Due to the popularity of this post, we’ve written a version focusing on failed attach and failed mount errors on Microsoft Azure. For more on how to resolve these errors on AWS, keep reading.
This blog is part of a new series on debugging Kubernetes in production. As the leader in running stateful services in production, Portworx has worked with customers running all kinds of apps in production and one of the most common errors we see from customers relates to
failed attachandfailed mountoperations on an AWS EBS volume. These errors results in being unable to mount volumes for pod becausevolume is already exclusively attached to one node and can’t be attached to another. This post will show you how to resolve Failed AttachVolume and FailedMount warnings in Kubernetes and how to avoid the issue in the future.How Portworx Solves Your Cloud Storage ProblemsBlock storage in the cloud is convenient and easy to provision. But it was designed to provide storage to VMs, not Containers. In highly dynamic Kubernetes environments, this leads to problems such as limited density of volumes per host, and … Read MoreBackground
As we described in our blog post about stuck EBS volumes and containers, using one EBS volume for each container creates a very fragile system. As we pointed out in that post, when we create 1-to-1 relationship between our EBS drives and containers, there are a variety of problems that can occur:
- The API call to AWS fails
- The EBS drive cannot be unmounted or detached from the old node
- The new node already has too many EBS drives attached
- The new node has run out of mountpoints
When there is a problem with this process, you will typically see errors like the following:

Warning FailedAttachVolume Pod 109 Multi-Attach error for volume "pvc-6096fcbf-abc1-11e7-940f-06c399d05922"
Volume is already exclusively attached to one node and can't be attached to another
Warning FailedMount Pod 1 AttachVolume.Attach failed for volume "pvc-6096fcbf-abc1-11e7-940f-06c399d05922" :
Error attaching EBS volume "vol-03ea2cb51f21f9fac" to instance "i-0e8e0bbf7d97a15df":
IncorrectState: vol-03ea2cb51f21f9fac is not 'available'.
status code: 400, request id: 41707341-e239-4808-846f-8f9d19fd1563
Specifically, there are errors for FailedAttachVolume and FailedMount, attach and mount being the two essential tasks for properly starting up a stateful container that uses an EBS volume.
This post will look in detail at why these errors occur, how to resolve the error at present and how to avoid the issue entirely in the future. At this point, though, we can summarise the issue as follows:
When something happens that requires a pod to rescheduled to a different node in the cluster, if the unmount and detach operations are not possible before the host becomes unavailable, you will not be able to attach it to a new host.
In our experience, 90% of EBS issues and Kubernetes come down to the this issue. You can’t startup a pod on some EC2 instance because its EBS volume is still attached to some other (potentially broken) host.
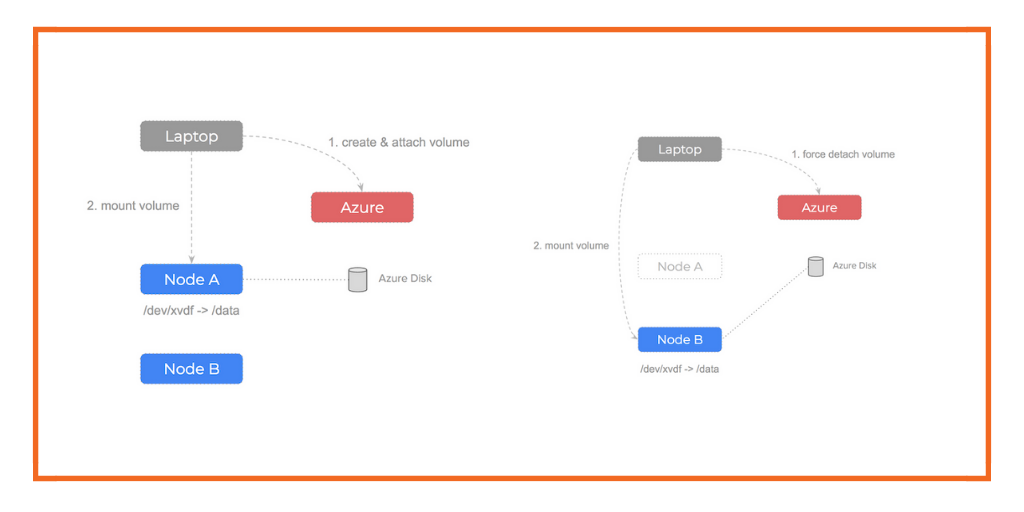
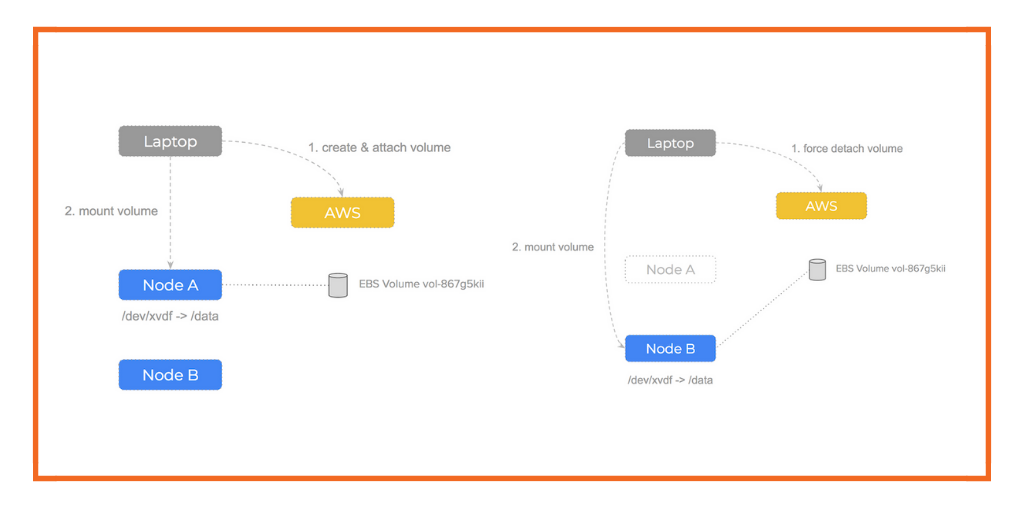
Manual Setup
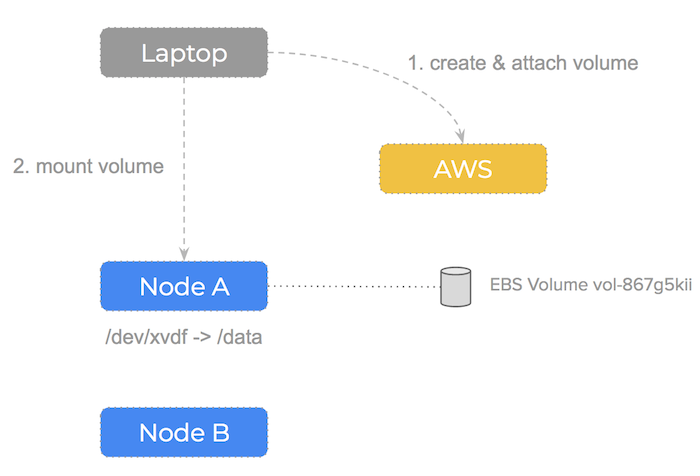
Let’s simulate the Kubernetes process by doing the operations manually.
First, we create an EBS volume using the aws cli:
$ aws ec2 create-volume --size 100
vol-867g5kii
This gives us a VolumeId and we have 3 EC2 instances we could use it on but before we can do that, we must attach the EBS volume to a specific node, otherwise it is unusable. We use the VolumeId and pick an instance from our pool and perform an attach operation:
$ aws ec2 attach-volume \
--device /dev/xvdf \
--instance-id instance-3434f8f78
--volume-id vol-867g5kii
Note that the attach-volume command can be run from any computer (even our laptop) – it’s only an AWS api call.
Now that AWS has attached the EBS volume to our node – it will be viewable on that node at /dev/xvdf (or whatever device path we gave in the attach-volume command).
The next step is to mount the EBS volume so we can start to write files to it, so we SSH onto the node:
$ ssh admin@instance-3434f8f78
$ sudo mkfs.ext3 /dev/xvdf
$ sudo mount /dev/xvdf /data
Note that the mount command must be run from the node itself.
We can then start writing files to /data. Because we have not used this volume before – we have formatted first the drive with an ext3 filesystem.
Manual Failover
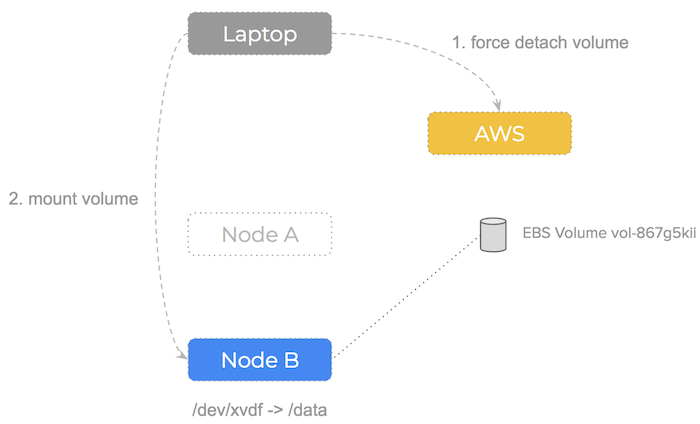
What if the node our EBS volume is attached to failed? Let’s walk through the steps we would need to do:
- Realise we cannot
unmountthe volume from a failed node - Force detach the volume using the aws api
$ aws ec2 detach-volume --force - Attach and mount the volume to a healthy node
Error Cases
Kubernetes automates a lot of this process – in a previous blog post we showed you how Kubernetes manages persistent storage for your cluster.
With that background out of the way, let’s look at some failures that can occur during daily operations.
Warning FailedAttachVolume
The Warning FailedAttachVolume error occurs when an EBS volume can’t be detached from an instance and thus cannot be attached to another. This happens because Kubernetes will not force detatch EBS volumes from nodes – the EBS volume has to be in the available state to be attached to a new node.
In other words – Warning FailedAttachVolume is usually a symptom of the underlying failure to unmount and detach the volume from the failed node.
You can see in the Kubernetes codebase that this error is generated when Kubernetes attempts to attach the volume to a node but it is already attached to an existing node.
Warning FailedMount
The FailedMount error comes in because since we were unable to attach a EBS volume to the new host, we are also, by definition, unable to mount that volume on the host.
You can see in the Kubernetes codebase one of the examples where this error is generated.
Common failure modes that cause EBS problems on Kubernetes
There are a number of scenarios that can cause these problems:
- Network partition
- Docker crashing
- Forced cordon / reschedule
- Failed EC2 node
Let’s take a look at these failure scenarios and see how Kubenetes using EBS copes with them.
NOTE: these errors are taken from Kubernetes version v1.7.4
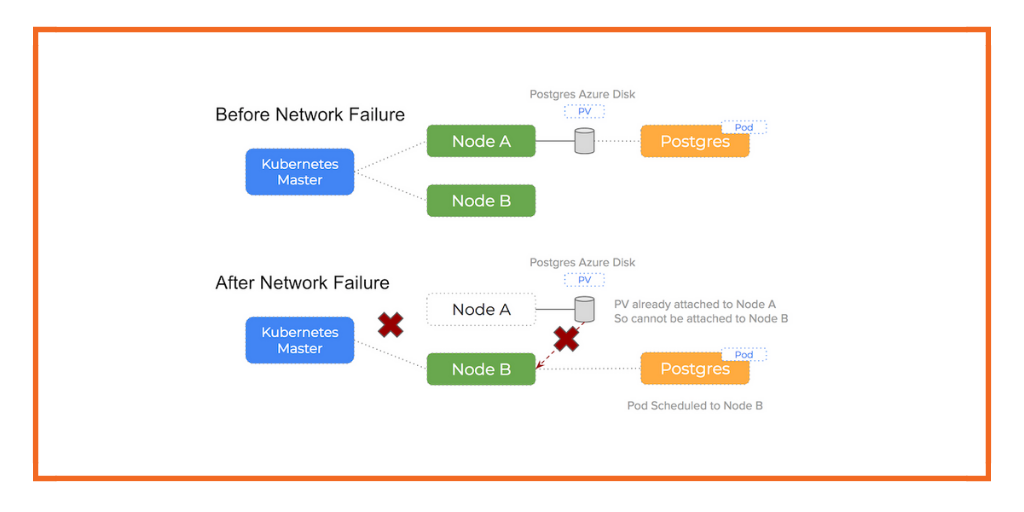
Network partition
Networks are one major component of a distributed system that can go wrong and lead to the log messages after failure: Warning FailedAttachVolume and Warning FailedMount.
We can simulate a network partition with an $ iptables -A DROP command on one of our nodes. When the network is killed, the kubelet is unable to communicate its status back to the Kubernetes master and is thus dropped from the cluster and all its pods are rescheduled to other hosts.
Once our stateful pod is scheduled to another node – the controller will attempt to attach the EBS volume to this new, healthy node. However, as we have discussed, AWS views the volume as currently attached to the old node and Kubernetes will not force detach. This will lead to the following warning events (using $ kubectl get events):
$ kubectl get ev -o wide
LASTSEEN FIRSTSEEN COUNT NAME KIND SUBOBJECT TYPE REASON SOURCE
0s 11s 105 mysql-app-397313424-9v0q6 Pod Warning FailedAttachVolume attachdetach
Multi-Attach error for volume "pvc-6096fcbf-abc1-11e7-940f-06c399d05922"
Volume is already exclusively attached to one node and can't be attached to another
2m 2m 1 mysql-app-397313424-pq8m2 Pod Warning FailedMount attachdetach
AttachVolume.Attach failed for volume "pvc-6096fcbf-abc1-11e7-940f-06c399d05922" :
Error attaching EBS volume "vol-03ea2cb51f21f9fac" to instance "i-0e8e0bbf7d97a15df":
IncorrectState: vol-03ea2cb51f21f9fac is not 'available'.
status code: 400, request id: 41707341-e239-4808-846f-8f9d19fd1563
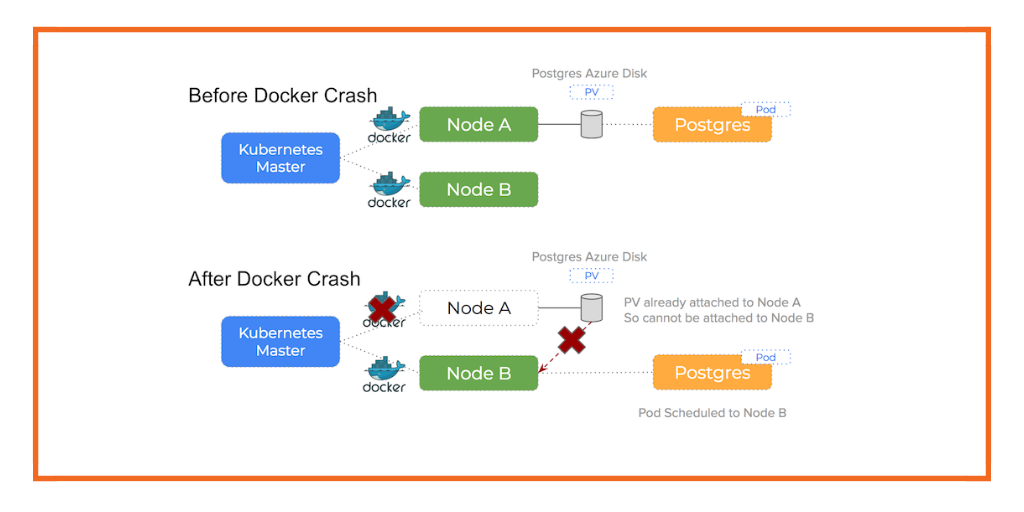
Docker daemon crash or stop
When the Docker daemon crashes or stops, the pods running on the host don’t stop, however, Kubernetes will nevertheless reschedule them to other hosts because the kubelet cannot report the status of those containers.
This can be tested by running $ sudo systemctl stop docker on one of the nodes.
This leads to a similar sequence of errors as a network partition:
$ kubectl get ev -o wide
LASTSEEN FIRSTSEEN COUNT NAME KIND SUBOBJECT TYPE REASON SOURCE
0s 8s 79 mysql-app-397313424-vtxk2 Pod Warning FailedAttachVolume attachdetach
Multi-Attach error for volume "pvc-6fb2d9ff-b991-11e7-8e89-060bb7549b64"
Volume is already exclusively attached to one node and can't be attached to another
2m 2m 1 mysql-app-397313424-8xk0h Pod Warning FailedMount attachdetach
AttachVolume.Attach failed for volume "pvc-6fb2d9ff-b991-11e7-8e89-060bb7549b64" :
Error attaching EBS volume "vol-07c7135dc55da5c5f" to instance "i-0a0f9a906e1a2b8eb":
IncorrectState: vol-07c7135dc55da5c5f is not 'available'.
status code: 400, request id: ae905421-2fe7-44ae-accc-20cb0acd1b81
Update affinity settings, forcing a reschedule & cordon
One of the most powerful features of Kubernetes is the ability assign pods to particular nodes. This is typically referred to as affinity. A simple way to implement affinity is with nodeSelector, basically a key-value pair label that describes a node.
$ kubectl label nodes kubernetes-foo-node-1.c.a-robinson.internal disktype=ssd
If you place a nodeSelector in your pod spec, Kubenetes will respect that label when making scheduling decisions. When this affinity setting is updated and your pods are rescheduled to nodes that fit the nodeSelector criteria.
This also applies to the cordon command – which makes use of node selectors to render a node un-usable by pods.
In both cases – by changing the values, Kubernetes will re-schedule the pod to another node.
Manually unpicking the stuck EBS problem
In our tests – Kubernetes version v1.7.4 suffers from the problems mentioned above. Because it is not able to force detach the volume, it gets stuck and so cannot be attached to the new node.
If your Kubernetes cluster has this problem – the key to resolving it is to force detach the volume using the AWS cli:
$ aws ec2 detach-volume --volume-id vol-867g5kii --force
This will move the volume into an available state which will enable Kubernetes to proceed with the attach operation for the newly scheduled node.
EC2 instance failure
In the case of a node failure, we have an interesting case to consider. We are simulating the node failure using $ aws ec2 delete-instances which means AWS does two things:
- power down and remove the ec2 instance
- mark any attached EBS volumes to be force detached
So – it’s important to note that in our tests whilst the node failure test worked – it was because the test itself does not capture what would happen with a true node failure:
- power cut
- kernel panic
- reboot
In the situations described above – neither Kubernetes or AWS can determine that the EBS volume should be forcably detached. It is always better to err on the side of caution after all, when it comes to production disks, force detach sounds scary!
Back to the instance failure test itself, because the node is lost, k8s will reschedule our pods to other nodes the same as above, but because we are simulating the node failure using $ aws ec2 delete-instances, AWS issues what is essentially a force detach.
This means the EBS volume becomes available – unlocking the controller code that is constantly checking the status of the volume to proceed and attach it to the new node:
$ kubectl get ev -o wide
COUNT NAME TYPE REASON SOURCE
1 p59jf Normal SuccessfulMountVolume kubelet, ip-172-20-52-46.eu-west-1.compute.internal
MountVolume.SetUp succeeded for volume "pvc-5cacd749-abce-11e7-8ce1-0614bbc11108"
7 p59jf Warning FailedMount attachdetach
AttachVolume.Attach failed for volume "pvc-5cacd749-abce-11e7-8ce1-0614bbc11108" : error finding instance ip-172-20-52-46.eu-west-1.compute.internal: instance not found
1 q0zt7 Normal Scheduled default-scheduler
Successfully assigned mysql-app-397313424-q0zt7 to ip-172-20-40-96.eu-west-1.compute.internal
1 q0zt7 Normal SuccessfulMountVolume kubelet, ip-172-20-40-96.eu-west-1.compute.internal
MountVolume.SetUp succeeded for volume "default-token-xwxx7"
What you can see here is:
- the volume mounting successfully to
172-20-52-46 - the call to AWS deleting the instance which triggers a detach asynchronously
- the volume controller failing repeatedly to confirm the attachment to
172-20-52-46 - the scheduler moving the pod to
172-20-40-96 - the volume mounting successfully to
172-20-40-96because AWS has detached it for us
This only works if you have a readiness probe for your pod so that the backend AWS api has a chance to update the state of the volume to available – this test failed when we removed the readiness probe (whereas Portworx passed).
Cloud native storage approach
There are some failure scenarios above that could possibly be mitigated by updating the Kubernetes EBS driver codebase, however the problem is one of fundamental architecture.
In reality, EBS disks are not agile entities that should be moved around the cluster. As well as FailedAttachVolume and FailedMount errors, the following spurious events could occur:
- The API call to AWS fails
- The EBS drive cannot be unmounted or detached from the old node
- The new node already has too many EBS drives attached
- The new node has run out of mountpoints
The real utility of EBS is that we can have failover without losing data. However, we are losing performance because EBS is network attached. AWS offers EC2 instances that have super fast SSD disks but we cannot use these in our failover scenario.
When you use Portworx as your Kubernetes storage driver when running on AWS, this problem is solved because:
once attached, an EBS volume stays attached and will never be moved to another node.
If a node fails – the EBS volume fails with it and should be deleted. This really embraces the immutable infrastructure aspect of a cloud native approach to a system.
The question remains – how can we ensure no data loss in the event of failover? The answer lies in the way Portworx takes an entirely different approach in consuming the underlying EBS drives and using synchronous block layer replication.
Decouple Storage from Containers
Portworx takes a different approach – it pools the underlying EBS drives into a storage fabric. This means containers get virtual slices of the underlying storage pool on demand. It is able to replicate data to multiple nodes and work alongside the Kubernetes scheduler to ensure containers and data converge efficiently.
With Portworx, EBS drives are created, attached, mounted and formatted once and then join the storage pool. Thousands of containers could be started using the same number of EBS drives because Portworx decouples the underlying storage from the container volumes.
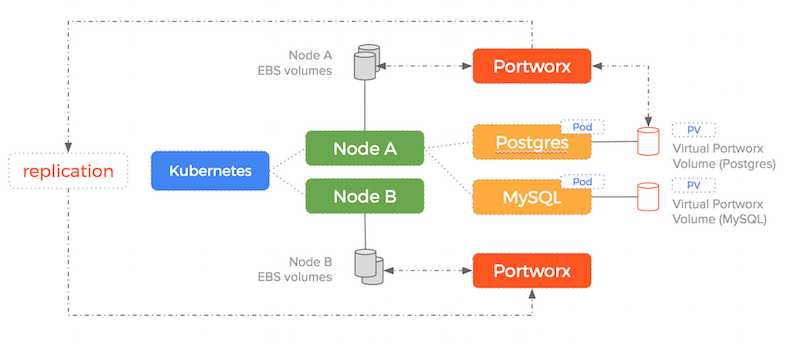
As you can see – Portworx consumes the underlying storage but decouples the actual drives from the volumes it presents to containers. Because the data is replicated and we are using shared volumes – the failover scenario we saw earlier becomes much simpler (and therefore less error-prone).
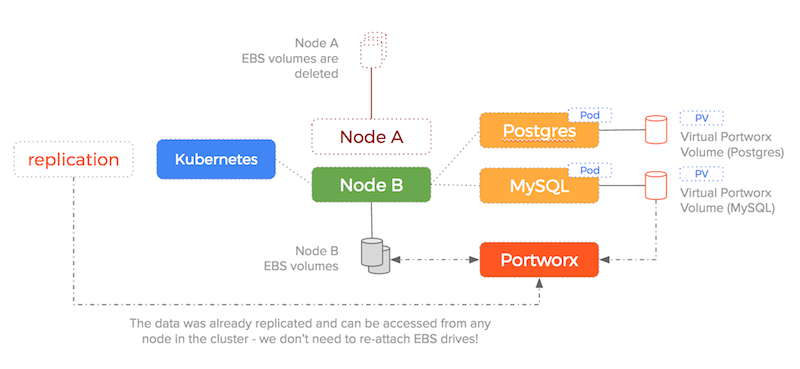
We are no longer enforcing a 1-to-1 relationship between EBS drives and containers and so the sequence of:
- detach block device from unresponsive old node
- attach the block device to the new node
- mount the block device to the new container
is no longer needed – the target EBS drive is already attached and already has the data!
Conclusion
We can see the advantage of using the Portworx storage layer to decouple our EBS drives from container volumes. We remove an error-prone and brittle process and get out of any stuck EBS problems we were having.
Think of Portworx like a gearbox sat between your underlying EBS drives and containers using volumes from that underlying storage pool.
Without that de-coupling mechanism, we are back to having a single EBS drive per container and if we are running a large number of stateful containers – increase the risk of encountering the dreaded volumes stuck in the “Attaching” State problem.
So in conclusion to resolve FailedAttachVolume and FailedMount errors:
- don’t have a one-to-one mapping of EBS volume per Docker container
- instead, mount EBS volumes onto EC2 instances and leave them there
- carve up that volume into multiple virtual volumes using software defined storage
- these volumes can be instantly mounted to your Kubernetes Pods and their containers
- and you will avoid the “Warning FailedAttachVolume” and “Warning FailedMount” errors that comes with Kubernetes and EBS
Hopefully, this post has given you some insight into the cause of the infamous Warning FailedAttachVolume and Warning FailedMount errors in Kubernetes.
Portworx has excellent support for running PersistentVolumes on Kubernetes and we have made our installation process pretty streamlined.
Head on over to our documentation and you can install it today or learn more about why we think Portworx is the best storage for Kubernetes!
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Kai Davenport
Kai has worked on internet-based systems since 1998 and currently spends his time using Kubernetes, Docker and other container tools and programming in Node.js and Go.