

To jump directly to MySQL specific backup information. Jump to the below section.
Kubernetes runs mission critical applications in production; that is a fact. Running applications—especially stateful applications in production—requires care and planning. We have covered how to run a highly-available MySQL service on Kubernetes in production already, and now we are going to focus on the best way to protect your data services in production with backup and restore.
Here are some of the things you need to ask yourself when protecting MySQL with backup and restore on Kubernetes in production:
- What Kubernetes objects do I need to backup?
- How can I backup my PersistentVolumes (PVs)?
- Where do my backup files live?
- How long do my backups remain available?
- Can I restore to another Kubernetes cluster?
- Who has access to my backups?
- Who can take a backup?
- Can I take backups on a set schedule?
- How long will my backups take?
- Are my backups secure?
This blog post will aim to answer most of the questions you may be asking and provide a clear guide on how to backup MySQL on Kubernetes in production.
The essential steps to backup MySQL on Kubernetes
When you are creating a backup and restore strategy, it is important to remember that not every data service needs the same level of protection. In production, we typically need the best level of protection that fits our business needs as well as those of our customers. Given this, it’s best to understand the essential steps for creating a backup and restore plan in production.
- Understand WHO will be responsible for creating backups.
- Know what level of RPO (recovery point objective) you require.
- Make sure you know where your backup targets will be located.
- Plan out what type of schedule and retention plan your backups need.
- Make sure any application-aware hooks are in place so your backups are app-consistent.
We’ll walk through and explain these critical steps for backing up MySQL in production in more detail as well as provide examples and screenshots below.
Performing backup and restore for MySQL
Before we can backup MySQL, we must first configure PX-Backup with the access to the cluster which it is running in.
> Note, this blog does not go into installing PX-Backup; for this, please reference our documentation.
Within the PX-Backup interface, select Add Cluster from the navigation.

Then you will need to provide a cluster name and a Kubeconfig for the Kubernetes cluster you are using as well as the Portworx details if you have access to them. Keep in mind that the Kubeconfig is what controls the type of access you have to the cluster, and the same is true within PX-Backup. If you only have access to one namespace, you will only be able to set up backup and restore for that namespace. Also, if you do not have access to the Portworx cluster details or are not using Portworx for volumes, you can leave that section blank.
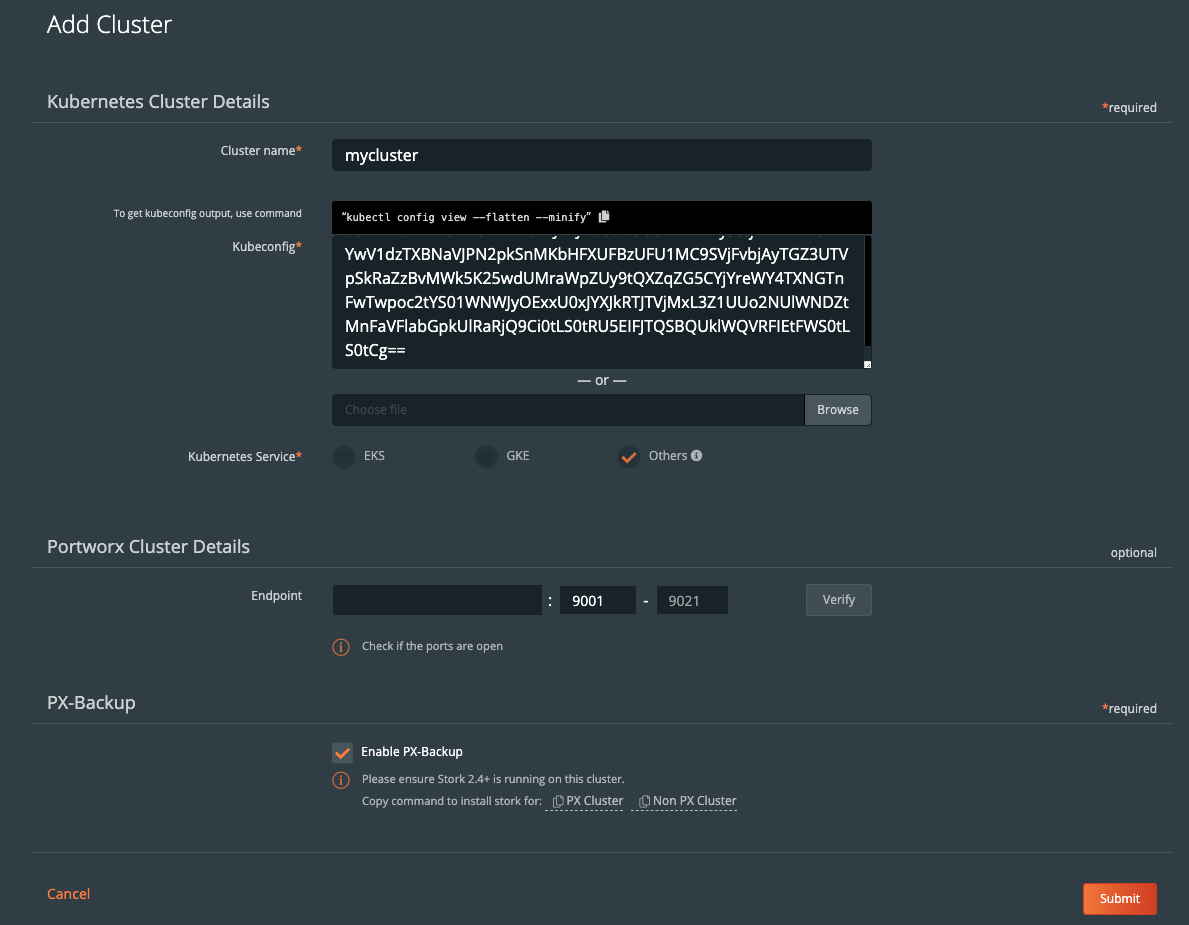
Once you have done this, you should see your cluster added to the main screen. There should be a green backup icon in the cluster tile that will bring you to the backup view for the cluster.

If your backup icon is not green, double check that you are running Stork 2.4+ in the cluster you added.
> Refer to the Add Cluster screen within the backup UI. You can easily copy the command to add stork to your cluster.
(Running Portworx)
KBVER=$(kubectl version --short | awk -Fv '/Server Version: /{print $3}') curl -fsL -o stork-spec.yaml "https://install.portworx.com/2.5?kbver=${KBVER}&comp=stork" kubectl apply -f stork-spec.yaml(Not running Portworx)
curl -fsL -o stork-spec.yaml "https://install.portworx.com/2.5?comp=stork&storkNonPx=true" kubectl apply -f stork-spec.yaml
Configure your backup targets
Before we can backup MySQL from our cluster, we must create a backup target location. Click on Cloud Settings to be taken to the location where you can input your target credentials and bucket information.
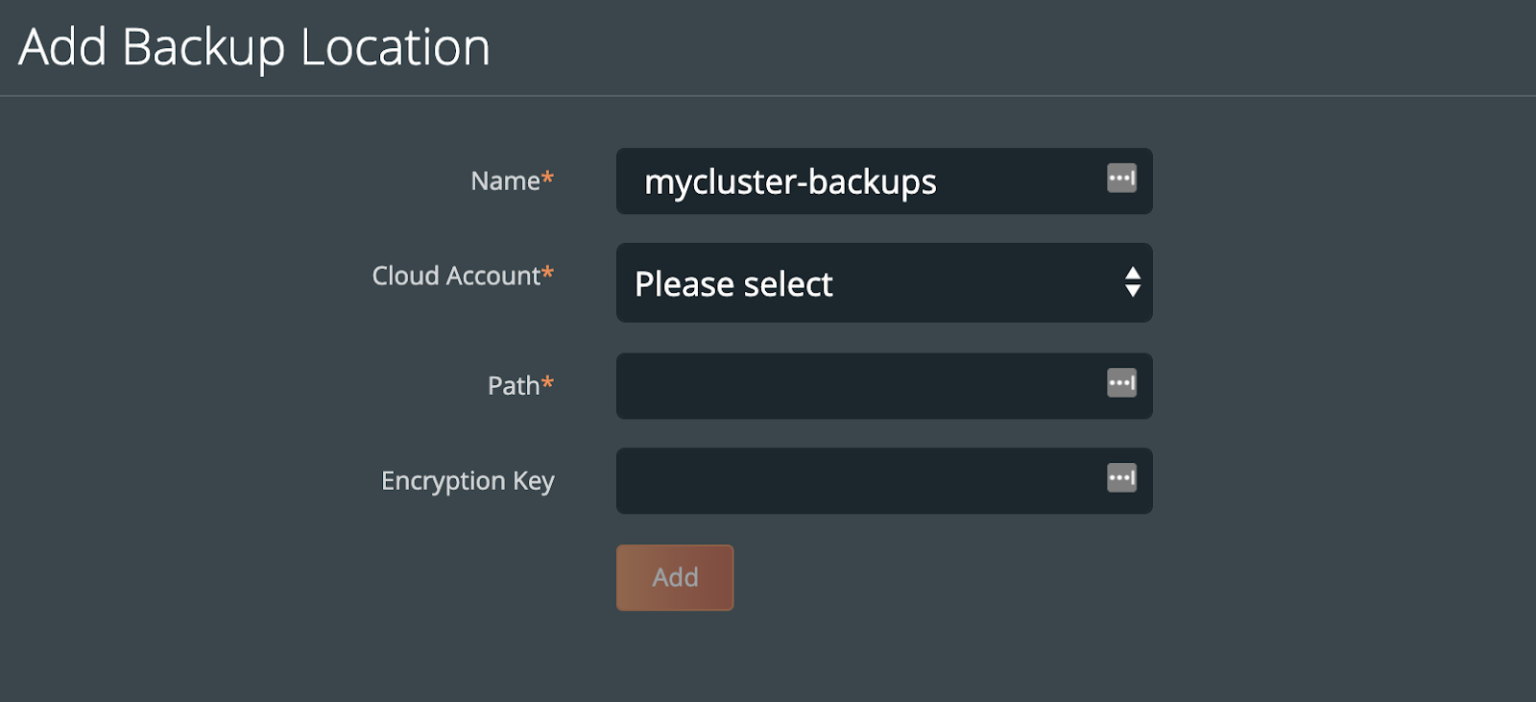
You can follow our documentation on how to set up various backup targets. At a minimum, you will need to create both a single Cloud Account (e.g., AWS, Azure, Google) and a Backup Location (e.g., bucket in cloud object store).

![]()
When you create a backup location, you will select the previously created Cloud Account and then fill in the bucket information accordingly for your backup target provider.
Consider characteristics of the backup location. Retention of data within the backup location as well as the geographic location of the location are not configured by PX-Backup and thus should be carefully configured prior to using the location.
To make sure backups are encrypted within the backup location, enter an encryption key of your choice.
Create a backup schedule
This step is optional. However, using a schedule enables point in time recovery (PITR) of applications. Using a schedule will provide the PITR points that can be used.
You may want to create a schedule specifying how often your backup takes place (that allows you to meet your RPO objectives) and how many copies of the backup are to be kept (if you need RPO zero, check out kubernetes disaster recovery). Click Schedule Policies from the settings navigation, and this will bring you to a view where you can configure your schedules.
Click the Add button in the navigation bar.
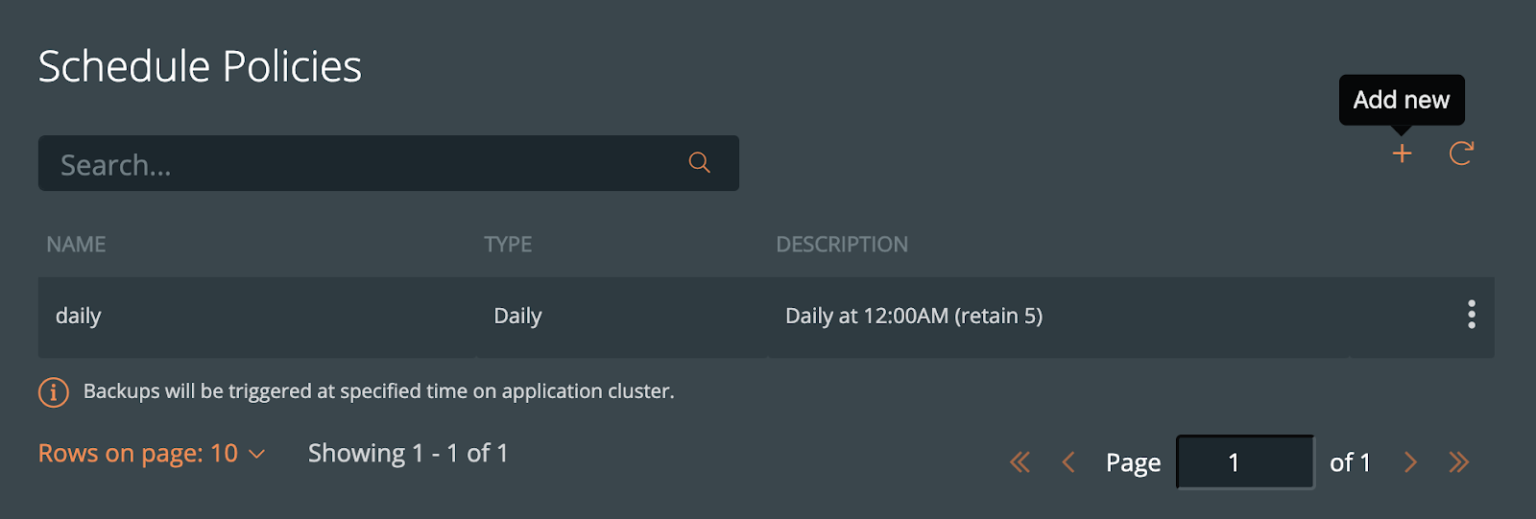
From here, create your desired schedule. When you choose Periodic, Daily, Weekly, or Monthly, you will then be able to select the number of retained copies. Later, you will be able to select this schedule when we create our backup for MySQL.
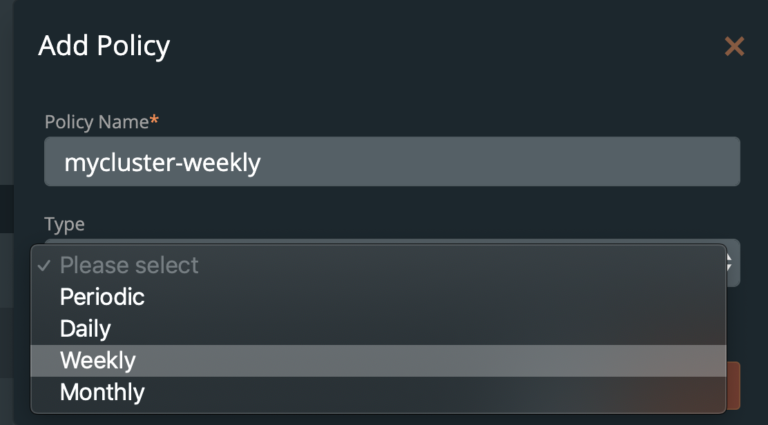
Pre- and post- rules for creating application-consistent MySQL backups
Backups should be taken when the system can verify that the data service is ready for a backup. This is called application awareness. For this reason, we may want to control logic that happens before and after a backup is triggered to help control consistency based on the above information. With PX-Backup, we configure pre- and post- rules that can run arbitrary commands inside one or more pods of the data service to achieve these goals.
First, we need to understand how MySQL stores states. This will ultimately help provide a blueprint for our backup policies and rules in production.
Information managed by MySQL server is stored in a location called the data directory. Often, this data directory is located in the MySQL server filesystem at /var/lib/mysql. Within this location are the files and data that are vital for MySQL to persist information, and this is why it’s important to mount Kubernetes PersistentVolumeClaims (PVCs) to the data directory location that the MySQL image uses. In Kubernetes, the spec file volumeMount may look like this:
volumeMounts: - name: mysql-data mountPath: /var/lib/mysql volumes: - name: mysql-data persistentVolumeClaim: claimName: mysql-data
Within the data directory, MySQL stores schema, table, logs, configuration and database data that corresponds to system, performance, and client data. Mounting a PersistentVolume enables PX-Backup to snapshot and back up MySQL data when needed.
MySQL has a tool called mysqldump which works well for taking backups specific to MySQL. Since PX-Backup can provide abstracted backup and restore for a polyglot of data services, we can replicate the best practices of mysqldump, such as flushing and locking logs and tables into PX-Backup’s pre- and post- backup rules. PX-Backup rules and backups can be used across multiple instances of MySQL and multiple types of clouds. This will ultimately simplify operations for DevOps teams for single or multi-cloud workflows.
Pre- rule for MySQL
Before a backup of MySQL occurs, it is recommended to flush certain data to disk so that the backup remains consistent. Database tables and logs are examples of data that should be flushed. It is also important in MySQL to LOCK the tables so no new I/O transactions attempt to add records during the backup, or MySQL may also become inconsistent.
To accomplish this, we can implement a FLUSH TABLES WITH READ LOCK command in our pre-backup rule. This will perform the following operations:
(FLUSH TABLES WITH READ LOCK) – Closes all open tables and locks all tables for all databases with a global read lock. This is a very convenient way to get backups if you have a file system such as Veritas or ZFS that can take snapshots in time. Use UNLOCK TABLES to release the lock.
Since PX-Backup performs a snapshot of the persistent volume in Kubernetes, this will accomplish what we are looking for.
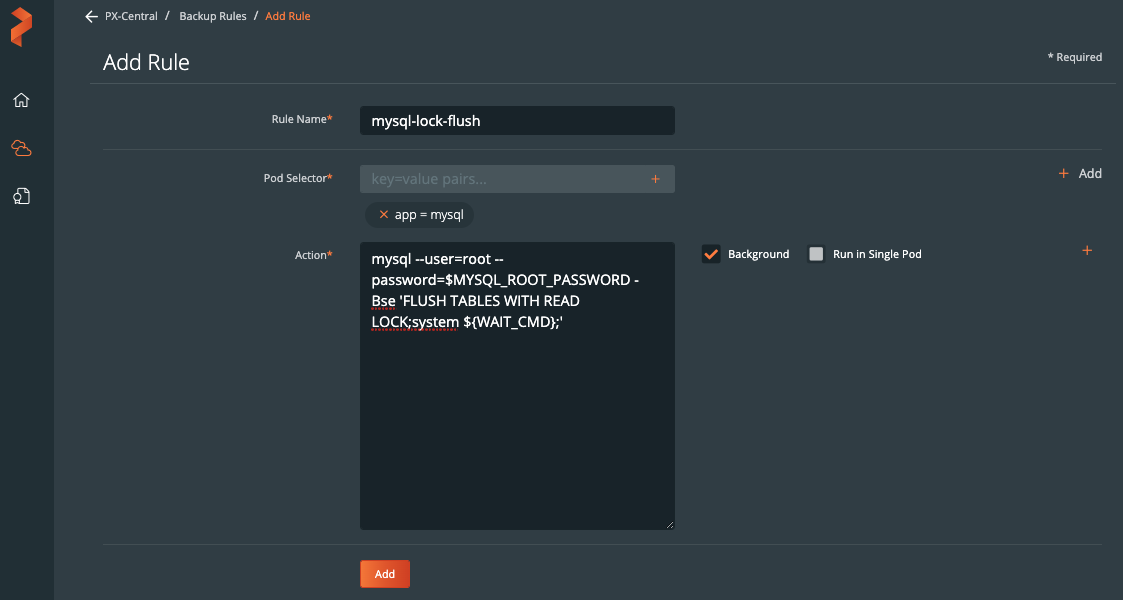
Create this rule within the PX-Backup interface.
Note: We set this rule to run in the background, which requires a WAIT_CMD to allow the rule to execute and exit properly.
The action will use an administrative MySQL user to run the FLUSH TABLES command. In this case, our MYSQL user, root has a password available via the environment variables within the pod.
mysql --user=root --password=$MYSQL_ROOT_PASSWORD -Bse 'FLUSH TABLES WITH READ LOCK;system ${WAIT_CMD};'
The above command can be added to the “Action*” text box in the PX-Backup interface.
Post- rule for MySQL
Since we made sure to flush and lock data from MySQL before our backup, we must make sure to UNLOCK the database from the global read lock. MySQL documentation tells us that this is because global locks are not implicitly unlocked after the FLUSH TABLES WITH READ LOCK operation. It also may be a good idea to FLUSH LOGS, which “Closes and reopens any log file to which the server is writing” and updates the sequence number of the log. This may be required if users need a clear distinction between logs before and after a backup occurs. Flushing logs is optional here but will add it to our post- backup rule for completeness.
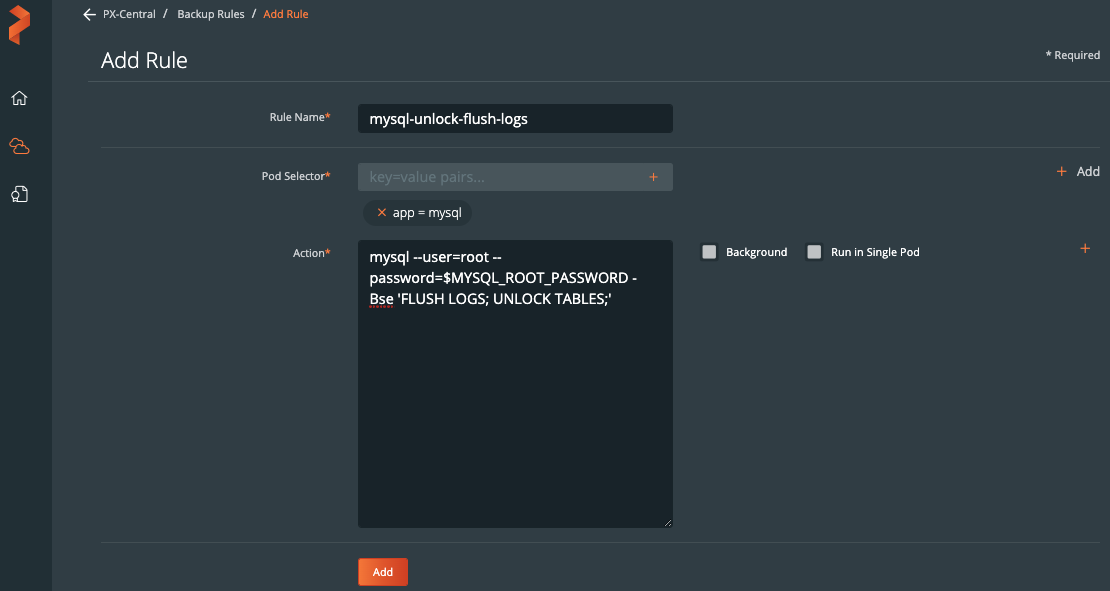
Create this rule in the PX-Backup interface.
Note: Post- backup rules are not allowed to run in the background, so a WAIT_CMD is not needed.
Use the same user to run the FLUSH LOGS and UNLOCK actions.
mysql --user=root --password=$MYSQL_ROOT_PASSWORD -Bse 'FLUSH LOGS; UNLOCK TABLES;'
The above command can be added to the “Action*” text box in the PX-Backup interface.
Create the backup for MySQL
Now that configuration is done and we have created rules for our application, we are ready to start backing up MySQL. What we need to do is enter the backup view of the cluster our service is running in and select the namespace that our application is running in.
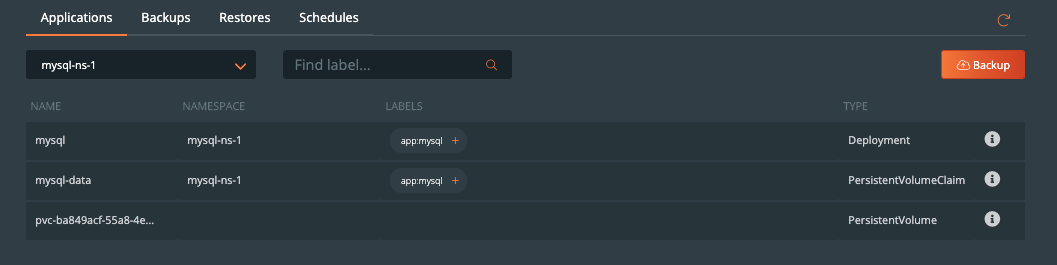
Once you are in the namespace, you can select the labels associated with MySQL to only backup certain objects with the label or backup the entire namespace by selecting the Backup button in the top right corner of the namespace backup view.

Once you are into the backup-specific input, give the backup the following information in the pop out menu:
- Name
- Backup Target
- Backup Now or On a schedule
- Provide Pre- and Post- rules
- Optional backup labels for accounting
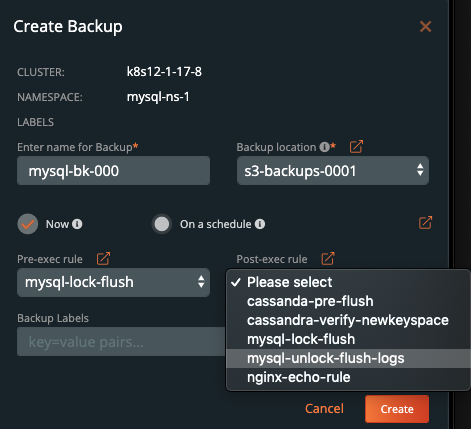
Once you complete this information, click Create.

Once created, the backup will enter a Pending and then an In Progress state. The backup icon will look like the below example.

To view the progress of what is happening in the backup, you can select the navigation to the right side of the backup and select the Show Details button. This will allow you to view the current status and metadata of the associated backup. Any progress or errors will be reported within this screen.
Part of this information will be the status of the pre- and post- rules we created earlier. When they are being executed, it will be reported as in progress, and any output or errors will be present within this screen if there is an issue.

Once the rule is executed, it will continue and start to back up the volumes, and the details will change. An example of these details can be seen below.
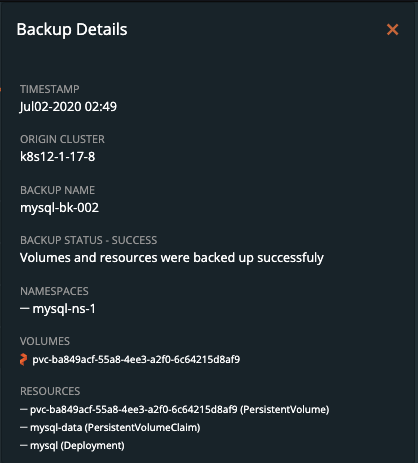
Upon successful completion of the backup, the icon will look like the below example.

If something goes wrong, you will notice the icon turn red, and details of the failure will be available in the Show Details section of the backup.

Restoring MySQL from backup
To start a restore, select Backups from the top navigation bar.

Then find the backup you wish to restore and select the Restore selection from the right navigation.
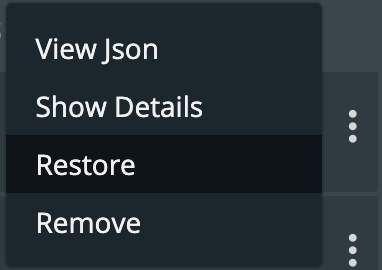
From here you can provide a name for your restore and a destination cluster as well as the following options.
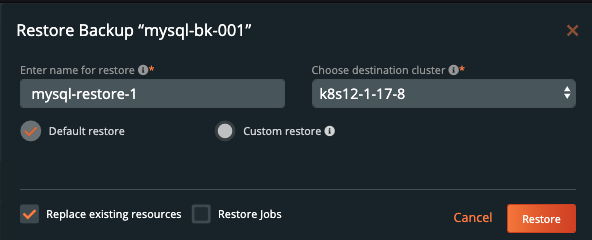
- Default restore
- This will restore the backup to the namespace which it came from. Take note of the “replace existing resources” option when using this method.
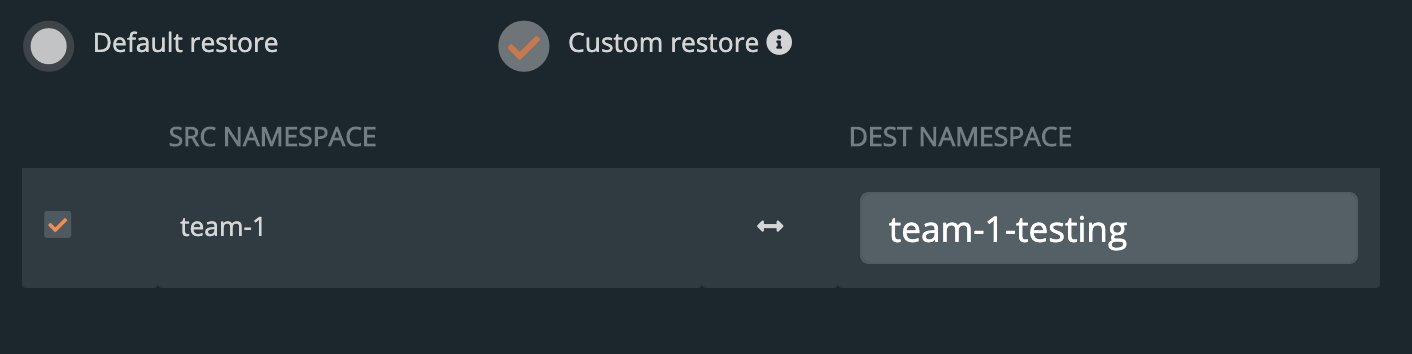
- Custom restore
- This will allow you to provide a new namespace name to restore your backup to. Note that this namespace does not need to pre-exist.
- Replace existing resources
- This will make sure the restore operation overwrites the objects that may already exist. Note that objects will be deleted then re-created.
- Restore Jobs
- Jobs often run once and complete. It is not always necessary to run these jobs again—especially when restoring to the same cluster where the backup was taken. However, it may be necessary when restoring to a new cluster or new namespace.
You should see a similar transition in the UI from Pending to Success, and you can select Show Details from the menu—just like with the backup—to get the active information about the backup.
→
Demo
Conclusion
As we’ve just seen, backup and restore is a critical piece of the data protection plan for any application in Kubernetes today. PX-Backup makes it simple to understand who, when, where, and how the backup takes place—all while making it hyper configurable to specific data services for extra consistency and application awareness. Remember to check out the documentation on backup—as well as take advantage of a free trial.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Ryan Wallner
Portworx | Technical Marketing ManagerExplore Related Content:
- apache
- backup
- kubernetes
- mysql
- restore



