This post is part of our ongoing series on running Kafka on Kubernetes. We’ve published a number of articles about running MySQL on Kubernetes for specific platforms and for specific use cases. If you are looking for a specific Kubernetes platform, check out these related articles.
Running HA Kafka on Azure Kubernetes Service (AKS)
Running HA Kafka on Google Kubernetes Engine (GKE)
Running HA Kafka on Amazon Elastic Container Service for Kubernetes (EKS)
Running HA Kafka on Red Hat OpenShift
And now, onto the post…
The Kafka platform has become a core component in IoT and Machine Learning deployments including as an ingestion layer for IoT sensors and as the pipeline for Machine Learning.
One of the key considerations for Kafka has been how to handle storage. On AWS, the best practice for running Kafka with EC2 virtual machines has been to leverage instance store (ephemeral storage) with larger Kafka deployments and EBS for smaller Kafka deployments. As teams containerize their backend services, we show how they can continue to run Kafka but now using containers scheduled by Amazon Elastic Container Service (ECS) and with storage managed by Portworx.
Teams can then flexibly deploy Kafka brokers across one or more AWS Availability Zones based on their business needs, where the latter is depicted below.
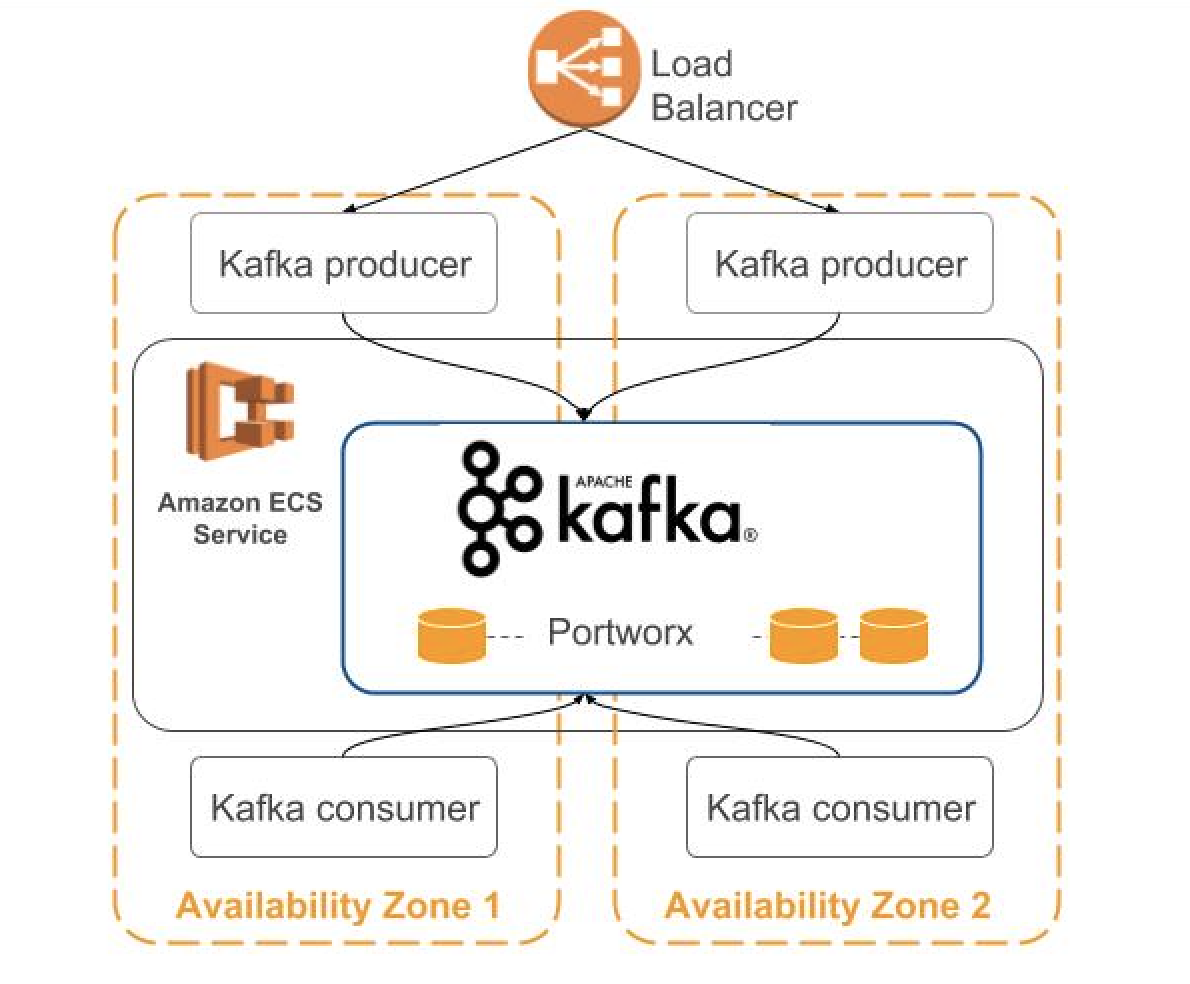
By running ECS, teams get a powerful container orchestration service without needing to install and operate their own container orchestration software to manage, scale, or schedule a cluster of virtual machines. By running Portworx, teams get container-level storage, faster recovery times, and can leverage instance store for local storage. Now, with support for Docker volumes, ECS can integrate with volume plugins such as Portworx.
Installing Portworx through ECS
Our first step is to set up an ECS cluster of EC2 launch type called pxdemo-1. (See here for background steps on ECS.) As part of the cluster configuration, we select the i3.XL instance type with local NVMe storage. While local storage provides I/O performance benefits for Kafka brokers, two traditional concerns have been (a) what happens when a Kafka broker fails and needs to rebuild and (b) how to handle capacity needs.
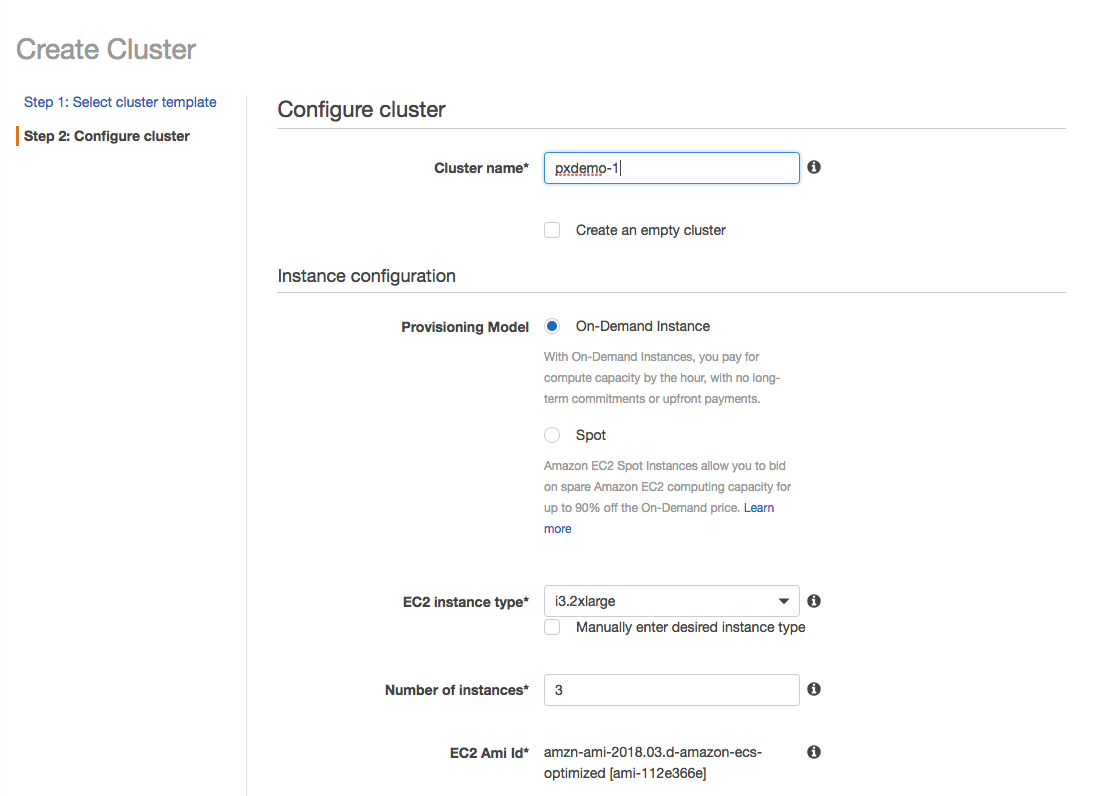
Addressing these concerns, we leverage Portworx for data protection and capacity management. Portworx will replicate each container’s volume data among (a quorum of) ECS instances across Availability Zones. Also, Portworx will add additional EBS volumes based on reaching capacity thresholds.
Next, we create a Task Definition,
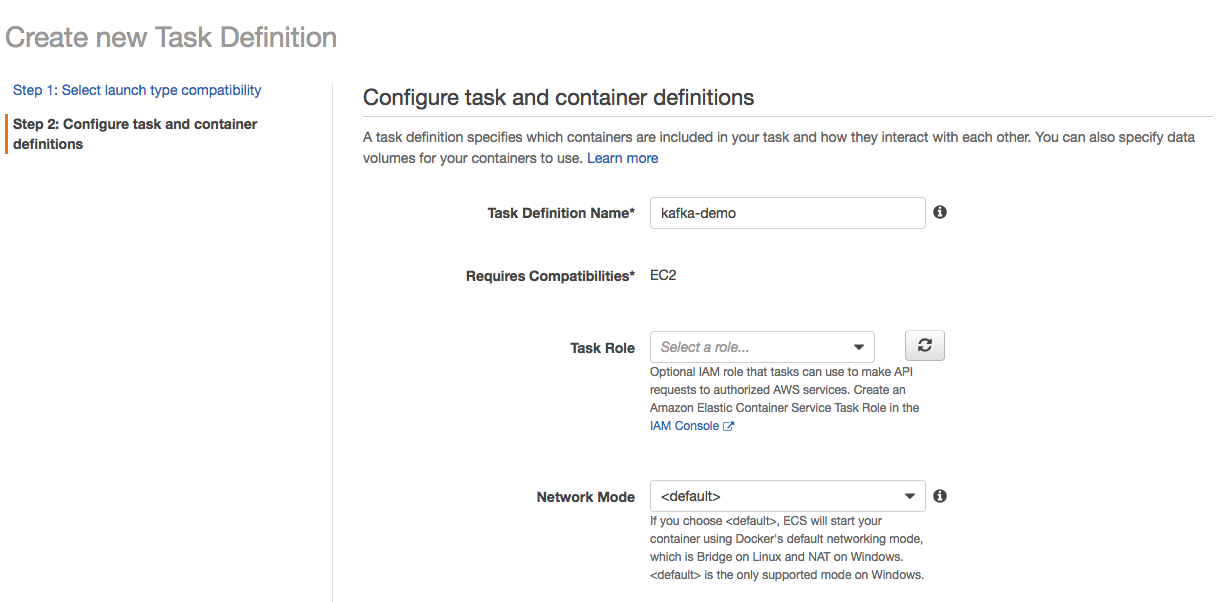
We then create a service, utilizing ECS’ Daemon scheduling to deploy one task on each instance. This ensures that every instance in the ECS cluster will have access to Portworx storage volumes.
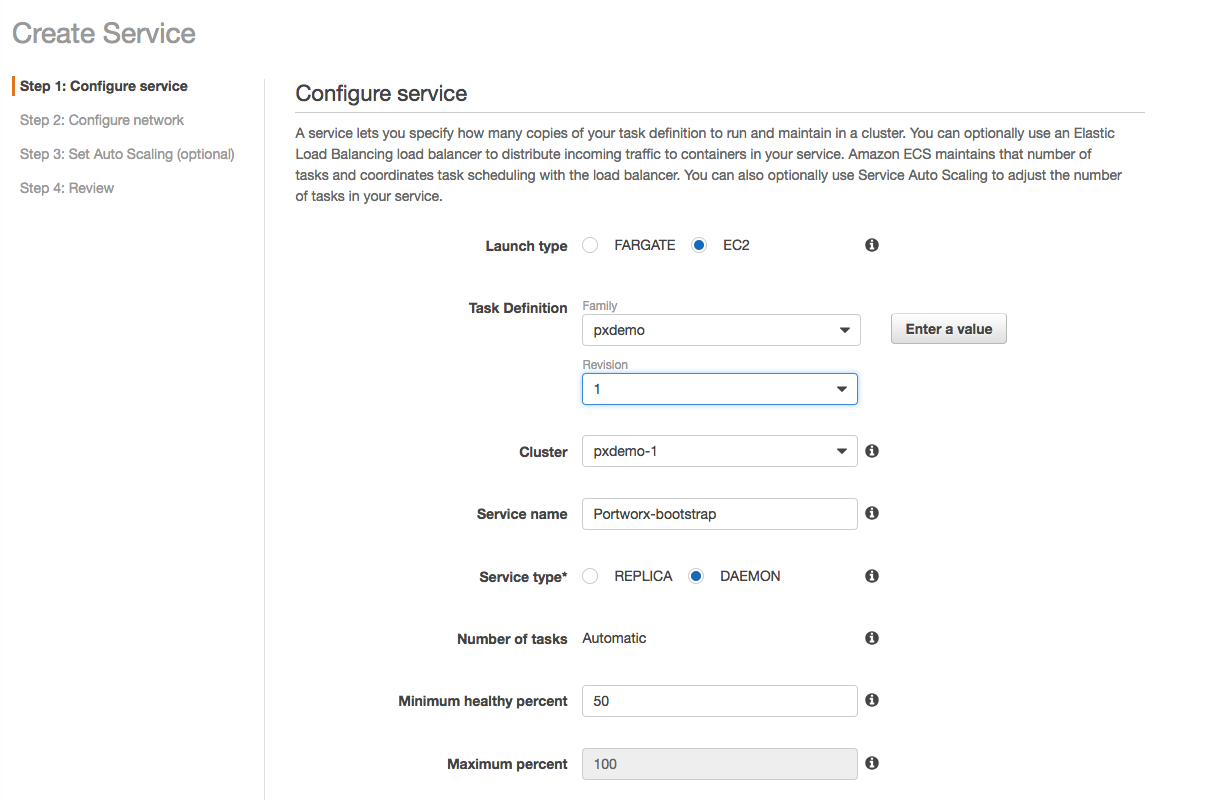
Note that Portworx takes a cluster identifier in the Task Definition, which should be unique for each ECS cluster.
Writing a Task Definition for Kafka with Portworx Volumes
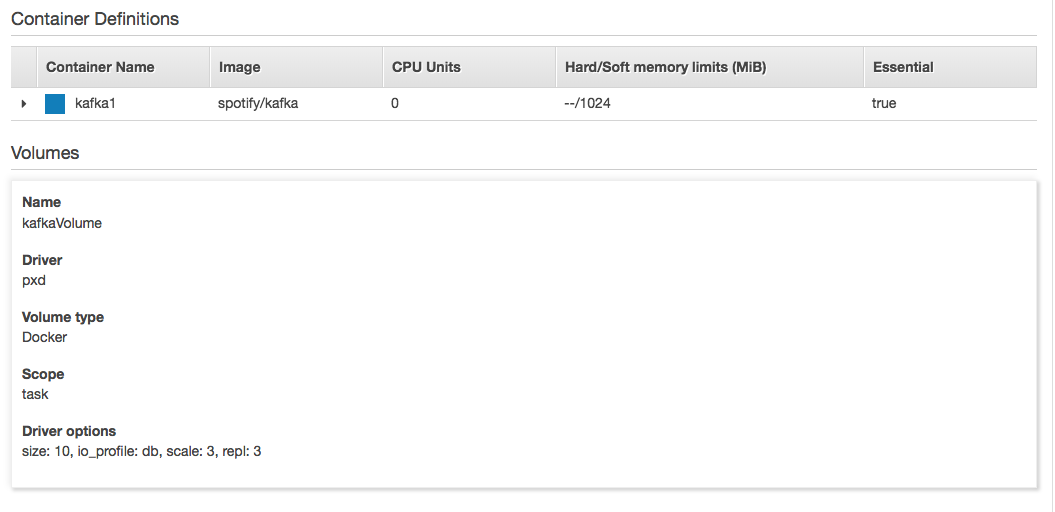
We next write a Task Definition for Kafka to use Portworx storage volumes. Portworx storage volumes are dynamically created by application containers and (as a default) exclusive to that container. The Task Definition for Kafka is created as shown below.
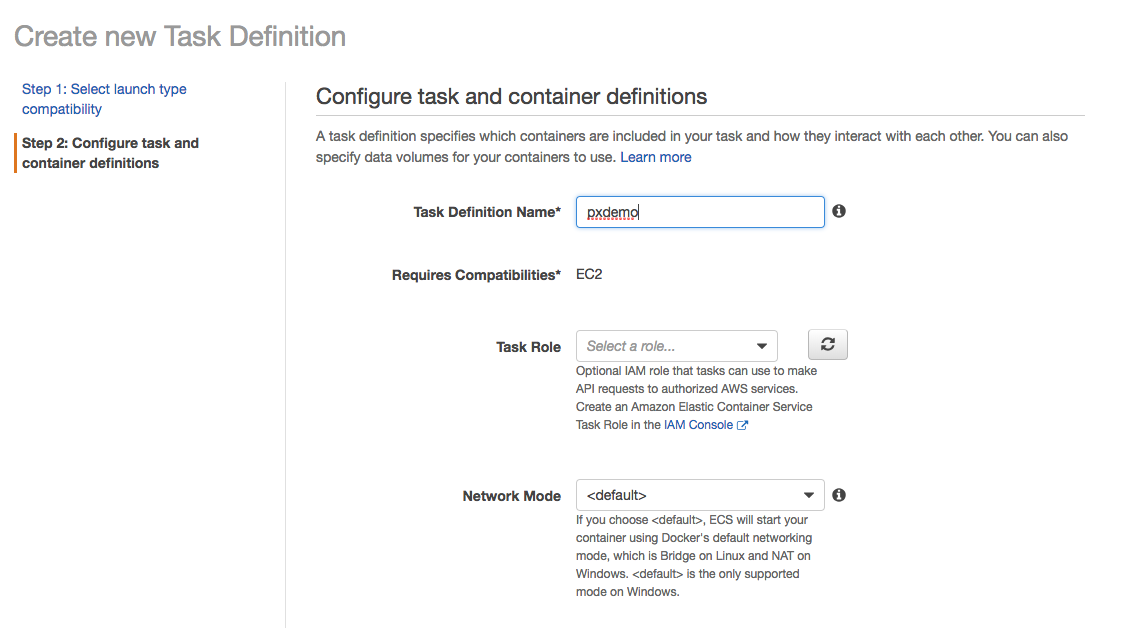
In this Task Definition, we specify the container image (Kafka), the volume name (kafkaVolume), and the storage provider as Portworx (driver:pxd). And since Portworx dynamically creates container volumes, we can then set the storage behavior using parameters in the Task Definition. As shown in the JSON here, we set the volume size (10 GiB), elect to use block-level replication (repl: 3), and request creating multiple volumes based on this template (scale: 3).
The templatized volume creation option is necessary as we will later create a service of type REPLICA, using the Kafka Task Definition, to launch multiple ECS Kafka tasks In the diagram below, we can depict each Kafka broker container as a numbered box (1, 2, 3). Template volume creation then gives each container its own, unique Portworx volume while using a single Task Definition.
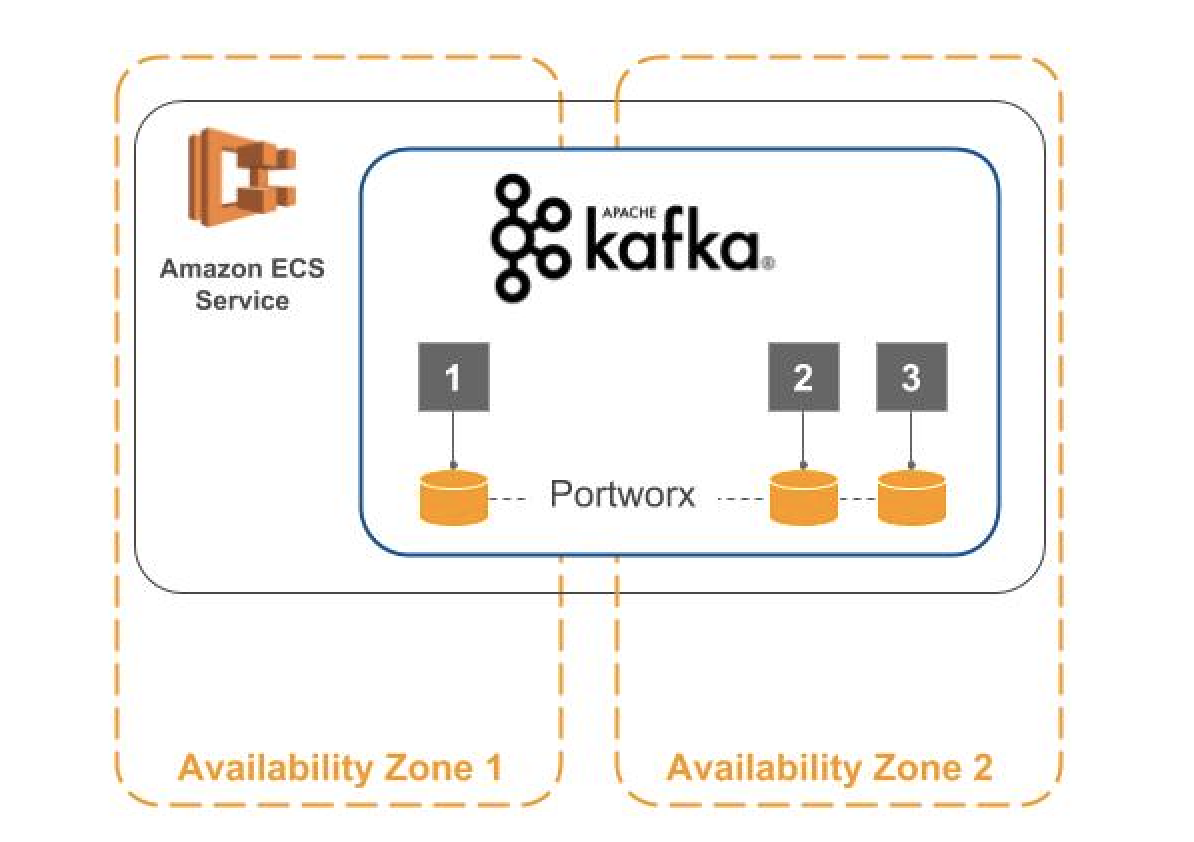
Now as the ECS service runs, each Kafka broker container gets its own Portworx volume. And because we enabled Portworx replication in our Task Definition, Kafka can use a replica volume if a broker or instance dies. In such a failover case, ECS will relaunch Kafka with the same volume name. Here, the new broker joins the Kafka cluster faster — as starting from a replica volume reduces the data transfer required. Additionally, a Portworx replicated volume can be accessed (mounted) from another ECS instance, including in an instance in another Availability Zone.
Launching the ECS Service with Kafka and Portworx
In order to realize the diagram above, we now just need to create an ECS service using the Kafka Task Definition. As shown below, the Service will use the Task Definition (kafka-demo), and we set the Service name (kafka-broker).
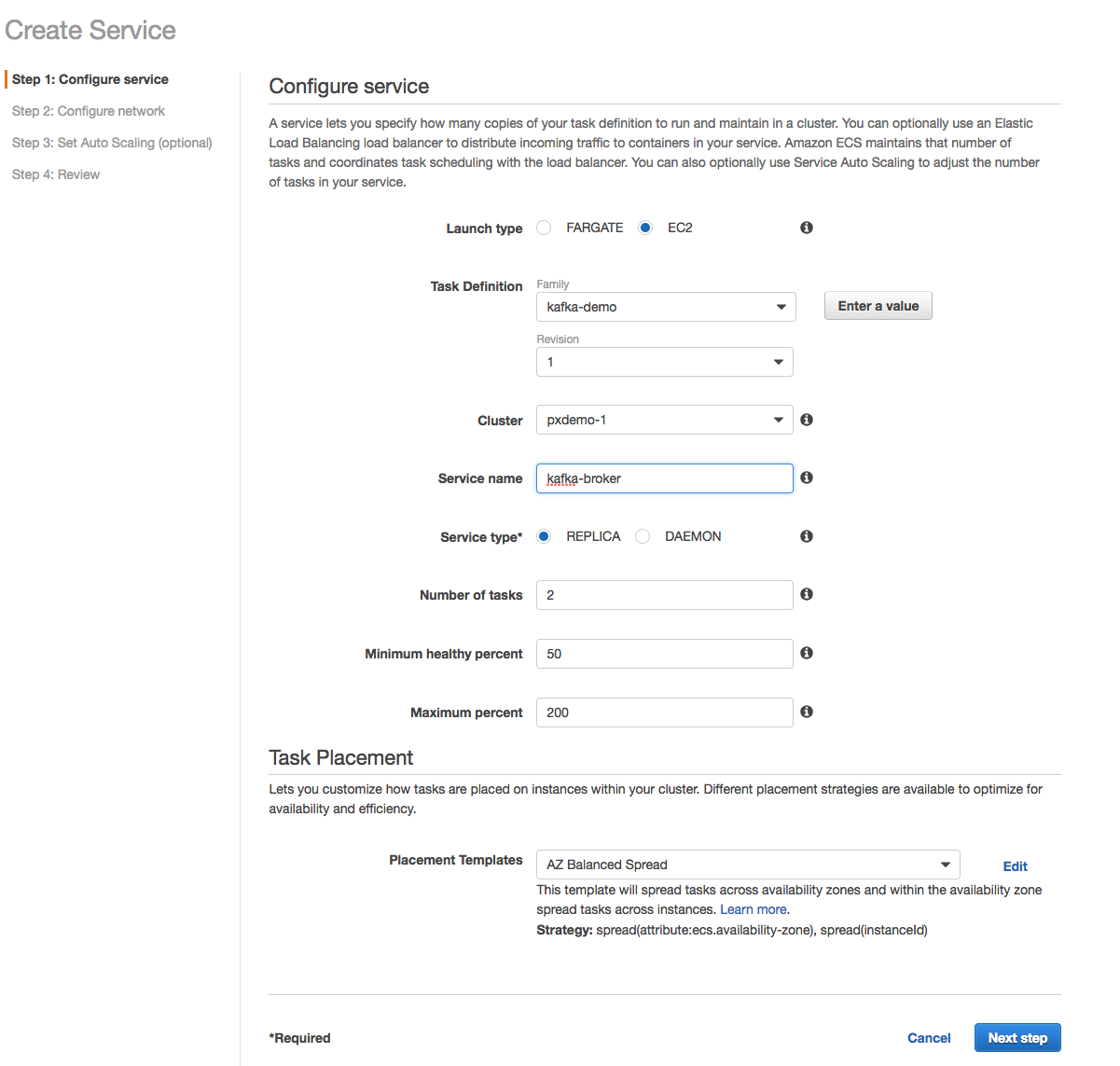
In the above Service, we want multiple Kafka brokers, so we select Service type REPLICA and set the Number of tasks to two. ECS will then launch two Kafka broker containers as independent tasks and place the containers using the AZ Balanced Spread strategy. Afterwards, we can see the Service we just created in our cluster as shown below.
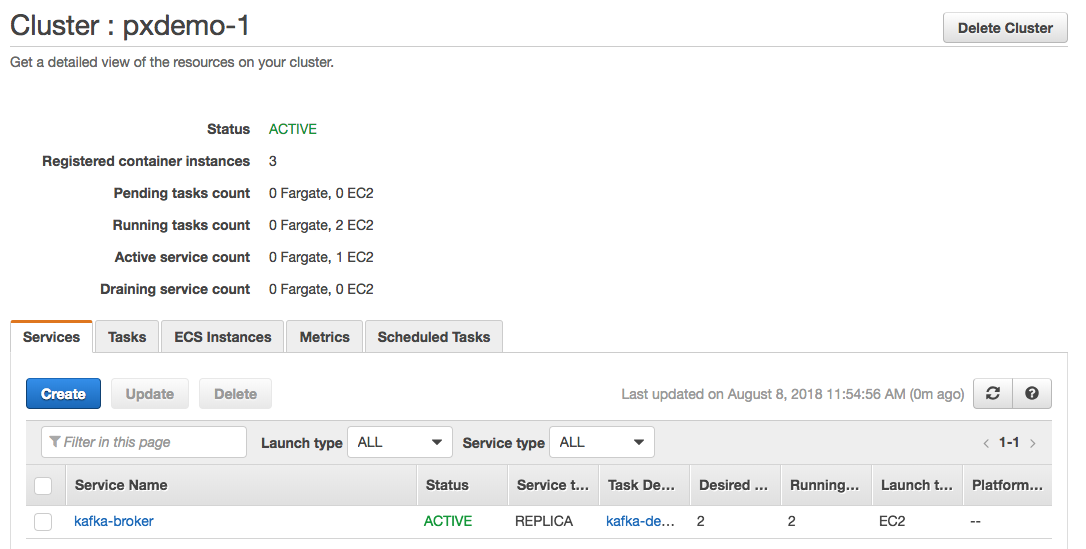
Clicking on the Service itself, we can then look at the details set by the Task Definition, including the Storage options.
Now, we have an up and running Kafka broker that we can write to and consume from. ECS will handle the scheduling, scaling, and availability. We can reuse Task Definitions and add more container-based Services, all relying on the power and flexibility of ECS and Portworx.
Summary: Dynamic Applications with Dynamic Storage
In this blog, we shared how teams can leverage ECS for container scheduling and Portworx for container storage. We selected an application platform, Kafka, that has become a necessary and powerful building block in IoT processing and Machine Learning use cases. With Portworx, Kafka can take advantage of faster recovery times and get the benefits of containers. Consider taking a look at our DBaaS solution and resources for more information.
As additional applications get scheduled on the same ECS cluster, ECS manages the compute, and Portworx continues to manage the storage. And with each new application, container volumes are dynamically created, reducing the amount of manual tasks such as pre-provisioning and right-sizing infrastructure. The benefit here (that we all value) is that teams can now focus on data rich applications and not the infrastructure.
Please give this new integration a try and share your feedback with us. Thanks!
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!