




How to use the immense power of AWS Auto-Scaling Groups and EBS for a stateful Docker application.
Download the slides
In a service-oriented world where requests can come from anywhere at any time, keeping a system constantly up and available is essential to its success. When running at scale, failures happen. This is just a fact of life for modern, distributed systems.
The focus should not be on trying to prevent those failures, unless you want to start a hard-disk company. Instead, we should endeavour to automatically react to those failures, restoring service quickly and with minimal impact.
ASGs (Auto-Scaling Groups) can help by automatically monitoring the load and health of your instances. If a node fails, it will be replaced automatically so you don’t get woken up in the middle of the night with a PagerDuty alert.
This post will answer the question “how do I use AWS auto scaling groups (ASG) with Docker?” We will explore the key features of ASGs for stateful apps because special care needs to be taken when using EBS volumes if you don’t want to lose your data.
Our application allows users to post data to our API and we use Cassandra to both save and analyse the data.

We decide to employ one of the killer features of Cassandra – the ability to scale horizontally.
We settle on having three nodes in our Cassandra ring. As well as providing high availability in the event of a node failure, this will also mean we distribute read queries across more CPUs and increase the total disk capacity across the cluster.
We could spin up three EC2 nodes and install Cassandra using Terraform or Ansible. However, for the reasons mentioned above, we want the Cassandra cluster to auto-heal if a node fails and so we decide to use an Auto-Scaling Group.
There are a few steps to creating an ASG:
Let’s walk through this setup:
We bake an AMI based on Ubuntu Xenial 16.04 with Docker CE 17.03 installed so we can run Cassandra inside a container.
$ aws ec2 create-image \
--instance-id ${BUILDER_INSTANCE_ID} \
--name myami
Then we create a launch configuration which uses our AMI and instance type (`t2.large`) for our group.
$ aws autoscaling create-launch-configuration \
--launch-configuration-name asg_demo_config \
--image-id myami \
--instance-type t2.large \
--key-name my-key \
--block-device-mappings "[{\"DeviceName\":\"/dev/sda1\",\"Ebs\":{\"SnapshotId\":\"snap-3decf207\"}},{\"DeviceName\":\"/dev/sdf\",\"Ebs\":{\"SnapshotId\":\"snap-eed6ac86\"}}]"
Notice the –block-device-mappings field – this describes how our launch configuration will create and attach a new EBS drive to each instance.
Next, we create the Auto-Scaling Group and point at the Launch Configuration we just made. This ASG now manages the number of instances in our Cassandra cluster. We create a Load-Balancer and point it at the ASG which lets us send traffic to any of the instances in that group.
$ aws autoscaling create-auto-scaling-group \
--auto-scaling-group-name asg_demo \
--launch-configuration-name asg_demo_config \
--min-size 3 \
--max-size 3 \
--desired-capacity 3 \
--availability-zones eu-west-2
Let’s see what this looks like:
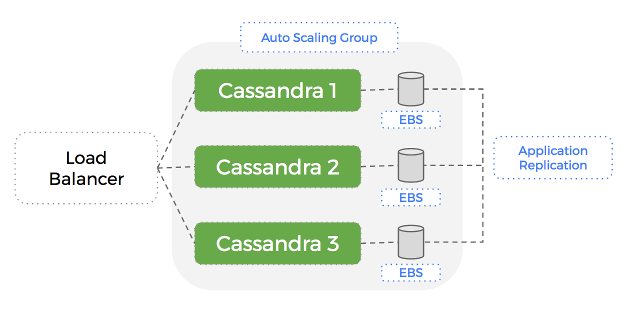
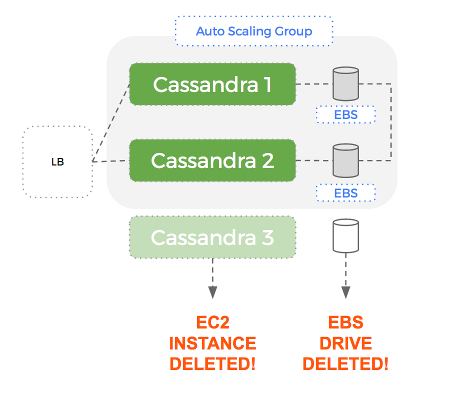
When running tests with this setup, we realise a fundamental flaw in our system:
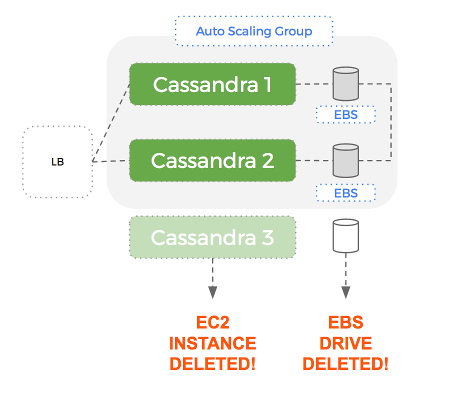
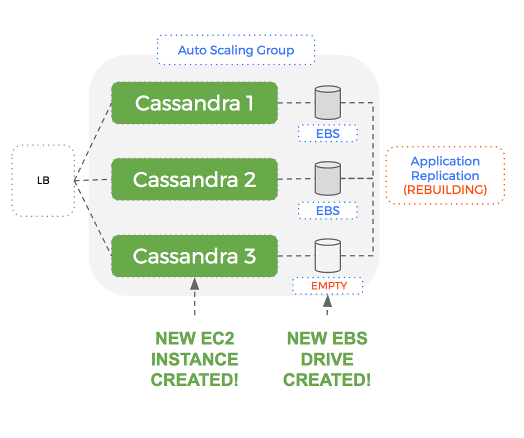
If a node fails, it is automatically replaced with a new EC2 instance and EBS volume (great), but this volume doesn’t have any data. Cassandra will populate this empty volume using a replica but this can take a significant amount of time – which hurts our performance until complete.
The problem is that within an Auto-Scaling Group – AWS treats an EC2 instance and its associated EBS volume as a single, atomic unit.
This means that if the EC2 instance is terminated, the EBS drive is deleted – along with the dataset Cassandra it was using.
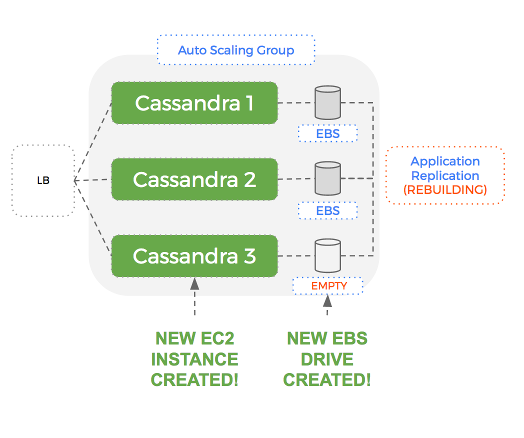
A new EBS drive will be created but Cassandra will have to send all the data over the network to rebuild the dataset on that node.
This can take a long time if the dataset is large. What if we could just reuse the EBS drive that was attached to the old node? Then most of our dataset is already there when the new node starts up.
We realise that we need to de-couple compute from storage.
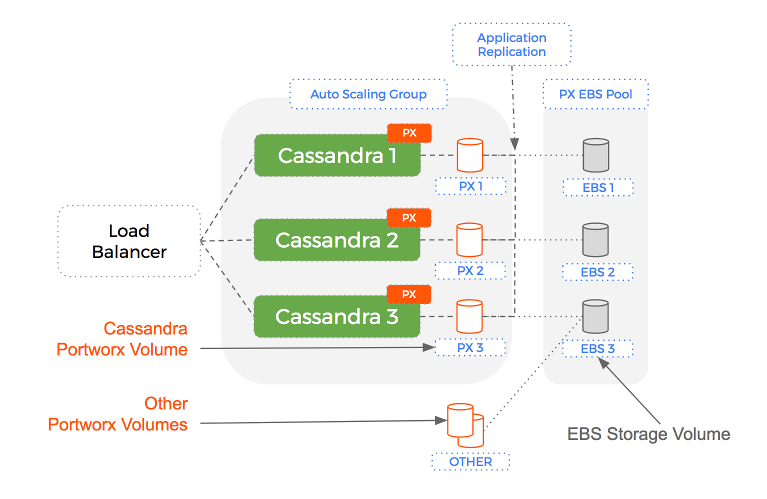
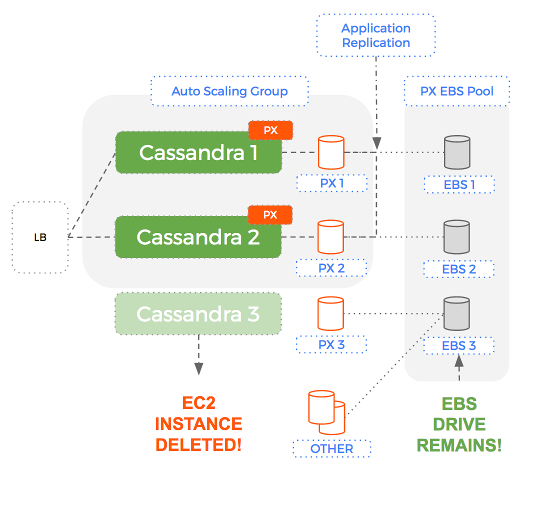
Using Portworx to add a data services layer – we can have a level of separation with Auto-Scaling Groups managing EC2 instances (compute) and Portworx managing EBS volumes (storage).
The key aspect of this solution is that when the Auto-Scaling Group terminates an EC2 instance – the EBS volume is NOT removed. More importantly, the same EBS volume that was attached to an instance previously, is re-used for the next instance.
Let’s see what this looks like:
This means our design now works because:
The reason this works is because Portworx is a data services layer that manages your underlying storage (EBS) and leaves the Auto-Scaling Group to manage only the compute (EC2).
Let’s compare how this works in a failure scenario:
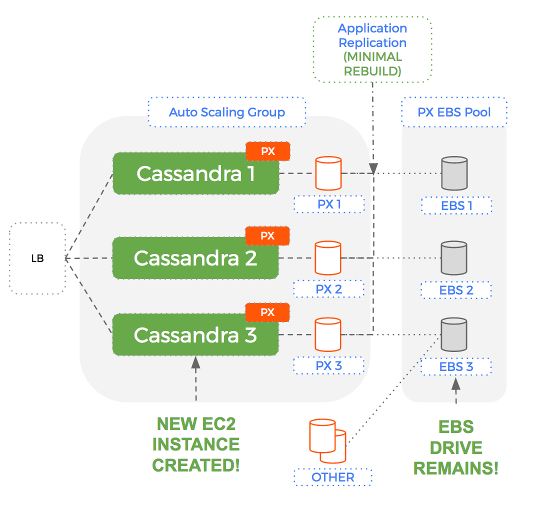
An EBS volume could contain hundreds of Gigabytes. Being able to reuse that existing EBS drive – with dataset intact, means Cassandra takes an order of magnitude less time to rebuild.
This only works because Portworx can de-couple compute from storage.
Portworx has a clusterid and can use one of three methods to connect to the AWS api:
Portworx is now able to create new EBS volumes on demand. As it creates these EBS volumes, it will tag them with identifying values so at any time, it can enumerate the available pool of EBS volumes available to an Auto-Scaling Group.
When a new instance is added to the group – Portworx does the following:
Using this setup – if we have a healthy 3 node Cassandra cluster and one of our nodes dies – whilst the Auto-Scaling Group will replace the compute instance, Portworx will reuse the storage volume.
Let’s step through creating this setup with Portworx:
First we create a volume that will serve as a template for volumes that will be automatically created when we scale up.
We can choose the size, IOPS and type of disk for our template and Portworx will automatically replicate these settings for new volumes.
Here is a command to create our template EBS volume:
$ aws ec2 create-volume \
--size 20 \
--volume-type gp2 \
--availability-zone eu-west-2 \
--output text \
--query 'VolumeId'
We will need an etcd server so that Portworx can co-ordinate across the cluster. Future versions of Portworx will lose this dependency and you won’t need this step.
Then we provision a new EC2 instance that will serve as the template for our AMI image that will run Portworx using `systemd`.
Then we install docker and copy the following service template to `/lib/systemd/system/portworx.service`:
[Unit]
Description=Portworx Container
Wants=docker.service
After=docker.service
[Service]
TimeoutStartSec=0
Restart=always
ExecStartPre=-/usr/bin/docker stop %n
ExecStartPre=-/usr/bin/docker rm -f %n
ExecStart=/usr/bin/docker run --net=host --privileged=true \
--cgroup-parent=/system.slice/px-enterprise.service \
-v /run/docker/plugins:/run/docker/plugins \
-v /var/lib/osd:/var/lib/osd:shared \
-v /dev:/dev \
-v /etc/pwx:/etc/pwx \
-e AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID} \
-e AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY} \
-v /opt/pwx/bin:/export_bin:shared \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /var/cores:/var/cores \
-v /usr/src:/usr/src \
--name=%n \
portworx/px-enterprise -c asg_cluster -k etcd://${ETCD_HOSTNAME}:2379 -s ${TEMPLATE_VOLUME}
KillMode=control-group
ExecStop=/usr/bin/docker stop -t 10 %n
[Install]
WantedBy=multi-user.target
The following variables are used in the service file:
Next – we create a launch-configuration that describes:
$ aws autoscaling create-launch-configuration \
--launch-configuration-name asg_demo_config \
--image-id ${AMI} \
--instance-type ${INSTANCE_TYPE} \
--key-name ${KEYNAME}
Then we create the actual auto-scaling-group – we set the following key properties:
This will result in a group of 3 instances:
$ aws autoscaling create-auto-scaling-group \
--auto-scaling-group-name asg_demo \
--launch-configuration-name asg_demo_config \
--min-size 3 \
--max-size 3 \
--desired-capacity 3 \
--availability-zones ${AWS_ZONE}
To summarize, the key to using ASGs with Docker is:
By de-coupling compute from storage, we get the immense power of AWS Auto Scaling Groups to manage compute together without worrying that your data will disappear or that your cluster will take hours to actually scale.
To try this out – check out our documentation on AWS Auto Scaling Groups. You can also read more about Docker persistent storage, Kubernetes storage and DC/OS storage so you can use your scheduler alongside AWS ASGs.


