This article looks at some ways enterprises are running stateful containers, along with their advantages as well as pitfalls. Picking the right container storage architecture is critical to a successful Docker, Kubernetes, or DC/OS deployment.
Any viable solution for stateful containers must solve five ubiquitous problems:
- Persistence: Native Docker doesn’t provide a persistence layer that enables a containerized database to survive host failure.
- High availability: If your container is rescheduled to a new host, its data does not move with it.
- Security: Enterprises moving to stateful containers must explore encryption and access controls.
- Scheduler-based automation: All of the above problems must be resolved via the scheduler of choice – be it Kubernetes, Mesosphere DC/OS, or Docker Swarm. DevOps teams can’t deal with yet another set of “out-of-band” provisioning tools for their data.
- Any database, any infrastructure: Finally, not only must enterprise teams solves persistence, security, and data automation for one database running in one environment, they must do it for many databases in many environments.
With this is mind, let’s look at various container storage architectures.
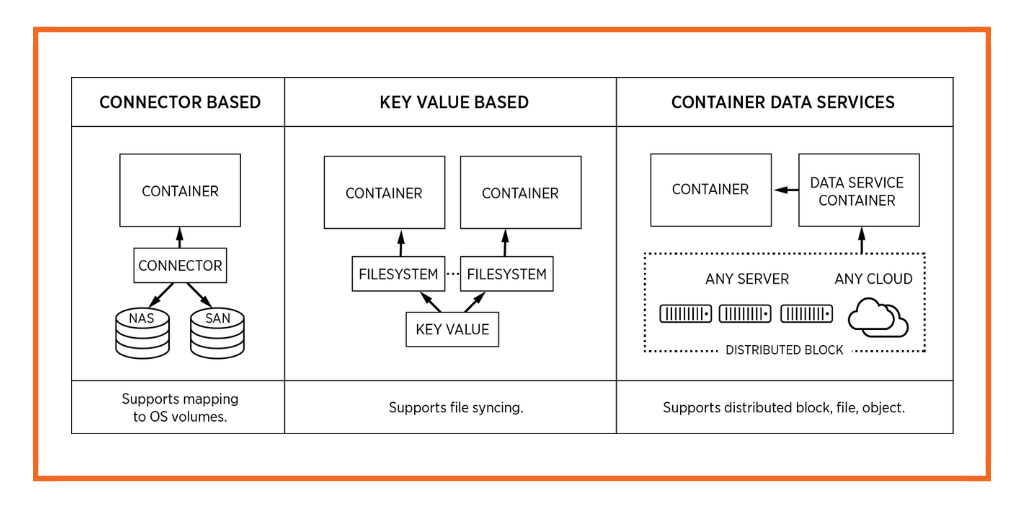
There are three types of stateful architectures emerging for distributed applications, and while they all leverage the Docker volume plug-in, they are quite different:
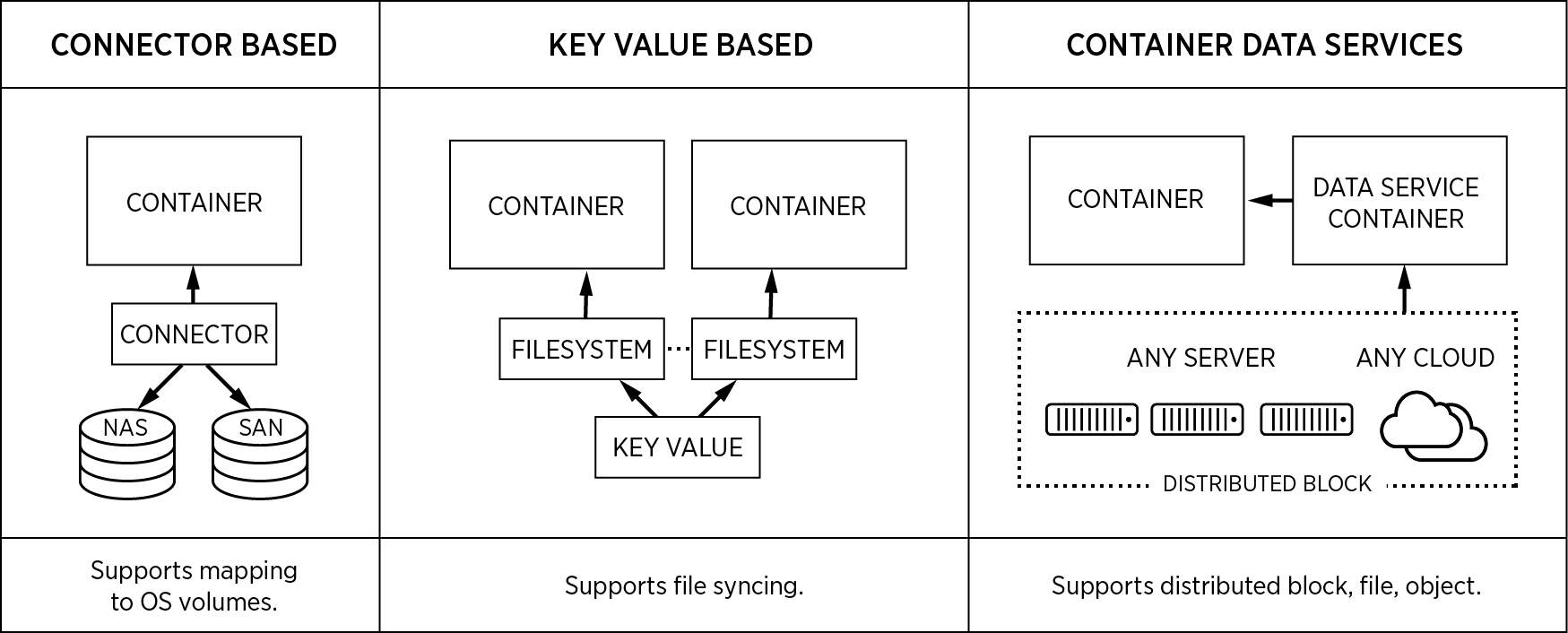
Connector-based systems
The most common type of volume management to have emerged are connector-based systems. Examples include Flocker from ClusterHQ, EMC RexRay and a growing number of native Docker storage drivers for storage systems like Amazon EBS. These volume plugins take physical or software-defined volumes and map them 1:1 into a container. They are called connector-based systems because they connect storage to containers, these connectors don’t provide the storage itself.
Advantages of connector-based systems:
- Allow you to use for current storage system for container storage
- Are generally free to use
- Relatively easy-setup
Connector-based systems also have some disadvantages, specifically related to the fact that they provide a persistence layer for containers by plugging into an existing storage solution. As a result, they pass through the storage characteristics of the underlying system to the containerized application. For example, the EBS Docker plugin makes it trivially easy to mount an EBS volume to a Docker container using Kubernetes, Mesos or Swarm. However, there can be a couple issues that emerge as a result. We will use AWS EBS as an example of these general, storage system related problems. You should look at your own storage system to see if these specific problems apply.
Low density of stateful containers per host
First, while you can run thousands of containers per host, you can mount a maximum of 40 EBS volumes per EC2 instance before risking boot failure. So while simple, the model of one EBS volume per container volume can severely limit the density of containers you can achieve per host. If reducing infrastructure costs or increasing density is a desired attribute of your application, a connector-based approach might not be a good fit.
Slow block device mounts
Secondly, the mount operation of a physical block device to a container host can be a slow operation, taking 45 seconds or longer, and frequently failing altogether, requiring a host reboot. As a result of the time it takes to unmount and remount a blocker device, failover operations, such as those supported by Kubernetes using Persistent Volume Claims, do not function well as a HA mechanism.
Plugins like RexRay, Flocker, EBS, ScaleIO all suffer from these storage-system related limitations. It is not that the plugin itself is faulty. They are just passing through the capabilities of the underlying storage.
Key-value based systems
These are filesystems like Torus, Facebook Haystack, or Infinit and are built on top of key value systems. This type of storage solution is good for file streaming and non-critical workloads bound by web access latencies, but is not suitable for transactional, low-latency, or data-consistency-dependant applications. Enterprise storage is an incredibly hard problem to solve, and this type of system cannot be used to implement scheduler-converged data placement, container-granular snapshots, tiering, low-latency access, and so on.
Container data services platform
These are cloud-native and container-granular data service solutions built on top of a enterprise-grade distributed block storage systems like Portworx. We have built our solution from the ground up for workloads like databases, queues, and filer applications — with cloud native architectures in mind. Our container storage solution is built with the founding principles of ease of use, devops-led programmability, and integration with any container scheduler. Its development team comes with serious storage chops. And data correctness, availability, integrity, and performance are at its core. It is storage for all container workloads and schedulers — supporting devops workflows to highly available replicated volumes across a large production cluster and across any cloud. We don’t automate and manage OS volumes or put data in a key value system. We store data just like a purpose-built distributed block storage system would.
These are three extremely different architectures and approaches to the same problem. Ultimately, your choice of the storage technology matters a lot and depends on your applications and usage — and if you are in production or development.
As you can see from Docker’s announcements in this area, all of us in the ecosystem are committed to empowering IT to address stateful containers. See how our customers are using Portworx in production today by trying out our developer edition.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Gou Rao
Portworx | Co-Founder and CTO
What 500+ Infrastructure Leaders Say About the Future of Kubernetes