




Portworx is a cloud native storage platform to run persistent workloads deployed on a variety of orchestration engines, including Kubernetes. With Portworx, customers can manage the database of their choice on any infrastructure using any container scheduler. It provides a single data management layer for all stateful services, no matter where they run.
Kubemotion is one of the core building blocks of Portworx storage infrastructure. Introduced in Portworx Enterprise 2.0, it allows Kubernetes users to migrate application data and Kubernetes application configurations between clusters, enabling migration, backup & recovery, blue-green deployments, and more.
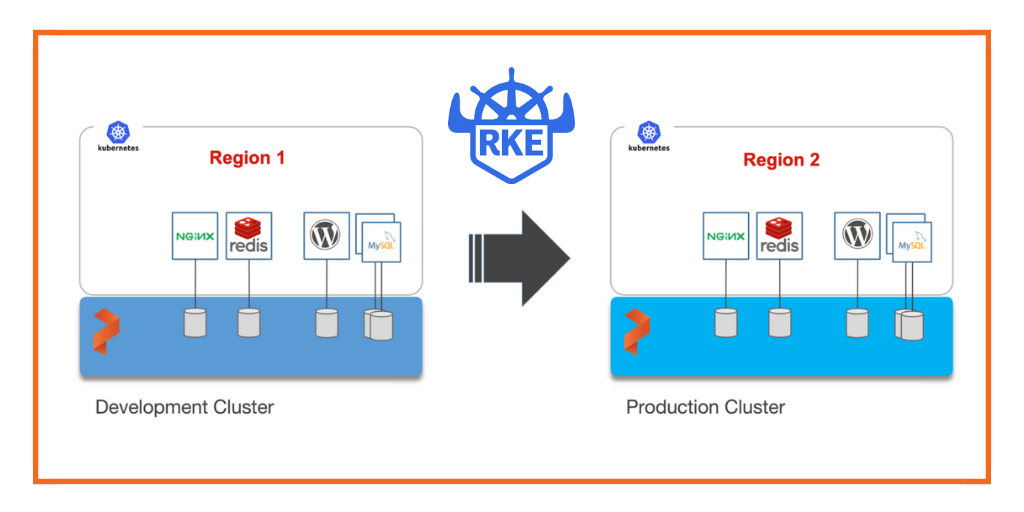
This step-by-step guide demonstrates how to move persistent volumes and Kubernetes resources associated with a stateful application from one Rancher Kubernetes (RKE) cluster to another RKE cluster running in a different region.
For enterprises, a common scenario is to run development and test environments in one cloud region and the production environment in another. Development teams may choose a region that’s geographically closer to them while deploying production applications in another region that has low latency for the users and customers.
Even though Kubernetes makes it easy to move stateless workloads across environments, achieving parity of stateful workloads remains a challenge.
For this walkthrough, we will move Kubernetes resources between RKE clusters running in the Asia Pacific South (Mumbai) and Asia Pacific Southeast (Singapore) regions of AWS. The Mumbai region is used by the development teams for dev/test and the Singapore region for the production environment.
After thoroughly testing an application in dev/test, the team will use Portworx and Kubemotion to reliably move the storage volumes and application resources from the development to the production environment.
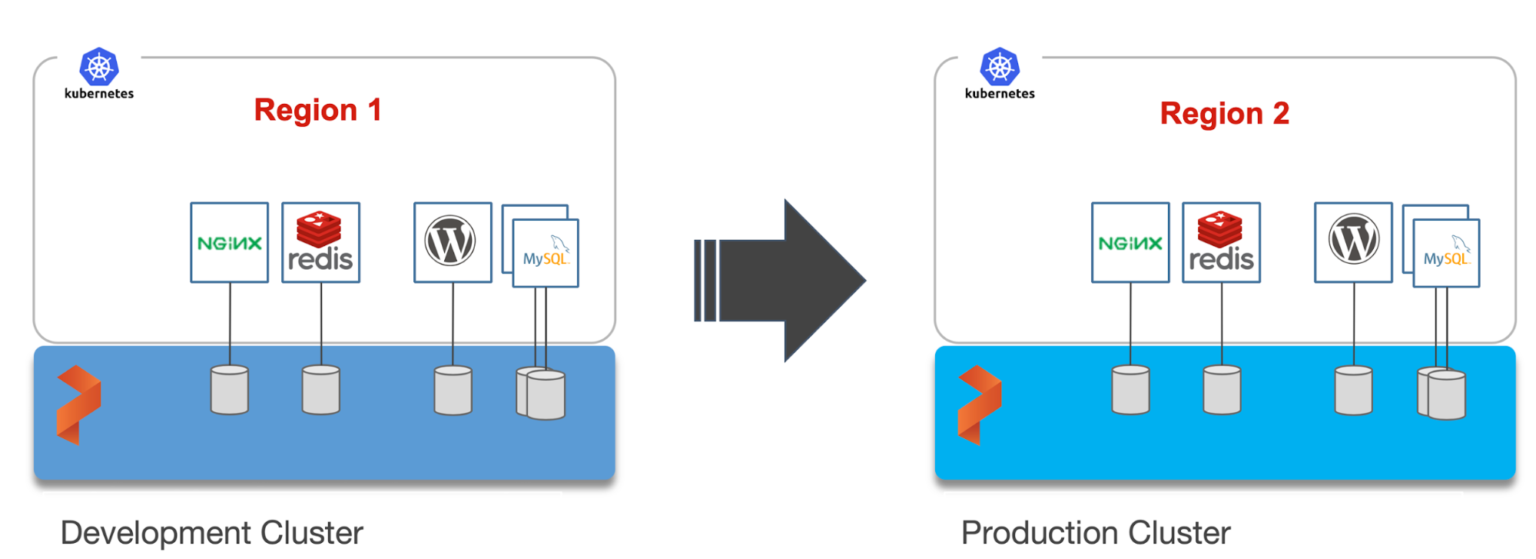
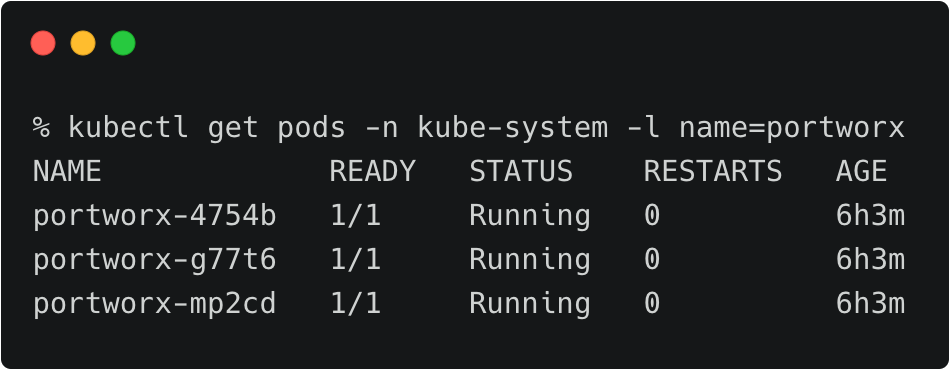
We have two RKE clusters—dev and production—running in the Mumbai and Singapore regions of AWS. Both of them have the latest version of Portworx cluster up and running.
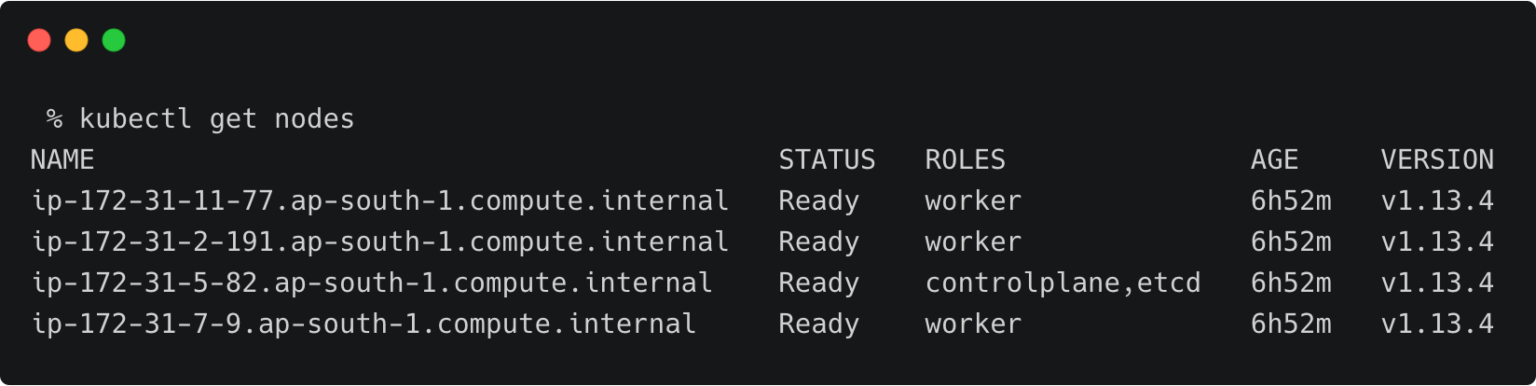
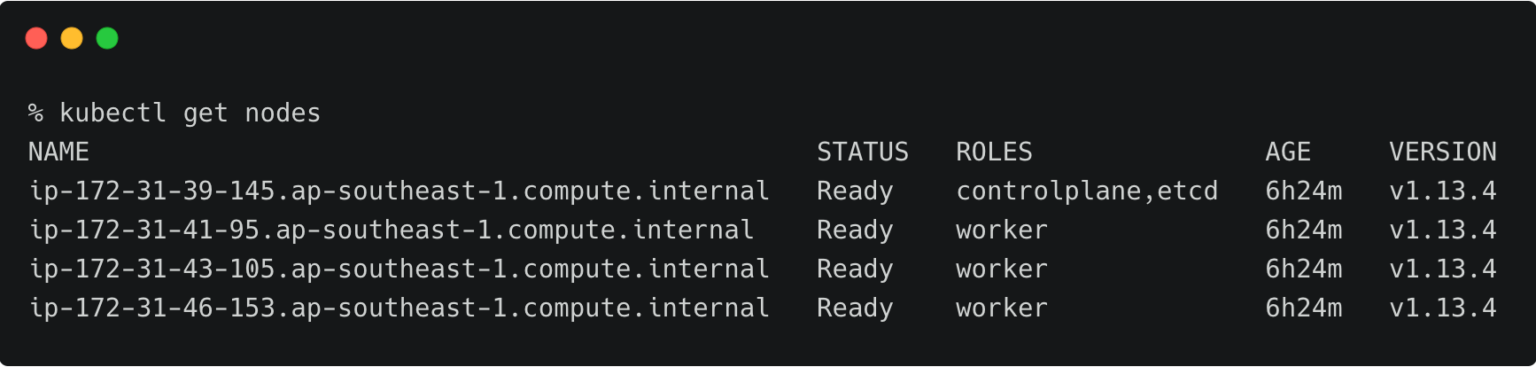
The above RKE cluster represents the development environment running in the Mumbai (ap-south-1) region of AWS.
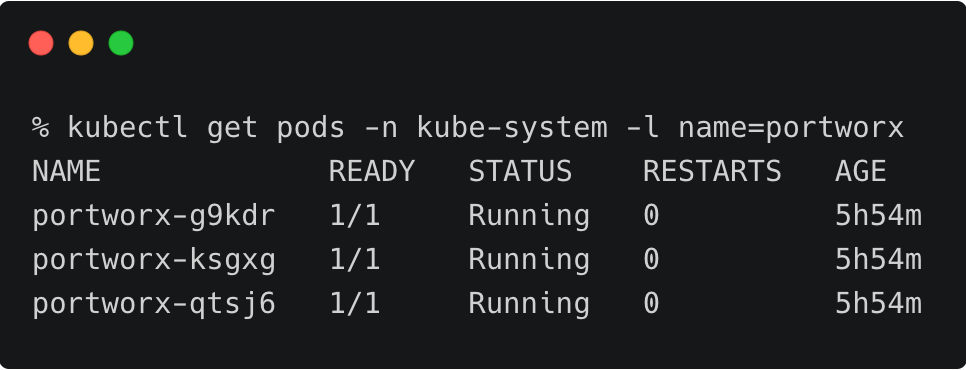
The above RKE cluster represents the development environment running in the Singapore (ap-southeast-1) region of AWS.
The dev/test environment currently runs a LAMP-based content management system that needs to be migrated to production.
Tip: To navigate between two kubeconfig contexts representing different clusters, use the kubectx tool and rename the contexts with dev and prod labels. You can merge the kubeconfig YAML files generated by RKE installer into one before using kubectx.
kubectx kubectx dev=. kubectx kubectx prod=.
It runs two deployments—MySQL and WordPress—in the cms namespace.
For a detailed tutorial on configuring a highly-available WordPress stack on Rancher Kubernetes Engine, please refer to this guide.
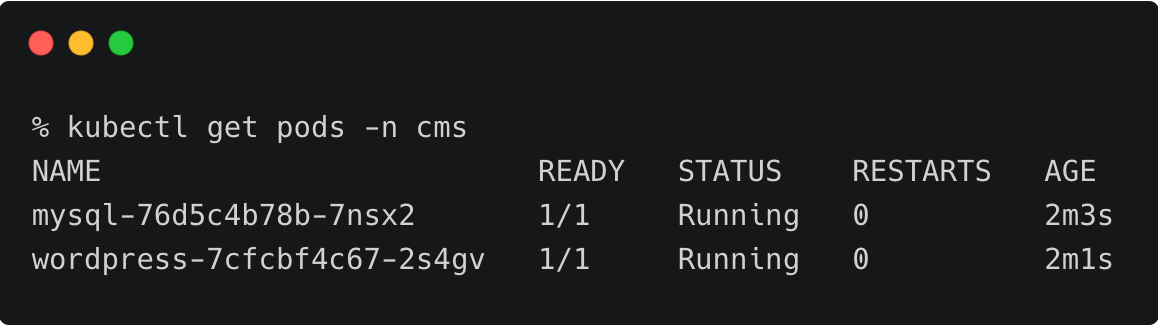
The persistent volumes attached to these pods are backed by a Portworx storage cluster.
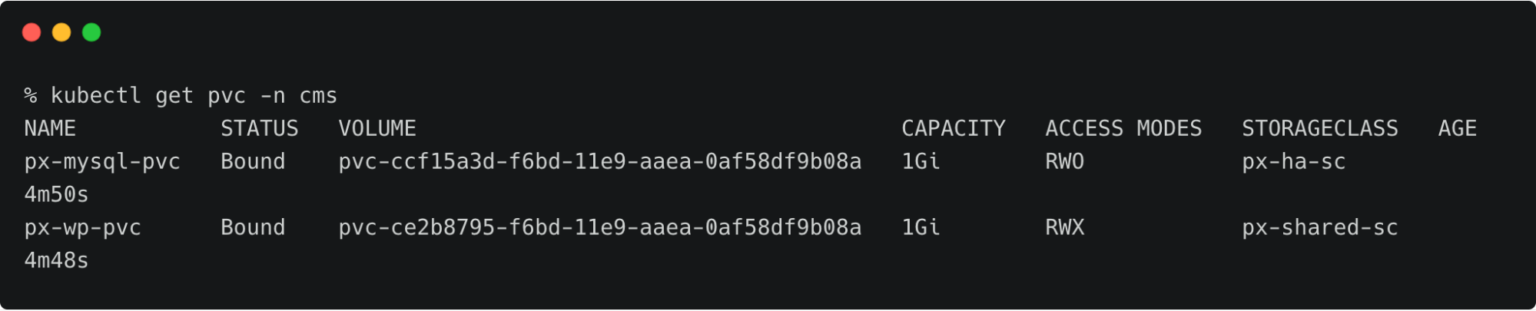
The below volume is attached to the MySQL pod.
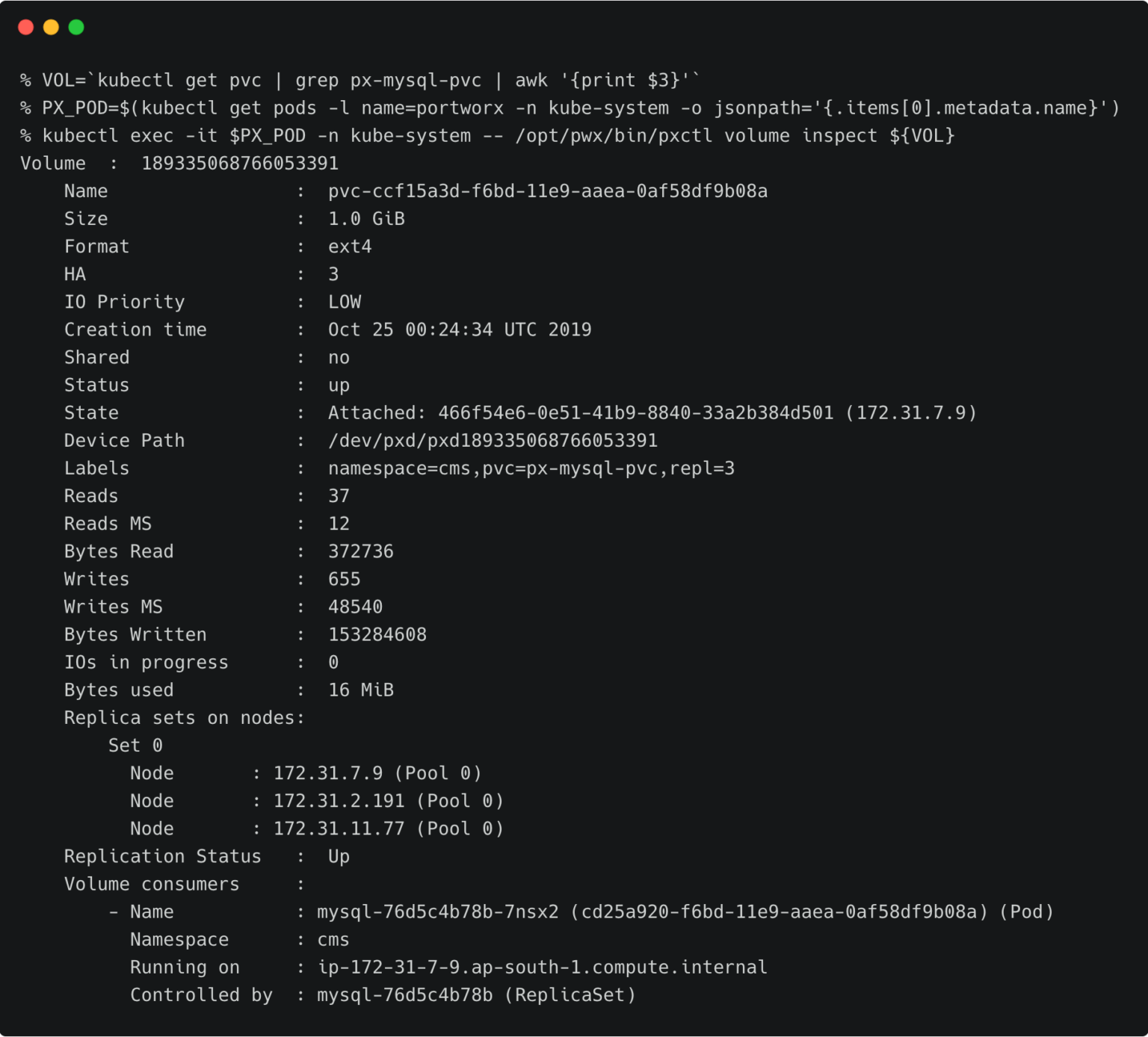
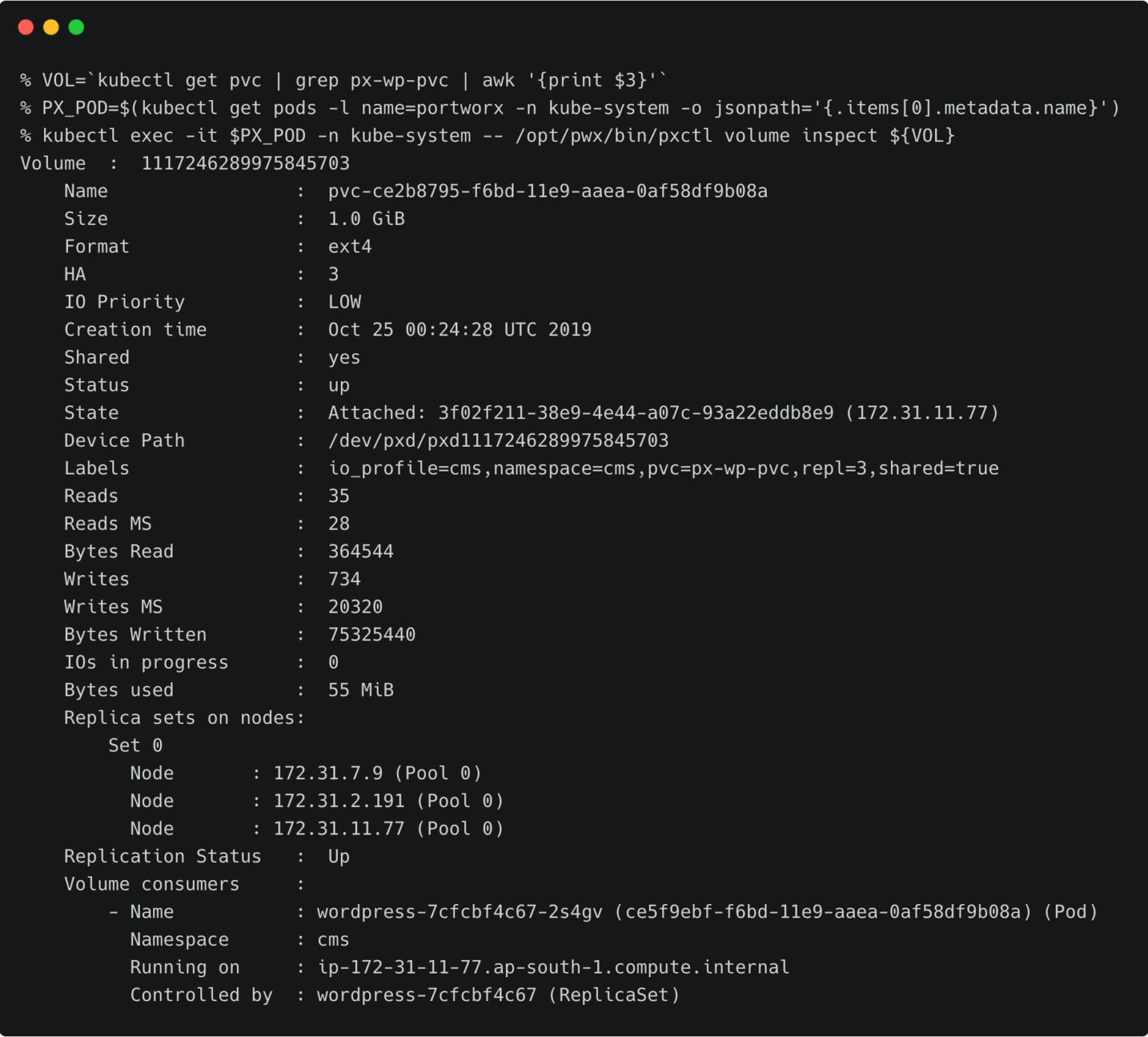
For the WordPress CMS, there is a shared Portworx volume attached to the pods.
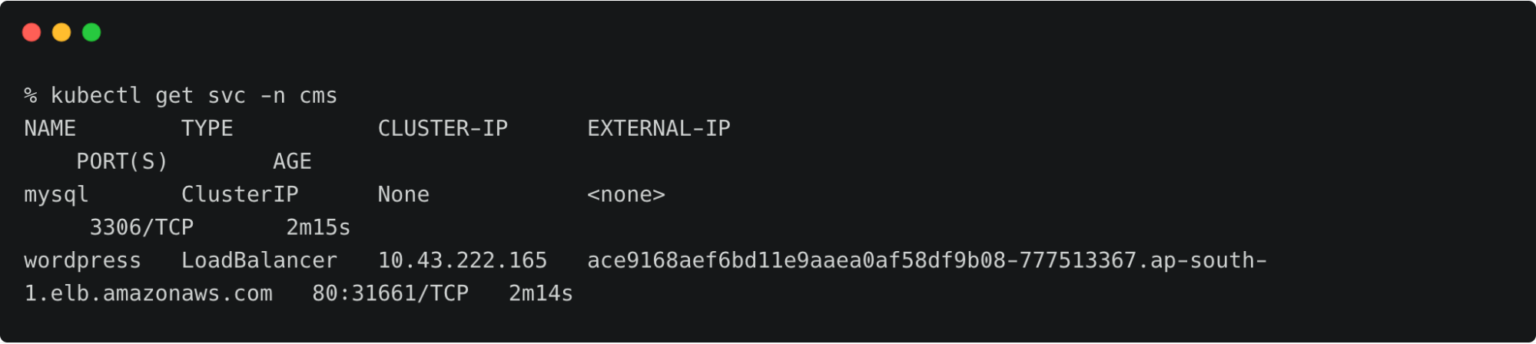
The fully configured application is accessed through the IP address of the load balancer.
Before we can migrate the resources, we need to configure the source and destination clusters.
Follow the below steps to prepare the environments.
We need to create the object store credentials on both source and destination clusters. In order to create this, we have to retrieve the UUID of the destination cluster, which will be appended to the name of the credential.
To complete this step, you need the access key and secret key of the AWS account. If you have configured the AWS CLI, you can find these values at ~/.aws/credentials.
Switch to prod cluster and run the below command to copy the UUID.
PX_POD=$(kubectl get pods -l name=portworx -n kube-system -o jsonpath='{.items[0].metadata.name}')
kubectl -n=kube-system exec $PX_POD -- /opt/pwx/bin/pxctl status
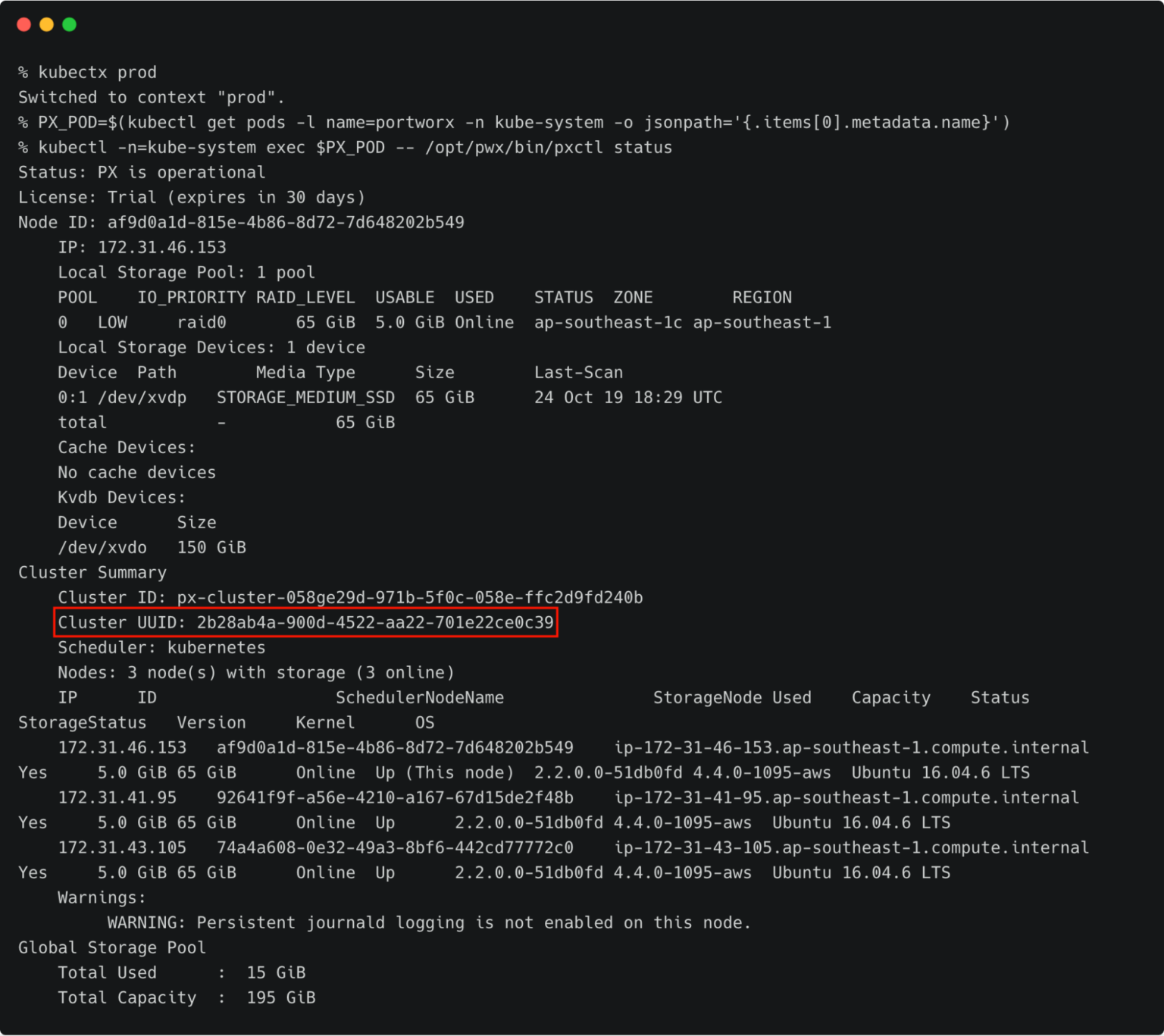
Make a note of the cluster UUID and keep it in a safe place.
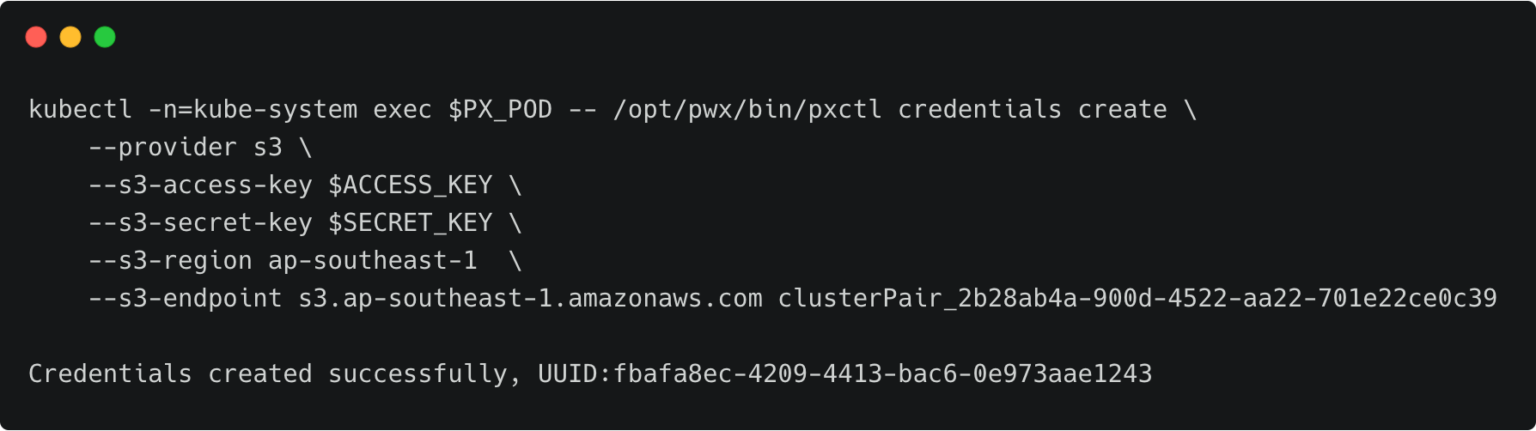
Let’s create the credentials on the production cluster while we are still using its context.
kubectl -n=kube-system exec $PX_POD -- /opt/pwx/bin/pxctl credentials create \ --provider s3 \ --s3-access-key \ --s3-secret-key \ --s3-region ap-southeast-1 \ --s3-endpoint s3.ap-southeast-1.amazonaws.com clusterPair_2b28ab4a-900d-4522-aa22-701e22ce0c39
Make sure that the credential name follows the convention of ‘clusterPair_UUID’.
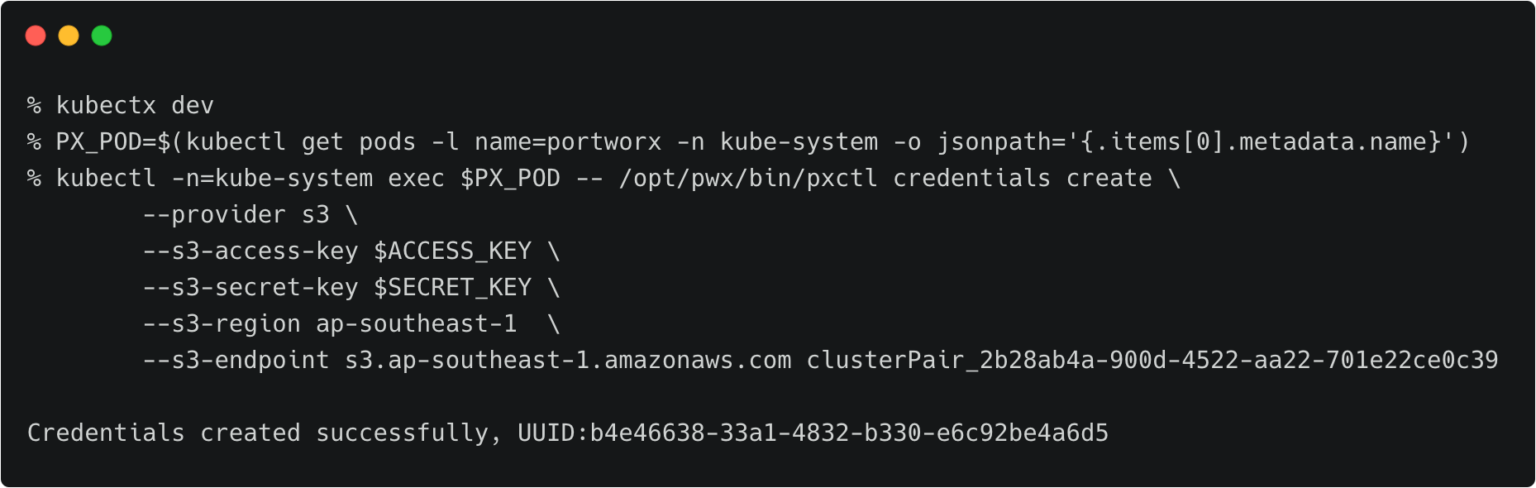
Switch to the development cluster and repeat the same steps to create the credentials for the source.
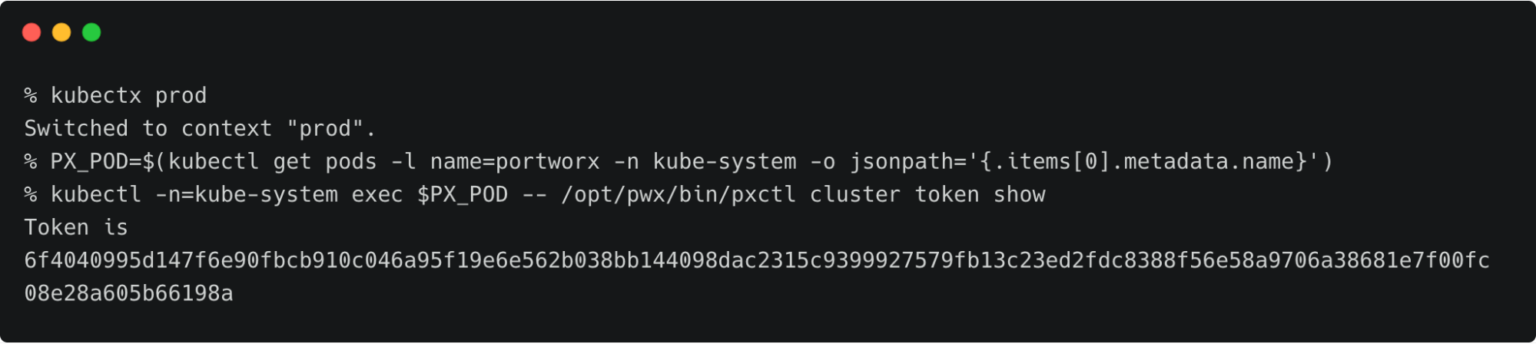
The next step is to retrieve the cluster token from the production cluster which is used to generate the YAML file with the cluster pair definition.
Let’s switch to the production cluster and run the command below to access the token.
kubectx prod
PX_POD=$(kubectl get pods -l name=portworx -n kube-system -o jsonpath='{.items[0].metadata.name}')
kubectl -n=kube-system exec $PX_POD -- /opt/pwx/bin/pxctl cluster token show
We also need the IP address and port for Portworx Service on the production cluster. We can retrieve that with the command below.
kubectx prod kubectl describe svc portworx-service -n kube-system
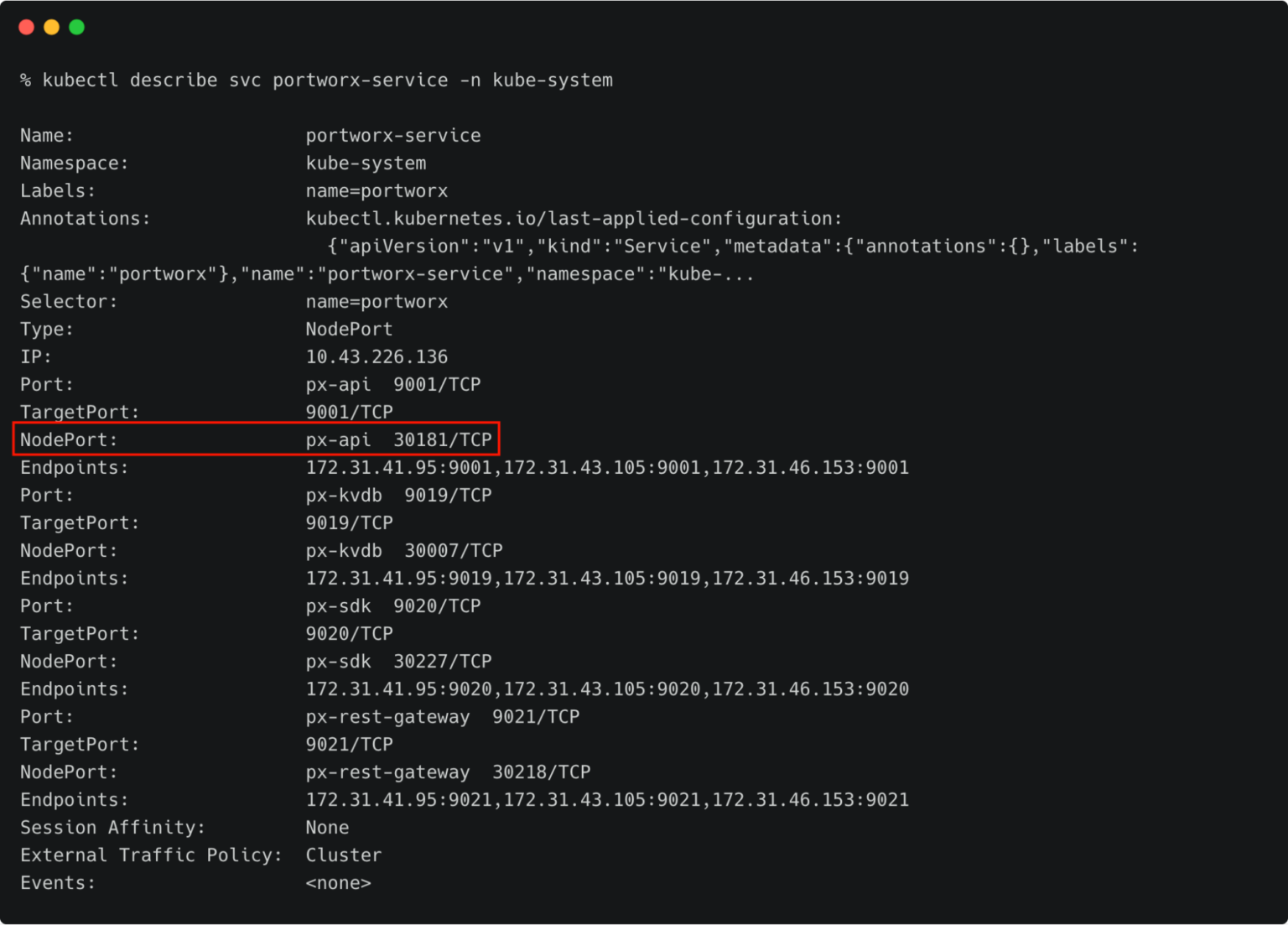
Make a note of the NodePort.
Retrieve the IP address of the first node of the destination cluster with the following command:
kubectx prod
kubectl get nodes -o jsonpath='{ $.items[0].status.addresses[?(@.type=="ExternalIP")].address }'

Before proceeding further, ensure that the EC2/VPC security group associated with the destination cluster has the NodePort open.
Open clusterpair.yaml and add the below details under options. They reflect the public IP address of one of the nodes in the destination cluster, port mapped to the NodePort, and the token associated with the destination cluster.

We are now ready to pair the clusters by applying the clusterpair specification to the source cluster.
Let’s switch to the source cluster (dev environment) to pair the clusters.
kubectx dev kubectl apply -f clusterpair.yaml kubectl get clusterpair -n cms
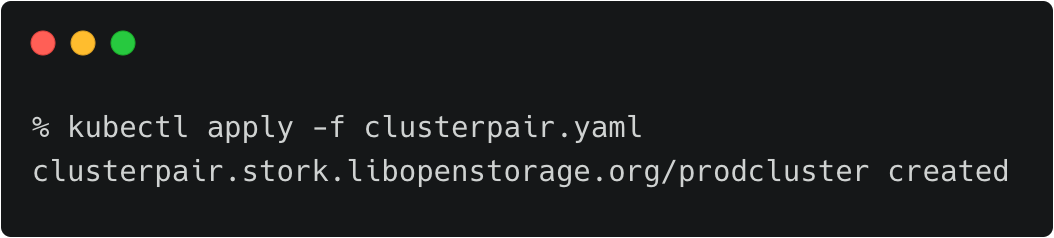
The output of <pre>kubectl get clusterpairs</pre> confirms that the pairing has been done.
We can verify the pairing status with the storkctl CLI. Ensure that both storage-status and scheduler-status are ready with no errors.
storkctl -n=cms get clusterpair
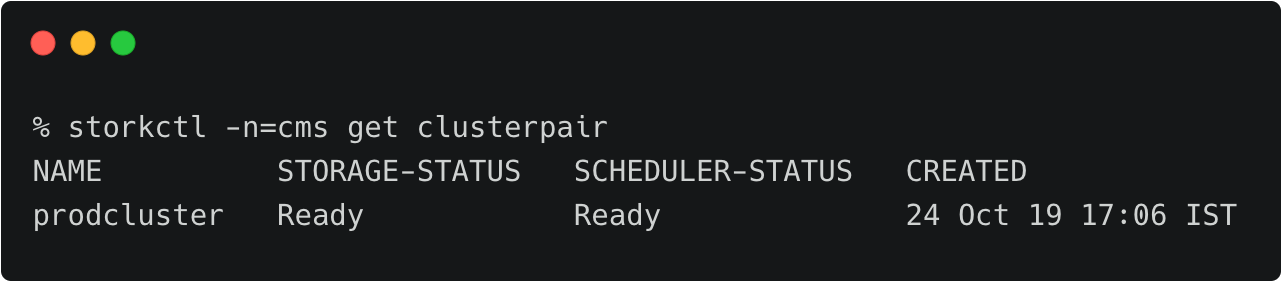
Congratulations! You have successfully paired the source and destination clusters.
We are now ready to start the migration.
Make sure that you are using the dev context, and follow the below steps to start the migration of the CMS application.
Create a YAML file called migration.yaml with the below content:
apiVersion: stork.libopenstorage.org/v1alpha1 kind: Migration metadata: name: cmsmigration namespace: cms spec: # This should be the name of the cluster pair created above clusterPair: prodcluster # If set to false this will migrate only the Portworx volumes. No PVCs, apps, etc will be migrated includeResources: true # If set to false, the deployments and stateful set replicas will be set to 0 on the destination. # There will be an annotation with "stork.openstorage.org/migrationReplicas" on the destinationto store the replica count from the source. startApplications: true # List of namespaces to migrate namespaces: - cms
This definition contains critical information, such as the name of the clusterpair, namespaces to be included in the migration, and the type of resources to be migrated.
kubectl apply -f migration.yaml migration.stork.libopenstorage.org/cmsmigration created
We can monitor the migration through storkctl.
storkctl get migration -n cms

Once the migration is complete, storkctl reports the final number of volumes and resources migrated to the destination cluster.

To get detailed information on the migration, run the command below:
kubectl describe migration cmsmigration -n=cms
Now we can switch the context to prod and check all the resources created within the cms namespace.
kubectx prod kubectl get all -n cms
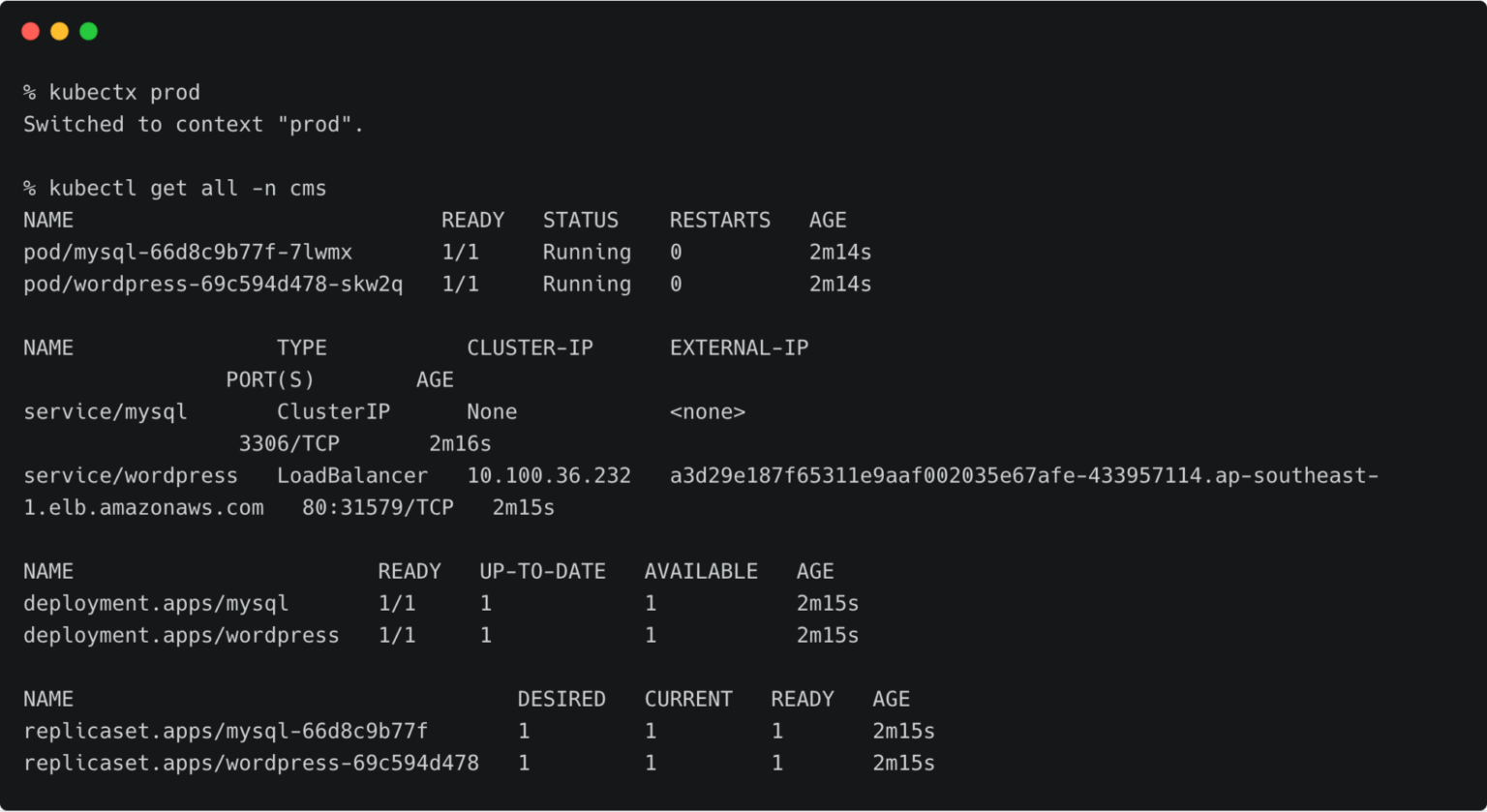
You can also access the application by visiting the CNAME of the load balancer of WordPress service.
Kubemotion extends the power of portability to stateful workloads. It can be used to seamlessly migrate volumes from on-premises to public cloud (hybrid) environments and cross-cloud platforms.


