


What is PostgreSQL?
PostgreSQL, or more commonly Postgres, is a relational database that uses the common SQL language to perform queries. It provides features that safely allow users to persist and scale data workloads. Postgres has proven itself in many production software stacks in its lifetime and can provide flexible and reliable features to a range of applications.
Before discussing Kubernetes Postgres, what is Postgres?
It is an advanced, enterprise-class, open-source relational database system. It can support both relational and non-relational querying. Since it has more than 20 years of active development, this is the platform for the present and the next generation.
You can connect to the code via the open-source community, meaning it is constantly changing and improving. Many web applications already use it as a primary database. It has also transitioned to analytics and mobile applications.
The history of Kubernetes Postgres begins in 1986. The Berkeley Computer Science Department at the University of California created the original project. It was the code and configuration that evolved from the original Ingres database started at the same institution. The goal of Postgres was always to support more data types by adding a minimal number of features.
What is Kubernetes?
Kubernetes is an open-source platform which runs a cluster of worker and master nodes which allow teams to deploy, manage, scale and automate containerized workloads such as PostgreSQL. Kubernetes can manage many applications at massive scale including stateful applications such as databases or streaming platforms. Kuberenetes builds on the shoulders of giants such as Google who initially conceived the software after using similar technology to run production workloads for over a decade.
Kubernetes is there to automate software development within modern development environments. It improves the ability to scale and provides help to development teams that need to simplify their infrastructures.
Every Postgres Kubernetes operator is working with a project provided by Google. Today, the Cloud Native Foundation is responsible for its future development.
Today’s Kubernetes is fully compatible with programs like Containerd, CRI-O, and Docker. Companies across the globe provide platforms using the Kubernetes model, which is currently being offered as Infrastructure as a Service (IaaS).
The name “Kubernetes” originates from the Greek word for “Helmsman.” It was developed by three different Google developers in the middle of 2014, with more of Google’s development team joining to enhance its capabilities and improve its usability
Why Run Postgres in Kubernetes?
Running Postgres in Kubernetes requires planning to create the connection and ensure its clusters co-exist peacefully with other platforms. Operating a Kubernetes Postgres service requires clear thinking and a plan for making the most of it.
Historically, using Postgres inside Kubernetes was viewed as an anti-pattern. Since Kubernetes is a cutting-edge orchestration system, it focuses primarily on elasticity and scalability. Over time, the vision and goals of the average PostgreSQL operator Kubernetes have changed. It harkens back to the Kubernetes 1.14 update, which introduced local persistent volumes.
Another contributing factor is the surge in the adoption of operator design patterns to simplify the management of complex applications, including databases.
Now, let’s run through why you might want to use Kubernetes Postgres to create a database and what a Postgres operator Kubernetes should know.
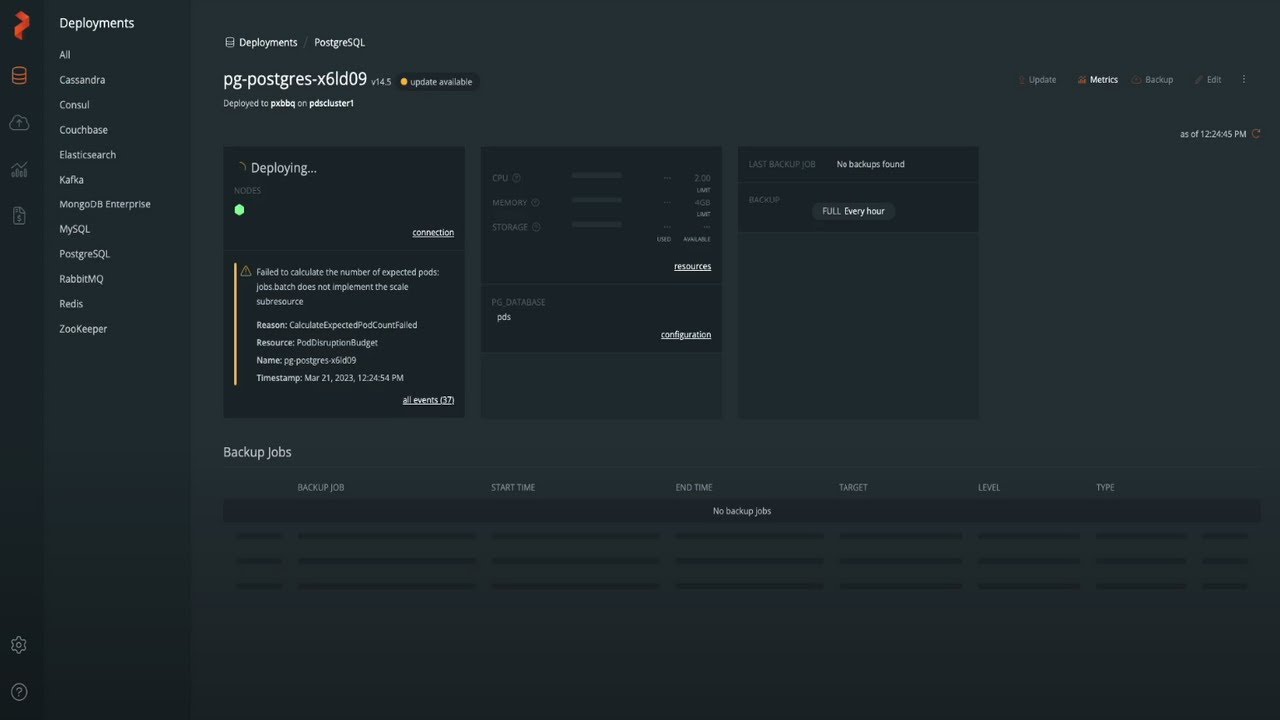
PostgreSQL Deployment Demo with Portworx Data Services
Portworx Data Services equips users with the ability to deploy and manage a variety of different databases and message queues to Kubernetes clusters. This video will walk you through the deployment of PostgreSQL to Kubernetes through the Portworx Data Services UI.
Benefits of Running a Database on Kubernetes
The main benefits of applying Kubernetes Postgres to your latest project pertain to performance and improving collaboration.
Here is an examination of the benefits of combining the two and making them a part of your community infrastructure:
- Improve Your Performance – Kubernetes Postgres allows you to develop database services that are fully scalable. It is the microservices architecture that it is based on. It schedules different pods and nodes according to how many resources are available, effectively automating the development of new applications. It also enhances faster disaster recovery should a Kubernetes Postgres operator experience a problem.
- Boost Collaboration – Collaboration is essential in the modern application development ecosystem of today. Kubernetes Pods come together to deal with client requests. Full load balancing is available, and Pods may be removed or added without causing any interruptions to the service. For example, users may also choose to bring in Helm charts to share resources with other relevant users.
- Stateful Workloads Support – The point of stateful services is to help preserve the existing state of stateful services from a single session to the next one. These are the services that need performance, reliability, and security to function. Incorporating a container orchestration platform, for instance, ensures that automation is available for these large-scale operations.
Instances within Postgres and the Pods inside Kubernetes are able to collaborate effectively. Unfortunately, there are significant challenges for database administrators to make them compatible.
You can take advantage of multiple managed solutions to deploy Postgres on Kubernetes. Postgres Kubernetes deployment solutions enable you to implement container orchestration and maximize their benefits.
Considerations Before Deploying Kubernetes Postgres
The workloads within Postgres benefit from using Kubernetes automation. However, stateful workloads need to meet a strict range of criteria to ensure they have the performance, security, and availability necessary to function within critical applications.
If you want to maximize the benefits of Kubernetes Postgres, you must take into account the following considerations:
Container-Native Storage – Make sure you possess a data layer offering dynamic storage provisioning. You need this to comply with stateful services provided by platforms like Postgres. Container volumes are not designed to provide storage to containers in a direct manner. If you decide to use blocks, you could experience slow provisioning of databases. By using container-native storage, you keep your data available in the event you need to opt for pod rescheduling.
Maintain Availability – Postgres uses something called WAL to always maintain data integrity. These databases log the changes in your data and send them to disk prior to writing them into the database. If you experience a database disaster or corruption, Postgres can reapply your changes by retrieving the WAL. To avoid a slowdown of the WAL process, you should ensure that you have a strong read-write performance.
Ensure High Data Security Standards – One of the major benefits of Postgres is that you already have encryption that has been built into the system. It protects your data through the use of a cipher to encode it. In order to maintain the data in its original state, you will need a password or decryption command. These data security provisions must be available at the application level.
Many database operators need help with the API to initiate a Postgres database within Kubernetes. Postgres.exe is the core process when you run PostgreSQL on your computer or database system.
Configuration is the key to running these platforms in tandem with each other. In particular, you need to be wary of Pods specifications, paying special attention to primary and standby Pods.
You also need to leverage the Kubernetes architecture to maximize the benefits of running these programs together. Kubernetes relies on distributed agents, known as controllers, to communicate through the central control plane. These controllers are there to track instances from Postgres, and be responsible for the management of the whole Postgres application.
Finally, you should always keep a backup of your data. Understand that disasters can happen at any time, and without a disaster recovery backup, you will be unable to retain the latest versions of your data.
It is always considered best practice to maintain backup copies of your data. If the platform needs to reschedule one of your pods, you can use a local copy to get your database back. Data loss is a significant risk when running these programs together, but by relying on local copies, you always have an option to get everything back.
Moreover, you have the extra benefit of maintaining local copies of data. If the corruption of one of your databases occurs, you can shorten the time needed to restart a Pod and bring it back to life.
Proper planning will ensure that you can face any challenge that shows up along the way, no matter the severity.
Running Postgres on Kubernetes
Kubernetes is a great place to run many types of workloads that require automation and scale. Due to the particular requirements of stateful services–security, reliability, performance– they benefit in particular from this automation, enabling teams to move faster to market without sacrificing reliability. Because they house data, stateful workloads like Postgres running on Kubernetes must be able to meet particular business requirements outlined below in order to meet compliance, security, availability, and performance demands of mission-critical applications.
Container-Native Storage
Kubernetes provides automation for application deployments by scheduling and rescheduling pods dynamically based on available resources. Due to the nature of stateful services like Postgres, you must have a data layer in place that can provide dynamic storage provisioning for Postgres pods as well as the ability to keep that data available in the case of pod reschedules. Using block devices from a cloud provider as container volumes often lead to low density of stateful containers per host, slow database provisioning and slow failover as these systems were not designed to provide storage directly to containers. Likewise, traditional on-premises storage systems that were built for VMs have similar problems. Choose a container-native storage layer that can match the scale, density, and dynamism of container environments.
Performance & SLA Considerations
As a stateful service, Postgres running on Kubernetes is composed of a container image running in a pod and a data volume which is stored on a disk. This volume must be persisted in the case of server failure, otherwise, the Postgres pod will be relaunched on another host without its data. Highly performant persistent storage for Postgres is particularly important given the use of components such as the Write Ahead Logs (WAL). A WAL is a major piece of the database software that ensures data integrity by logging changes to data and flushing the data to disk before actual changes are written to the database. This allows Postgres to re-apply logged changes in case of database corruption or recovery. These logs are stored within the persistent location configured when Postgres starts, so any data management layer should support high performance and data locality for these logs to ensure that an application is not sluggish writing to disk. In the case of server failure, Postgres can rebuild a data set by replaying logs, however this process can be very slow and for production systems with strict SLAs, it is preferable to keep an up-to-date copy of the volume elsewhere in the cluster such that Kubernetes can simply reschedule a pod to a host with a local copy of the data already available.
Cloud Migrations and Disaster Recovery
PostgreSQL is often the system of record for important data sets that must be managed in a way that ensures data integrity and availability. Pick a cloud native storage system that allows the migration of Postgres pods and data between environments using the Kubernetes control plan. In the event of scheduled and unscheduled maintenance, you should be able to copy both your Postgres data and Kubernetes objects like controllers and PVCs between environments without time-consuming WAL replays or ETL processes. Additionally, you should ensure that in the event of a complete data center or regional outage, you can run your Postgres database in another environment with RPO zero data loss.
Data Security
Postgres provides built-in security features such as encryption and tls, However, you should also consider how data volumes are protected when running inside a multi-tenant Kubernetes environment, and which users have access to manipulate these objects and backing stores. For added security, organizations should protect their data at the application level as well as secure the data layer with encryption and role-based access controls in the data management layer.

Step-by-step guides to run HA PostgreSQL on Kubernetes platforms





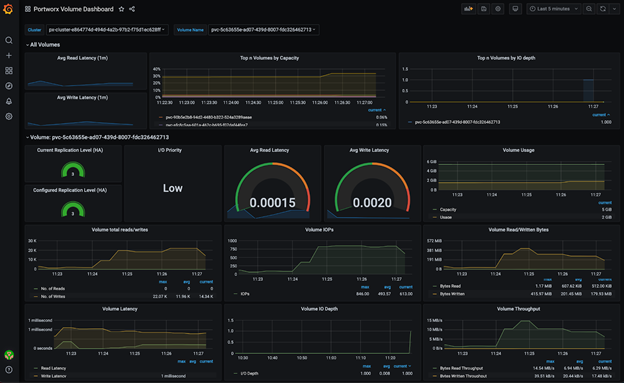





Kubernetes Tutorial: How to Create Cloud Snapshots of PostgreSQL Persistent Volume Claims on GKE

Kubernetes Tutorial: How to Create Local Snapshots of PostgreSQL Persistent Volume Claims on GKE

Kubernetes Tutorial: How to Expand PostgreSQL Persistent Volume with No Downtime on Google Kubernetes Engine (GKE)









