

Before deploying their production applications in Kubernetes, Portworx Enterprise users no longer need to manually provision object storage with a third-party service. As of the latest release of Portworx 2.12, scale-out object storage can be managed directly through the Kubernetes API. Scale-out object storage is an early access feature that adds to the already best-in-class block and file-based services provided by the Portworx storage cluster. The new scale-out object storage service will be compliant with the Kubernetes Container Object Storage Interface (COSI) when it becomes generally available.
In the Portworx Enterprise 2.12 release, we’ve introduced three new CustomResourceDefinitions (CRDs) to allow users to create and manage object storage buckets on Amazon S3 or Pure Storage FlashBlade arrays for use with their applications. Additional object storage solutions will be added in the future.
- PXBucketClass: A PXBucketClass is used to create PXBuckets, much like how a Kubernetes StorageClass is used to create PersistentVolumes. Just as a StorageClass describes the types of persistent volumes that can be created, a PXBucketClass describes what types of object storage buckets can be created.
- PXBucketClaim: Just as a PXBucketClass acts like a Kubernetes StorageClass, a PXBucketClaim acts like a Kubernetes PersistentVolumeClaim (PVC). PXBucketClaims specify a PXBucketClass to dynamically request an object storage bucket.
- PXBucketAccess: PXBucketAccess is a way to put access controls on the object storage created through PXBucketClaims.
By using these CRDs, customers can use their existing GitOps processes to manage dynamic object storage in both Amazon S3 or Pure FlashBlade arrays for their applications. Existing buckets already in use can also be imported to the cluster.
Create a Bucket Class
Once the Portworx Enterprise 2.12 storage cluster has been created and the early access features enabled, you can start creating your object buckets. To start, begin by creating a PXBucketClass. In this example, an Amazon S3 bucket class is being created that requires us to provide an Amazon region, a deletion policy, a backend-type parameter, and the S3 endpoint parameter, as shown in the manifest below.
apiVersion: object.portworx.io/v1alpha1 kind: PXBucketClass metadata: name: pbclass-s3 region: us-west-1 deletionPolicy: Delete parameters: object.portworx.io/backend-type: S3Driver object.portworx.io/endpoint: s3.us-west-1.amazonaws.com
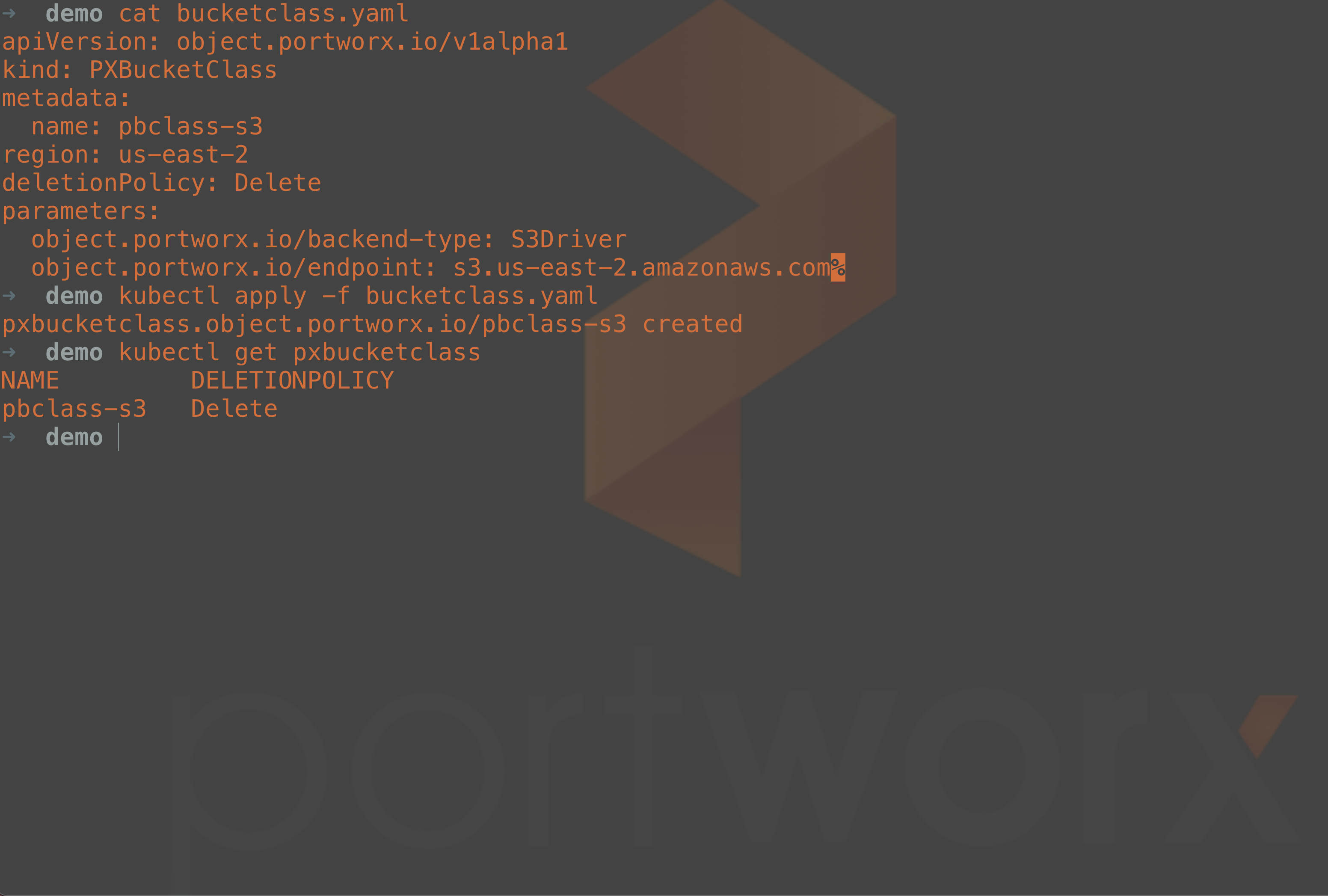
Note that with the example above, the deletionPolicy is set to “Delete,” meaning that when the PXBucket is deleted from the Kubernetes cluster, the Amazon S3 bucket will also be deleted.
Create a Bucket Claim
Once a Bucket Class has been created, we can use that class to request the creation of an object storage bucket. The PXBucketClaim is a request for an object storage bucket to be created based on the class it references. This is similar to how a Kubernetes PersistentVolumeClaim requests storage by referencing a Kubernetes StorageClass.
Refer to the PXBucketClaim manifest below. Here, we reference the PXBucketClass as part of the specification. We also provide a claim name and the desired namespace.
apiVersion: object.portworx.io/v1alpha1 kind: PXBucketClaim metadata: name: s3-pbc namespace: default spec: bucketClassName: pbclass-s3
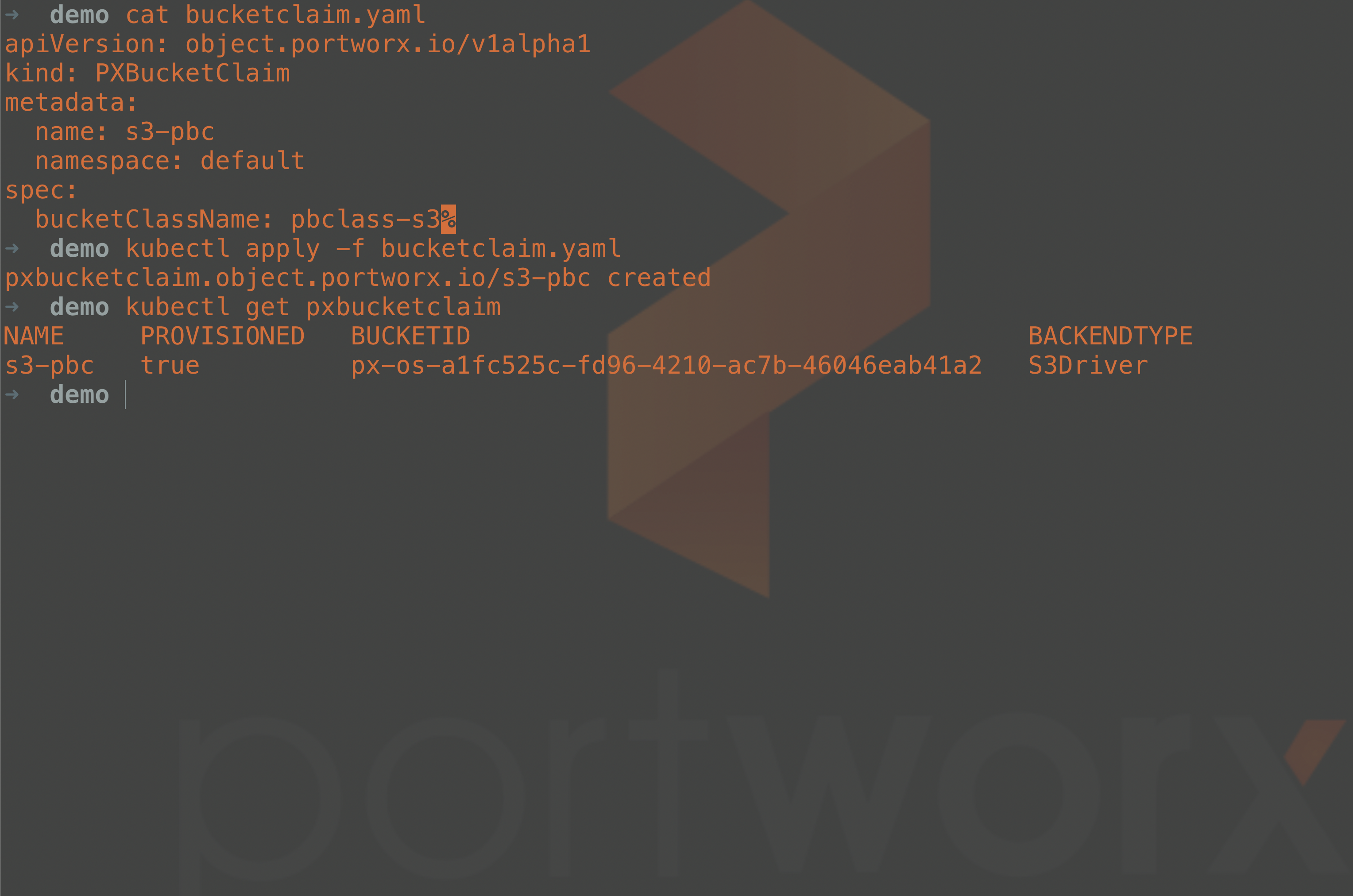
Once the PXBucketClaim has been created, our Amazon S3 bucket should be created. The Amazon S3 console displays this.
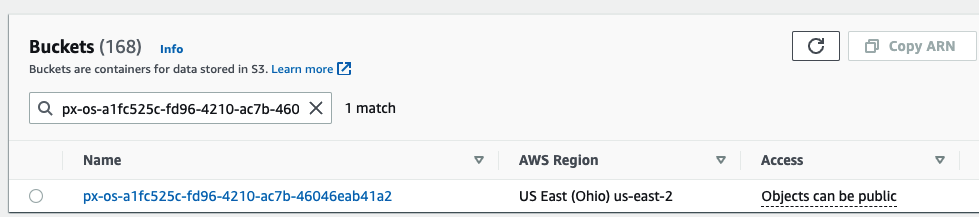
Currently, Portworx provides simple management of these object buckets, such as creation and deletion, but you can modify the properties of your object storage directly if you want—for example, if you want your S3 buckets to enable replication, encryption, etc.
Create Bucket Access
The object storage bucket has been created successfully, but we need a way to have our applications obtain bucket details such as the bucket name, access keys, the endpoint, etc. To manage this, we create another object called PXBucketAccess. As you can see from the PXBucketAccess manifest below, we specify the bucket class and the bucket claim. When this bucket access is created, a new Kubernetes secret will be created, which can be mounted by your applications requiring object storage. This secret will have all of the credential information, and it has important connection information about the dynamically created bucket, including the bucket name, access keys, and endpoints.
apiVersion: object.portworx.io/v1alpha1 kind: PXBucketAccess metadata: name: s3-pba namespace: default spec: bucketClassName: pbclass-s3 bucketClaimName: s3-pbc
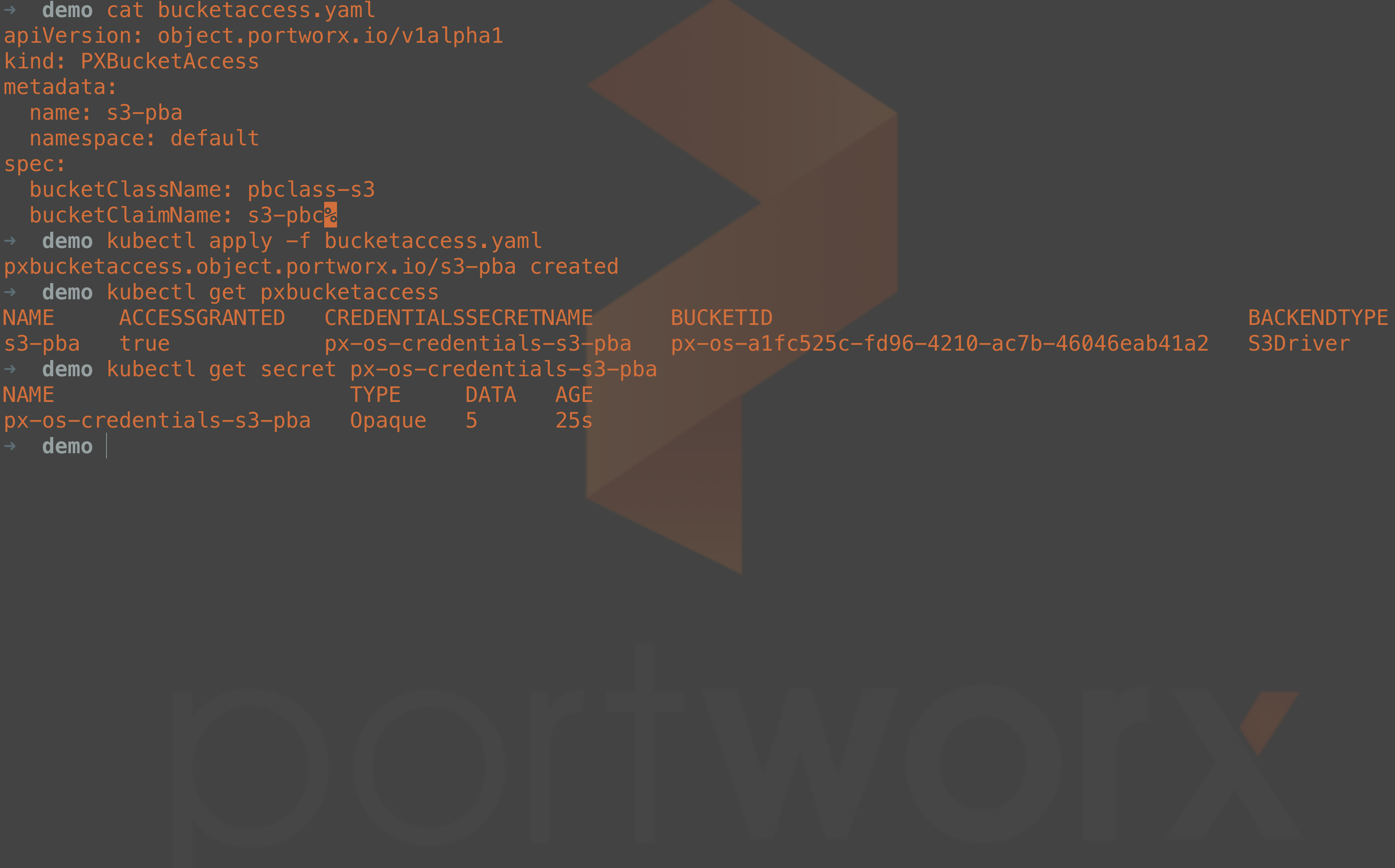
The secret will look similar to this example where the access information is stored in base64:
apiVersion: v1 data: access-key-id: OMITTED bucket-id: cHgtb3MtYTFmYzUyNWMtZmQ5Ni00MjEwLWFjN2ItNDYwNDZlYWI0MWEy endpoint: czMudXMtZWFzdC0yLmFtYXpvbmF3cy5jb20= region: dXMtZWFzdC0y secret-access-key: OMITTED kind: Secret metadata: name: px-os-credentials-s3-pba namespace: default type: Opaque
Use the Object Storage with Applications
Now that the bucket is created and our access credentials to use that bucket are stored in a Kubernetes secret, you can use environment variables for connection information in your applications. The example below would ensure that the S3_ACCESS_KEY, S3_SECRET_KEY, S3_BUCKET_NAME, S3_ENDPOINT, and S3_REGION can be referenced inside your containers. env: - name: S3_ACCESS_KEY valueFrom: secretKeyRef: name: px-os-credentials-s3-pba key: access-key-id - name: S3_SECRET_KEY valueFrom: secretKeyRef: name: px-os-credentials-s3-pba key: secret-access-key - name: S3_BUCKET_NAME valueFrom: secretKeyRef: name: px-os-credentials-s3-pba key: bucket-id - name: S3_ENDPOINT valueFrom: secretKeyRef: name: px-os-credentials-s3-pba key: endpoint - name: S3_REGION valueFrom: secretKeyRef: name: px-os-credentials-s3-pba key: region
Summary
Companies that are using object storage as a backing service for their applications no longer need to pre-provision their object storage buckets before app deployment. By using the new scale-out object storage services provided by Portworx Enterprise 2.12, now you can provision and access your object storage by interacting with the Kubernetes API. Portworx uses three new CustomResourceDefinitions to provision object storage buckets on Amazon S3 or Pure FlashBlade Arrays, making GitOps routines even easier. Additional S3-compliant object stores will be added in the future.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Eric Shanks
Principal Technical Marketing Manager | Cloud Native BU, Pure StorageExplore Related Content:
- gitops
- kubernetes
- kubernetes object storage
- object storage
- portworx
- s3


