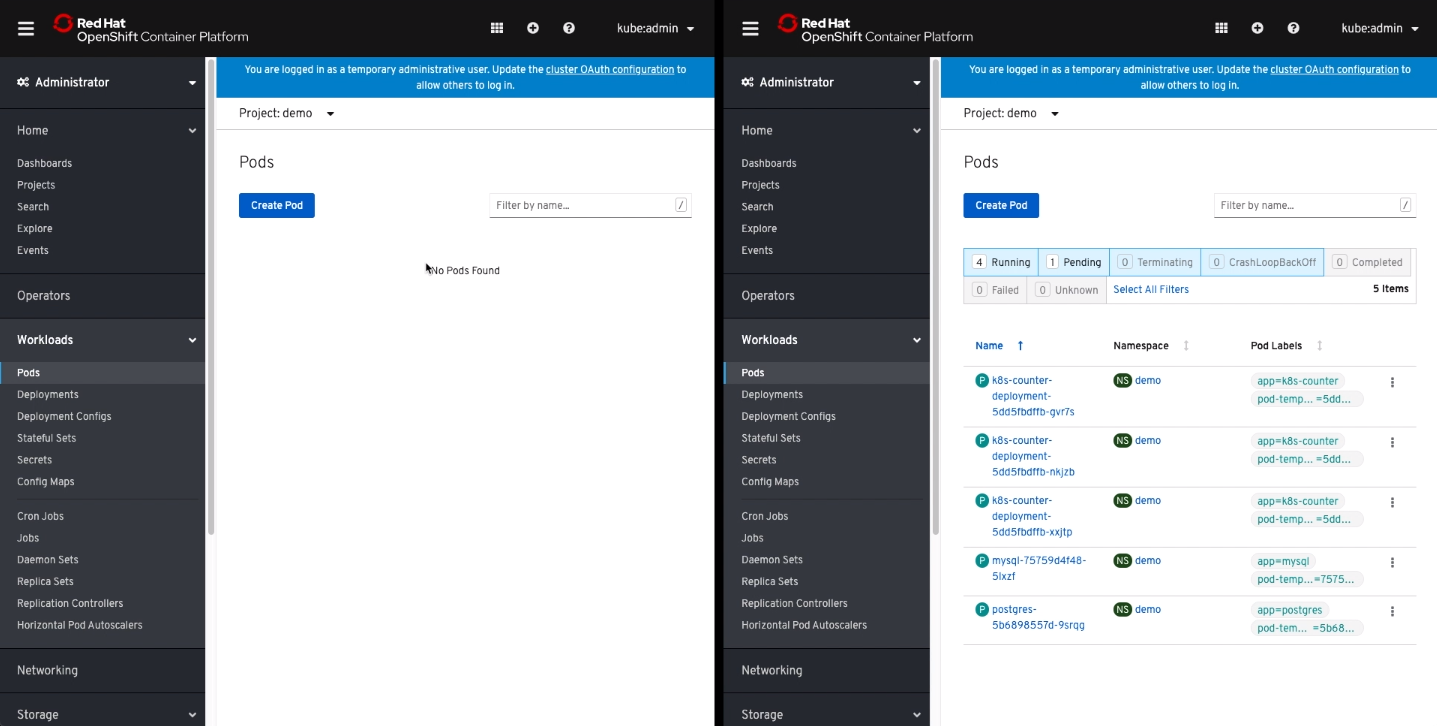
Once we apply both of these files to our GCP cluster, it will start an initial migration which takes a point in time snapshot of our volumes as well as the Kubernetes application state. Below you can see our first migration moved 2/2 volumes and 16/16 resources which include application configuration and Kubernetes objects
$GCP: storkctl get migrations -n demo NAME CLUSTERPAIR STAGE STATUS VOLUMES RESOURCES CREATED ELAPSED demo-migration-schedule-to-azure-interval-2019-10-03-205539 remote-azure Final Successful 2/2 16/16 03 Oct 19 16:55 EDT 1m38s
At this point you should see your newly created demo namespace in your Azure cluster.
$ watch kubectl get ns demo Every 2.0s: kubectl get ns demo NAME STATUS AGE demo Active 6s
As well as the deployment objects for our applications, though, they shouldn’t be running yet because we just want the state and data staged in Azure ready for us to turn it on, this is why we used startApplications: false in the migration object above.
$AZURE: kubectl get deployments -n demo NAME READY UP-TO-DATE AVAILABLE AGE k8s-counter-deployment 0/0 0 0 2m17s mysql 0/0 0 0 2m17s postgres 0/0 0 0 2m16s
We now have everything we need in order to “turn on” our applications in Azure with a point in time backup of our application state, volumes and app definitions. Keep in mind, this means any changes that are made to the data in the volume or the Kubernetes objects in the original cluster won’t be available until the next backup, which we scheduled for every 15 minutes in our schedule policy.
> Note: subsequent backups made after the initial one will be incremental such that a full backup is not taken every time. This improved the performance and reliability of backups from one cloud to another.
If you want to turn on your applications in Azure, remember to consider these steps.
1. $GCP: storkctl suspend migrationschedules --clusterPair remote-azure 2. $GCP kubectl scale --replicas=0 deployments -n demo 3. $AZURE: storkctl activate migration -n demo
At this point, you should be able to look at both OpenShift dashboards and see that Azure should be running or starting all the pods for the applications. Once all pods are running, you can access these applications to see that they will have the exact data that we took our backup from.
Great! That’s how you can achieve moving Kubernetes applicatiosn from Google Cloud to Azure with OpenShift 4.2 and Portworx Enterprise data management. If you prefer to watch a demo of the above use case, check out the below video which will take you through the step by step of what we talked about in this blog.


