As part of our ongoing series on running MySQL on Kubernetes, we’ve also published a number of articles about running MySQL on Kubernetes for specific platforms and for specific use cases. If you are looking for a specific Kubernetes platform, check out these related articles.
Running HA MySQL on Amazon Elastic Container Service for Kubernetes (EKS)
Running HA MySQL on Google Kubernetes Engine (GKE)
Running HA MySQL on Azure Kubernetes Service (AKS)
Running HA MySQL on Red Hat OpenShift
How to Backup and Restore MySQL on Red Hat OpenShift
Running HA MySQL on IBM Cloud Kubernetes Service (IKS)
Running HA MySQL on Rancher Kubernetes Engine (RKE)
And now, onto the post…
This MySQL Kubernetes guide will show you how to run MySQL in containers on Kubernetes using statefulsets and kops.
Background
Our engineers (especially Harsh Desai) have been working closely with Kubernetes engineers to improve the installation path of Portworx onto a Kubernetes cluster.
We are pleased to announce that as of version 1.6.5, Kubernetes supports running Portworx in “masterless” mode which has several advantages for various Kubernetes-based platforms.
This post will focus on running Portworx with Kubernetes on AWS using kops to bootstrap the cluster. In this post we will focus on running a MySQL server and dealing with a failover scenario.
Use Case
Before we dive in, let’s ask ourselves a question:
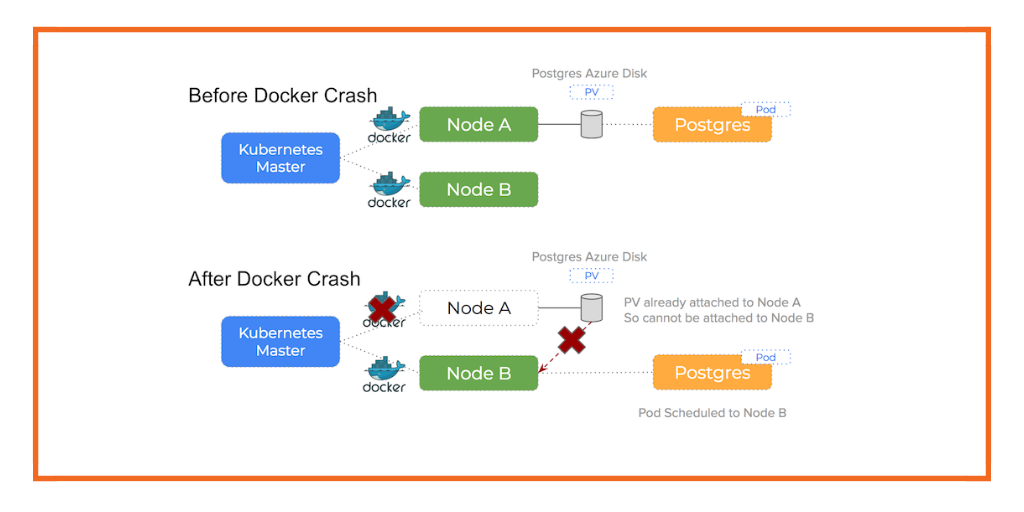
Why do I need Portworx if Kubernetes already has Persistent Claims for EBS Volumes?
The answer is that EBS volumes are not nimble resources and can take minutes to move around the cluster because they can get stuck in an attaching state. EBS stuck attaching is quite a common problem, the result of which is increased time to recovery during failures and even inability to fail over pods at all with manual intervention.
Portworx takes a different approach: It will take your underlying block storage and turn it into a “pool,” with virtual slices of that pool offered as storage to a container. The Portworx volume is replicated at block layer and so in the event of a node failure, the volume with all its data is already present on another node and so failover happens much faster.
Another advantage of using Portworx with kops specifically is that kops uses Auto Scaling Groups to manage the underlying EC2 nodes. As demonstrated in another previous blog post about how to use AWS auto scaling groups (ASG) with Docker, Portworx brings a valuable operational advantage by separating storage from compute and re-using EBS volumes from a previous scale-up operation.
Install Cluster
This guide follows the official AWS installation guide for kops.
Explore Cluster
Once we have our Kubernetes cluster, we should be able to see ours nodes using `kubectl`:
$ kubectl get no
NAME STATUS AGE VERSION
ip-172-20-33-86.us-west-2.compute.internal Ready 6m v1.6.6
ip-172-20-41-10.us-west-2.compute.internal Ready 6m v1.6.6
ip-172-20-57-62.us-west-2.compute.internal Ready 8m v1.6.6
From this point – we have a vanilla Kubernetes cluster that will use EBS drives for stateful container volumes.
The following steps will install Portworx onto our Kubernetes cluster.
Install etcd
We will use the etcd operator to install an etcd cluster.
First – we deploy the actual etcd operator itself:
$ kubectl create -f https://coreos.com/operators/etcd/latest/deployment.yaml
Then we use the operator to create ourselves an etcd cluster::
$ kubectl create -f https://coreos.com/operators/etcd/latest/example-etcd-cluster.yaml
Finally, we create a proxy service so etcd can be accessed by portworx:
$ kubectl create -f manifests/etcd/01-etcd-service-proxy.yaml
Template Volume
Then, we create a template storage volume. Portworx will use the meta-data (size, iops etc) as a template and create a new volume for each node in the cluster.
$ export VOLUMEID=$(aws ec2 create-volume \
--size 100 \
--volume-type gp2 \
--region us-west-2 \
--availability-zone us-west-2a \
--output text \
--query 'VolumeId')
Portworx Deamonset
Portworx runs inside a container on each node (it deploys as a DaemonSet).
First – ensure that your aws access keys are set:
$ cat ~/.aws/credentials
$ export AWS_ACCESS_KEY_ID=$(cat ~/.aws/credentials | grep aws_access_key_id | awk '{print $3}')
$ export AWS_SECRET_ACCESS_KEY=$(cat ~/.aws/credentials | grep aws_secret_access_key | awk '{print $3}')
Portworx will need aws access credentials so it can manage the underlying EBS storage pool, we are passing the keys for simplicity. You can read more about this in the AWS ASG blog post mentioned earlier as kops uses these under the cover to manage Kubernetes nodes.
Finally – we create a URL that will generate our DeamonSet configuration using the values above:
$ export K8S_CONFIG_URL="http://install.portworx.com/?cluster=k8scluster&kvdb=etcd://127.0.0.1:30150&drives=${VOLUMEID}&env=AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID},AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY}&zeroStorage=true"
You can see what the YAML looks like:
$ curl ${K8S_CONFIG_URL}
Then we deploy the DaemonSet to the cluster:
$ curl ${K8S_CONFIG_URL} | kubectl apply -f -
We give Portworx some time to spin up and then we can check everything is working by using the `pxctl` command line tool:
$ ssh admin@api.${NAME} sudo /opt/pwx/bin/pxctl status
Status: PX is operational
Node ID: ip-172-20-53-183.us-west-2.compute.internal
IP: 172.20.53.183
Local Storage Pool: 0 pool
POOL IO_PRIORITY RAID_LEVEL USABLE USED STATUS ZONE REGION
No storage pool
Local Storage Devices: 0 device
Device Path Media Type Size Last-Scan
No storage device
total - 0 B
Cluster Summary
Cluster ID: k8scluster
IP ID Used Capacity Status
172.20.53.183 ip-172-20-53-183.us-west-2.compute.internal 0 B 0 B Online (This node)
172.20.59.181 ip-172-20-59-181.us-west-2.compute.internal 266 MiB 20 GiB Online
172.20.49.178 ip-172-20-49-178.us-west-2.compute.internal 266 MiB 20 GiB Online
Global Storage Pool
Total Used : 532 MiB
Total Capacity : 40 GiB
Notice how Portworx has automatically provisioned new EBS drives for our storage pool and has based their properties on our template volume.
Failover Example
Now we have a fully operational Kubernetes cluster with Portworx, we can see how it copes with a node failure when using a replicated volume.
Using this guide we create a MySQL stateful set with a Persistent Volume Claim
Storage Class
To allow control over the properties of our volumes – we will first create a Storage Class:
kind: StorageClass
apiVersion: storage.k8s.io/v1beta1
metadata:
name: portworx-repl-2
provisioner: kubernetes.io/portworx-volume
parameters:
repl: "2"
This storage class tells Portworx to keep two copies of the volume at all times.
To create this Storage Class:
$ kubectl create -f manifests/ebs-demo/storageclass
Deployment
We then create a deployment that uses a `volumeClaimTemplate` to ask Kubernetes for a volume with 20Gb of storage.
---
apiVersion: v1
kind: Namespace
metadata:
name: test-ebs
---
apiVersion: v1
kind: Service
metadata:
name: mysql
namespace: test-ebs
labels:
app: mysql
spec:
ports:
- port: 3306
name: mysql
clusterIP: None
selector:
app: mysql
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: mysql
namespace: test-ebs
spec:
serviceName: "mysql"
replicas: 1
template:
metadata:
labels:
app: mysql
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mysql
image: mysql:5.6
env:
# Use secret in real usage
- name: MYSQL_ROOT_PASSWORD
value: password
ports:
- containerPort: 3306
name: mysql
volumeMounts:
- name: mysql-vol
mountPath: /var/lib/mysql
volumeClaimTemplates:
- metadata:
name: mysql-vol
annotations:
volume.beta.kubernetes.io/storage-class: portworx-repl-2
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 20Gi
The key line of this manifest is the one where we specify the storage class for our volume claim:
- metadata:
name: mysql-vol
annotations:
volume.beta.kubernetes.io/storage-class: portworx-repl-2
We ask Kubernetes what storageclasses it knows about:
$ kubectl get storageclasses
NAME TYPE
default kubernetes.io/aws-ebs
etcd-backup-gce-pd kubernetes.io/gce-pd
gp2 (default) kubernetes.io/aws-ebs
portworx-repl-2 kubernetes.io/portworx-volume
We can see that `portworx-repl-2` is of type `kubernetes.io/portworx-volume` which means this Persistent Volume Claim will auto-provision a Portworx volume for us and attach it to the pod.
Lets run this manifest:
$ kubectl create -f manifests/ebs-demo/deployment
Create Some Data
At this point we have a running MySQL server – let’s use this guide to simulate failover of a node.
First, we should create some data on our MySQL server:
$ export MYSQLPOD=$(kubectl get pods -n test-ebs -l app=mysql --no-headers | awk '{print $1}')
$ kubectl logs -n test-ebs $MYSQLPOD
$ kubectl exec -n test-ebs -ti $MYSQLPOD -- mysql --user=root --password=password
mysql> create database TEST_1234;
mysql> exit
At this point there is a database called `TEST_1234` created on our MySQL server.
Cordon the Node
Then we cordon the node that is currently running our MySQL server and then remove the MySQL pod itself. Because we are running a stateful set, this will trigger Kubernetes to re-schedule a new Pod to another node (simulating the original node failing).
First let’s discover the node that is running our MySQL server:
$ export MYSQL_NODE=$(kubectl describe -n test-ebs pod -l app=mysql | grep Node: | awk -F'[ \t//]+' '{print $2}')
$ echo $MYSQL_NODE
Then we `cordon` that node:
$ kubectl cordon $MYSQL_NODE
Finally we delete the MySQL pod:
$ kubectl delete pod -n test-ebs -l app=mysql
$ kubectl describe pods -n test-ebs -l app=mysql
Check the Data Moved
Kubernetes has kicked in and re-scheduled the MySQL Pod to another node. The volume claim that pods refers to has a replication setting of 2 meaning the original data was being synchronously replicated and so the new MySQL Pod starts off where it left off before the failure.
Because Portworx is not attaching block devices to different nodes (which is what vanilla Kubernetes on AWS would do) – the total time to failover is much less. You can read more about that in this blog post
We can check that our data is intact by connecting to the new MySQL pod:
$ export MYSQLPOD=$(kubectl get pods -n test-ebs -l app=mysql --no-headers | awk '{print $1}')
$ kubectl exec -n test-ebs -ti $MYSQLPOD -- mysql --user=root --password=password
mysql> show databases;
+---------------------+
| Database |
+---------------------+
| information_schema |
| TEST_1234 |
| #mysql50#lost+found |
| mysql |
| performance_schema |
+---------------------+
5 rows in set (0.00 sec)
Uncordon the Node
Now bring the node back online:
$ kubectl uncordon $MYSQL_NODE
Summary
This hands on guide has shown you how to install and operate Portworx on an AWS Kubernetes cluster. As demonstrated, there are various advantages to using Portworx in this situation.
Another advantage of using Portworx alongside kops specifically is the integration with Auto Scaling Groups (demonstrated in this post). This means Portworx will manage our underlying EBS pool and be able to re-use previous EBS volumes after a scale up/down/up operation.
Want to learn more about Kubernetes persistent storage? Be sure to checkout our documentation for running Portworx on Kubernetes!
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Kai Davenport
Kai has worked on internet-based systems since 1998 and currently spends his time using Kubernetes, Docker and other container tools and programming in Node.js and Go.



Architect's Corner: Hugo Claria of Naitways talks Kubernetes storage