What is Kafka?
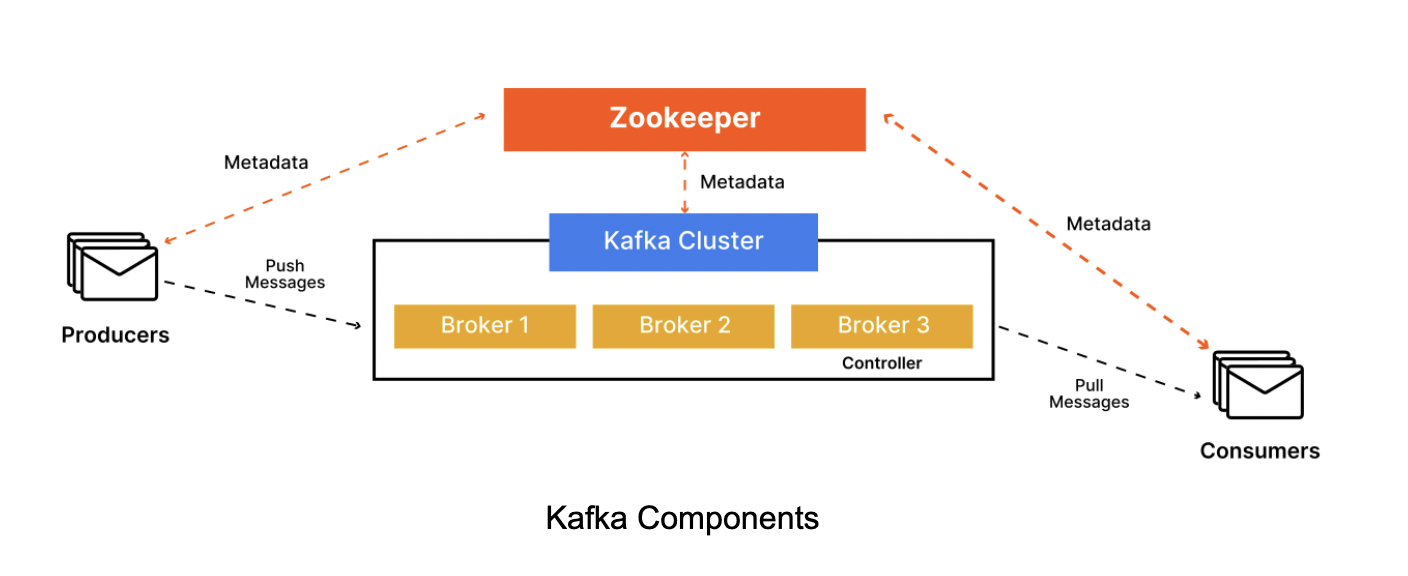
Apache Kafka is an event-streaming platform that runs as a cluster of nodes called “brokers” and was developed initially as a messaging queue. Today, Kafka can be used to process and store a massive amount of information all while seamlessly allowing applications to publish and consume these messages stored as records within what is called a topic. This massive information could be handled using Kubernetes Storage Management.
Typically Kafka is used to efficiently broker data between systems or to allow applications to react to streams of data in real time. In addition to being a popular message queue for distributed systems, it is commonly used to stream data in IoT use cases. Check the use cases of Kubernetes Storage & Deployment to learn more about real-world applications.
Core Components of Kafka
Topics and Partitions
A topic in Kafka serves as an abstract category for publishing records, allowing for a separation between message processing and record storage. Each topic is uniquely identified by its name and can contain various message types and formats, forming data streams.
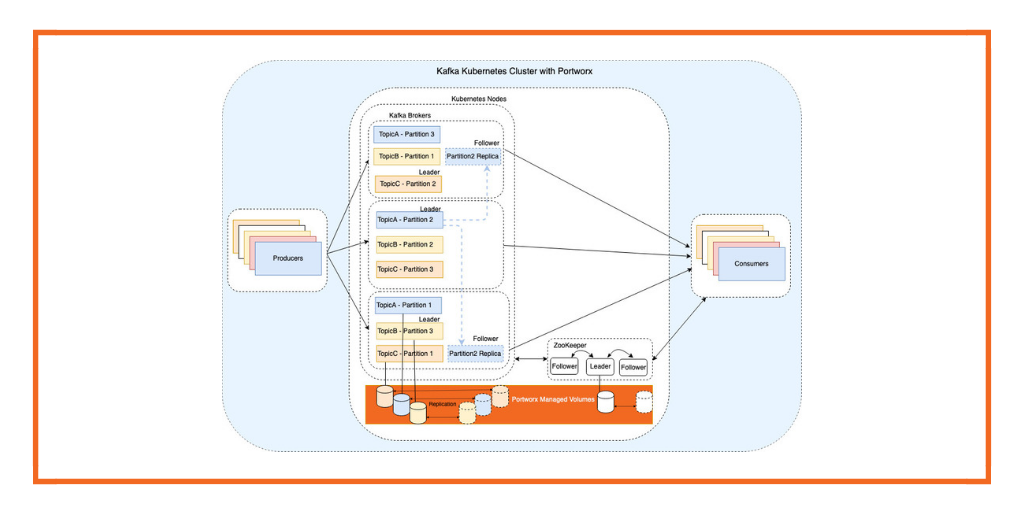
At a deeper level, topics consist of one or more partitions, which act as commit logs stored in files. Partitions work as a message queue but one that supports parallelism. Messages are distributed round-robin, ensuring an even load balance when a topic has multiple partitions.
Producers
Producers are client applications that are sources of data for Kafka topics. They generate and publish events to Kafka by integrating a Kafka client library. A Kafka producer sends a message on a Kafka topic and distributes messages by Kafka. Producers serialize and send data to the appropriate topic and partition based on a partitioning strategy such as round-robin.
Consumers
Consumers are the applications that subscribe to Kafka topics, read the messages, and process the records. They can be organized into consumer groups, allowing for efficient message processing. Each consumer within a group reads from a single partition, enabling load balancing. Kafka tracks message offsets which helps consumers to manage their reading position. This architecture supports parallelism and a publish-subscribe model, where messages are broadcast to all consumer groups, ensuring each record is available to multiple consumers.
Brokers
A broker is a server that stores and manages topics. A broker can be a ‘leader’ or a ‘follower’. If it is a leader, it handles all read and write requests and replicates them to followers ensuring fault tolerance. It mediates communication between consumers and producers and controls the overall state of the cluster. If it is a follower, then it replicates partitions to their log.
Key Features of Kafka
- Kafka offers fault tolerance through data replication across multiple brokers. Each partition can have replicas, ensuring that data remains accessible even if some brokers fail, thus maintaining high availability.
- Kafka supports growing user demand by offering horizontal scalability. More brokers and partitions can be added to handle increasing data volumes without performance degradation.
- Kafka enables parallel high-volume data processing, allowing multiple producers and consumers to operate concurrently, optimizing resource utilization.
What is Kubernetes?
Kubernetes is an open source platform that runs a cluster of worker nodes and master nodes which allow teams to build, manage, scale, and automate containerized workloads such as Kafka. Kubernetes can manage many applications at a massive scale including stateful applications such as databases or streaming platforms. Kubernetes was built on the shoulders of giants such as Google who initially conceived the software after using similar technology to run production workloads for over a decade.
Core Components of Kubernetes

Nodes
A node is a physical or virtual machine that allows you to run workloads. They can be master nodes, which host the control plane components, or worker nodes, which run the actual applications as pods.
Pods
Pods are the smallest deployable units in Kubernetes, encapsulating one or more containers that share storage and network resources. You can deploy and manage pods directly in Kubernetes to execute your applications.
Services
A service is a method of exposing a network application that is running as one or more pods in the cluster. It provides a logical abstraction for the underlying pods and allows for load balancing by distributing traffic across multiple pod instances.
Deployments
A deployment manages the creation of pods that have a containerized application. They help with efficient scaling, rolling updates, failover, and replication. Since it manages the lifecycle of a pod, it ensures that the specifications, such as the number of replicas, are always met in the cluster.
Key Features of Kubernetes
- Automatic scaling of containerized applications based on their usage. It also allows for the automation of deployments and updates and the ability to roll back in case of failure.
- Self-healing capability, which means that if a container fails, it reschedules it to maintain the desired state of the cluster.
- Integration with tools and plugins to enhance functionalities like monitoring, security, networking, and storage orchestration.
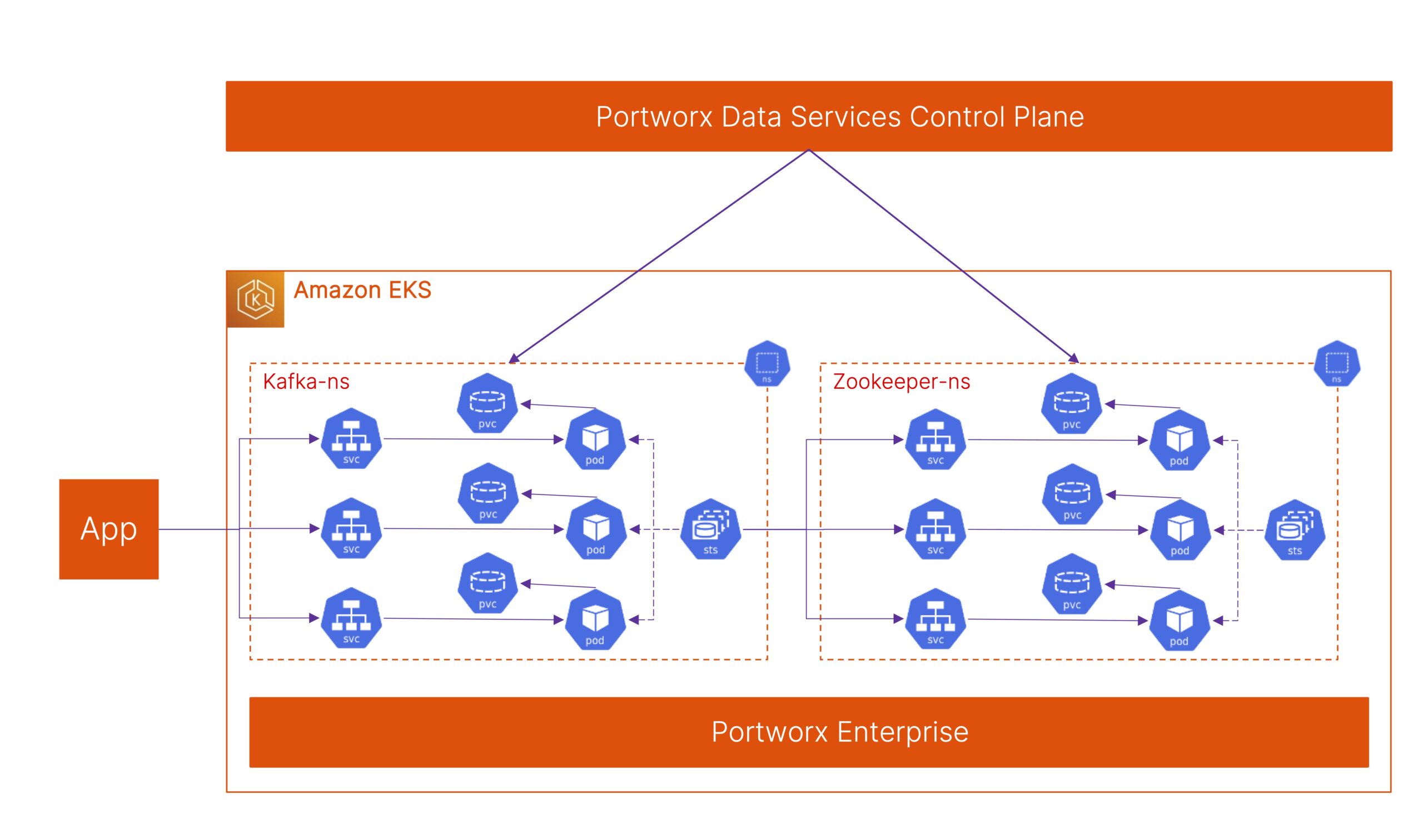
Running Kafka on Kubernetes
There are a variety of reasons a Kafka architecture is appealing. First, if your organization is set on using Kubernetes as an application platform, then this is a great reason to look at running Kafka there too. Running Kafka on Kubernetes allows organizations to simplify operations such as upgrades, scaling, restarts, and monitoring which are more-or-less built into the Kubernetes platform. You can Run Kafka on Kubernetes with Portworx Data Services.
Why Run Apache Kafka on Kubernetes?
Apache Kafka often runs on Kubernetes, a system that automates deploying, scaling, and managing containers across clusters of hosts. Apache Kafka is a perfect match for next-generation cloud-native app development.
While it might take more time and resources to switch your entire infrastructure to a new platform to accommodate Kafka, Kubernetes, in this scenario, offers an easier path to adoption.
For one, your IT teams will already be familiar with the environment. If they encounter any issue, it would be easier for them to fix it. Then there’s the problem of getting management approval to migrate to a different platform. The added cost will be hard to justify instead of just sticking with the Kafka / Kubernetes operator route.
Using Kafka in Kubernetes also offers benefits outside of easier adoption. One variable that many IT teams overlook is the number of Kafka clusters they’ll need to create. In larger enterprises, this can quickly grow into a multi-cluster scenario.
Of course, Kubernetes is well-suited for building and managing multiple clusters. With Kubernetes / Kafka, DevOps processes can be much smoother and seamless, thanks to its robust tools for provisioning, monitoring, and maintaining Kafka clusters. You can learn how to Combine Kafka and Cassandra on Kubernetes and also explore more such advanced use cases.
Ultimately, choosing to run a different platform with Kafka vs. Kubernetes will depend on your situation. Here is an Expert’s Guide to Running Apache Kafka on Kubernetes.
How to Set Up Kafka on Kubernetes
Prerequisites
Before getting started, ensure that you have the following prerequisites met.
- A running Kubernetes cluster
- Kubernetes CLI tools such as kubectl and Helm
Choosing a Kubernetes Distribution
It is possible to use Kafka on managed instances like Azure AKS, Amazon EKS, or Google GKE, or local cluster. However, for ease of demonstration, we are setting up a local cluster with Minikube. Make sure you are choosing the Right Kubernetes Operator for Apache Kafka.
Installing Kubernetes CLI Tools
kubectl
kubectl is used to interact with the cluster. If you do not already have kubectl installed, install it by following the official installation guide – https://kubernetes.io/docs/tasks/tools/install-kubectl-linux/
Installation can be verified by running the following:
`kubectl version --client`
Helm
Helm simplifies the installation of applications like Kafka and Zookeeper. Follow the official guide to install the helm – https://helm.sh/docs/intro/install/
Installation can be verified by running the following:
`helm version`
Kafka Cluster Configuration
Setting up Zookeeper Ensemble
Zookeeper is a critical component of Kafka, managing broker metadata and coordinating distributed processes. Setting up Zookeeper correctly is essential for the overall stability and reliability of the Kafka cluster.
Use the following to deploy Zookeeper:
zookeeper.yml
``yaml apiVersion: apps/v1 kind: Deployment metadata: name: zookeeper-deployment labels: app: zookeeper spec: replicas: 1 selector: matchLabels: app: zookeeper template: metadata: labels: app: zookeeper spec: containers: - name: zookeeper image: confluentinc/cp-zookeeper:7.0.1 ports: - containerPort: 2181 env: - name: ZOOKEEPER_CLIENT_PORT value: "2181" - name: ZOOKEEPER_TICK_TIME value: "2000" --- apiVersion: v1 kind: Service metadata: name: zookeeper-service spec: selector: app: zookeeper ports: - protocol: TCP port: 2181 targetPort: 2181 ```
Here is a detailed explanation of the above configuration:
- Deployment section:
- Replicas: In the above YAML, replicas are set to 1. For high availability, replicas should be configured to more than 1 (usually an odd number) to ensure the correct leader selection and continue functionality if one fails.
- Environment Variables: Environment variables are crucial in configuring and managing Kafka clusters.
- Service section:
- The typical port exposed for the Zookeeper service is 2181. This allows the Kafka broker to connect to Zookeeper for metadata management.
Configuring Kafka Brokers
Kafka brokers are the backbones of a Kafka Cluster. In a cluster, individual Kafka servers handle records from producers, assign offsets, store data on disk, and respond to consumer requests. Proper configuration is necessary to ensure high availability, performance, and durability.
Use the following to deploy Kafka:
kafka.yml
```yaml kind: Deployment apiVersion: apps/v1 metadata: name: kafka-deployment labels: app: kafka spec: replicas: 1 selector: matchLabels: app: kafka template: metadata: labels: app: kafka spec: containers: - name: broker image: confluentinc/cp-kafka:7.0.1 ports: - containerPort: 9092 env: - name: KAFKA_BROKER_ID value: "1" - name: KAFKA_ZOOKEEPER_CONNECT value: 'zookeeper-service:2181' - name: KAFKA_LISTENER_SECURITY_PROTOCOL_MAP value: PLAINTEXT:PLAINTEXT,PLAINTEXT_INTERNAL:PLAINTEXT - name: KAFKA_ADVERTISED_LISTENERS value: PLAINTEXT://:29092,PLAINTEXT_INTERNAL://kafka-service:9092 - name: KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR value: "1" - name: KAFKA_TRANSACTION_STATE_LOG_MIN_ISR value: "1" - name: KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR value: "1" --- apiVersion: v1 kind: Service metadata: name: kafka-service spec: selector: app: kafka ports: - protocol: TCP port: 9092
Here is a detailed explanation of the above configuration:
- Deployment section:
- Replicas: Here as well the replicas are set to 1. For high availability, it should be set to a higher odd number as explained in Zookeeper config.
- Environment Variables: Environment variables are necessary to ensure the proper communication between Kafka and Zookeeper, handle security protocols, and establish the necessary parameters for data integrity and fault tolerance.
- Service section:
- The Kafka broker is exposed by service on port 9092. This allows the other components like producers and consumers, to connect to it using the DNS name.
Additional Considerations for Zookeeper and Kafka
- High Availability: Increasing the number of replicas for both Zookeeper and Kafka will ensure load distribution and high availability.
- Persistent storage: To ensure data durability during failure or pod restarts, consider using PersistentVolumeClaims (PVCs) for the broker’s storage.
- Resource Allocation: It is important to allocate appropriate CPU and memory for each broker pod. Setting these resource allocations helps manage the performance and ensure stable operation under load.
Apply these configurations on the cluster using the following commands:
``` kubectl create -f ./resources/zookeeper.yml kubectl create -f ./resources/kafka.yml ```
Check the status of the deployed resources using the following command:
``` kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE kafka-deployment 1/1 1 1 170m zookeeper-deployment 1/1 1 1 171m ```
Create Kafka Topic
Execute the following command on a pod created by `kafka-deployment`. This topic can be used to send and receive messages.
``` $kubectl exec -it kafka-deployment-xxxxxxxxxxx -- bash [appuser@kafka-deployment-xxxxxxxxxxxxxx ~]$ kafka-topics --bootstrap-server localhost:9092 --create --topic topic-one --replication-factor 1 --partitions 3 Created topic topic-one.
Produce and Consume
Start the kafka-console-producer by running the following command on the Kafka pod.
``` [appuser@kafka-deployment-xxxxxxxxxxxxx ~]$ kafka-console-producer --broker-list localhost:9092 --topic topic-one >test1 >test2 >test3 >^C ```
Enter a few sentences for the event payload, then stop the kafka-console-producer with ctl-c. Now, start the kafka-console-consumer with the following, which includes the option to consume events from the beginning. `
``` [appuser@kafka-deployment-xxxxxxxxxxx ~]$ kafka-console-consumer --bootstrap-server localhost:9092 --topic test-topic --from-beginning test2 test3 Test1 ```
Given that there are three partitions, there is no assurance regarding the order in which they will be consumed. The writing process is non-deterministic, meaning that it’s unclear which partition data will be written to and the sequence in which the partitions will be polled.
The sending and receiving of messages can be done with two different terminals at the same time. This way, the consumer will receive the message at the same time the producer sends it. This way there will not be a mismatch in the sequence of messages sent by producers.
Networking Considerations
A well-designed network setup can achieve efficient communication between Kafka brokers, producers, and consumers within the Kubernetes cluster. The Following considerations will help ensure seamless integrations among the different Kafka components.
Service Discovery
Service discovery is critical for enabling clients and other microservices to locate Kafka brokers automatically. Kubernetes Services are crucial in exposing the Kafka broker IP address and ensuring easy access between producers and consumers.
Headless service allows clients to connect to Kafka brokers individually, ensuring that they maintain their state and partition assignments.
``` apiVersion: v1 kind: Service metadata: name: my-kafka-headless labels: app: kafka spec: ports: - port: 9092 name: kafka clusterIP: None # Headless service selector: app: kafka ```
Headless service can be configured by setting the clusterIP field to ‘None’ in the service definition.
Service Mesh is an infrastructure layer designed to manage the communication between different microservices. It can simplify the management of microservices, and improve reliability, security, and observability. With service mesh, we can have better:
- Traffic management: Define specific routing rules to control message flow between brokers, producers, and consumers.
- Observability: Provides tracing and monitoring to troubleshoot the issues and identify bottlenecks.
- Resilience: Manage timeouts, retries, and circuit breaks to ensure reliability and stability.
- Dynamic configuration: allows real time policy management and configuration updates without downtime.
Cluster IP vs Load Balancing
ClusterIP: ClusterIP type service is ideal for internal communication within the Kubernetes clusters. This allows Kafka brokers to be accessed by other services within the cluster. However, it does not expose them externally.
Load Balancer: Load balancer service is used for heavy traffic. Load Balancer service provides a stable external IP for connections when external clients need to access the Kafka brokers.
Also when the client requests are high, the load balancer distributes the requests evenly across different Kafka brokers. Load balancing prevents performance bottlenecks and ensures high availability. Here is a sample load balancing configuration.
```apiVersion: v1 kind: Service metadata: name: my-kafka-lb spec: type: LoadBalancer ports: - port: 9094 # External port targetPort: 9092 # Internal port selector: app: kafka ```
In this configuration, you can set the following:
- Service Type: Set the service type to ClusterIP when communication is expected within the Kubernetes cluster. The LoadBalancer type service provides access to Kafka for external clients.
- External Clients: If external clients need to connect to a Kafka broker, consider setting up a Kubernetes ingress or a NodePort service. A NodePort service exposes the Kafka broker on a static port on each node.
Ingress Controllers
The Ingress controller provides external access to Kafka brokers by routing external traffic to the appropriate services.
- Ingress Setup: Traefik or Nginx can be utilized to manage and route the incoming traffic to the Kafka cluster.
- TLS Termination: To ensure secure communication between clients and Kafka brokers, it is recommended that TLS termination be configured at the ingress level. The TLS safeguards sensitive data during transit.
How to Monitor and Manage Kafka on Kubernetes
Monitoring helps with understanding Kafka’s performance on Kubernetes and managing it efficiently. Here are some metrics you should monitor to better manage Kafka on Kubernetes cluster.
- ActiveControllerCount: The sum of ActiveControllerCount across all of your brokers should always equal one, ensuring only one controller.
- RequestsPerSec: This helps ensure your Kafka deployment communicates efficiently across producers, consumers, and followers.
- Disk usage: This helps you avoid Kafka failure if disks become full. Kafka persists all data in the disk, so it is necessary to monitor the amount of free disk space available to Kafka.
- Response rate: When the data has been received, brokers respond to producers. This helps check the rate of responses received from brokers.
If you are using Kafka with KRaft, you can check this configuration to enable monitoring.
Kafka on Kubernetes Best Practices
Resource Management
Effective resource management in Kafka on Kubernetes involves configuring storage and compute resources to optimize performance and minimize costs. Here are some of the tips to help you:
- Utilize PersistentVolumeClaims (PVCs) with appropriate storage requests based on expected message throughput and retention periods.
- Implement separate Persistent Volumes for Kafka’s log segments and log files to enhance performance and simplify management.
- Define resource quota limits for Kafka brokers to prevent any single broker from consuming all cluster resources.
- Set the JVM heap size based on the container’s memory limit like 50% to prevent Out-of-Memory(OOM) errors.
Performance Tuning
To ensure high throughput and low latency in Kafka deployments, fine-tune configurations related to storage management. Here are some recommended practices:
- Configure producer batch sizes to enhance throughput. This will allow more messages to be sent in a single request and help reduce the number of requests sent over the network.
- Enable liveness and readiness probes for Kafka brokers to ensure that Kubernetes can manage broker health effectively.
- Set up multiple consumer groups to allow load balancing across consumers.
- Use sticky partitioning (available in Kafka 2.4+) to minimize rebalances and maintain consumer state during partition assignments.
Backup and Recovery Strategies
Implementing robust Kubernetes backup and recovery strategies is crucial for maintaining data integrity in Kafka. Let us check some of the best practices:
- Use a replication factor of at least 3 to ensure data redundancy across brokers and minimize the risk of data loss in case of broker failures.
- Implement `kafka-backup` to back up Kafka topic data, including consumer group offsets.
- Use monitoring tools to track the health of your Kafka cluster and backup processes. Check Backup Built for Kubernetes.
Regular Maintenance and Updates
Conducting regular maintenance is essential for the long-term health of Kafka deployments. Schedule routine updates for both Kafka and Kubernetes components to benefit from the latest features and security patches.
- Keep track of release notes for new versions of Kafka and based on it plan regular updates for both Kafka and Kubernetes components. This way you can leverage the latest features, improvements, and security patches.
- Use rolling updates to minimize downtime during upgrades. Ensure you restart only one broker at a time to maintain service availability. This helps maintain at least one replica available during the upgrade process.
To effectively operate and scale Apache Kafka on Kubernetes, it is essential to implement automated monitoring and resource management strategies that adapt to changing workloads and ensure optimal performance.
Some additional items to consider when running Kafka on Kubernetes:
Low Latency Network and Storage
Kafka deployment demands low latency network and storage which means ideal conditions have low contention for data on the wire as well as high throughput and low noise accessing storage. Dedicating fast media such as SSDs to brokers and thinking about data locality where access to data for the brokers is local to where the pod is running will increase the overall performance of the system.
High Availability for Kafka Brokers
Kafka runs as a cluster of brokers, and these brokers can be deployed across a Kubernetes system and made to land on different workers across separate fault domains. Kubernetes automatically recovers pods when nodes or containers fail, so it can do this for your brokers too. One thing to consider with high availability is what happens to the data which that broker was storing. Does the data follow the pod? Does the data get rebuilt over the network? Kafka can rebuild brokers after a node failure, but these rebuilds come at the cost of lower I/O to the application during the rebuild. Consider a data replication strategy that allows you to leverage multiple brokers for higher throughput, but that enables faster failover in the case of a node failure.
Data Protection
Kafka provides replication of topics as well as data mirroring between clusters. Replication should be considered as a way to achieve fault tolerance if a broker should fail and mirroring is typically used to make data available in another datacenter. Some items to be considered are how long it takes for replicas to be rebuilt once the broker is back online, what disaster recovery strategy is in place in case of cluster or zone failure and what level or RTO and RPO are needed between sites. Consider your throughput requirements and use only the number of brokers necessary to achieve that performance while leveraging technologies that replicate data to other hosts in the cluster such that you can maximize availability, performance, and protection.
Data Security
Kafka provides built-in security features which include authentication, access controls for operations and encryption using SSL between brokers. However, something to consider is if your data in the filesystems on disk are protected, and which users have access to manipulate those backing stores where the data lives. Ideally, organizations should protect at the application level but also secure the data layer along with it for added security.
Operate and scale Apache Kafka seamlessly on Kubernetes with the Portworx® platform

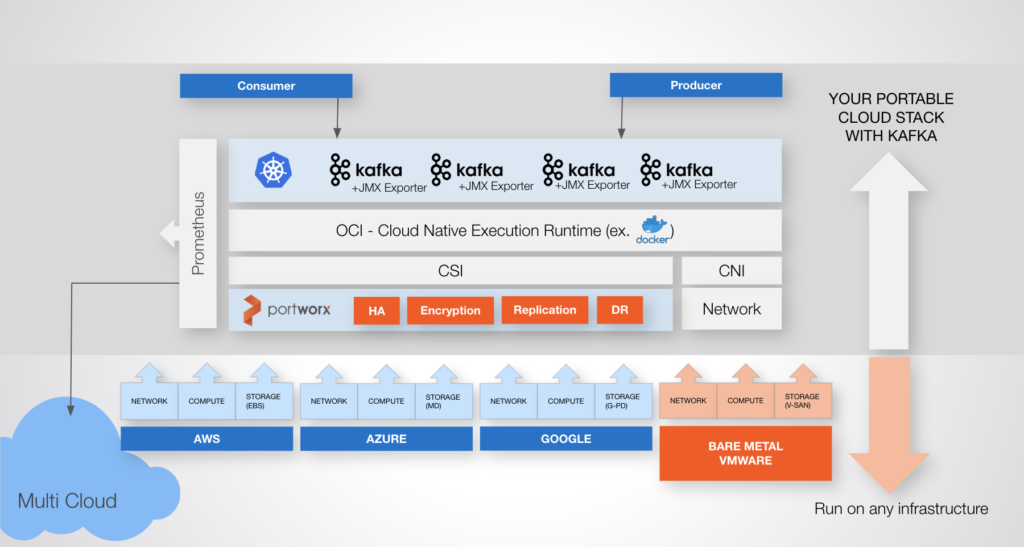
Kafka on Kubernetes
Step-by-step guides to run HA Kafka on the most popular Kubernetes platforms