Protect KubeVirt virtual machines using Portworx Backup

Breaking down silos is the best way to streamline operations and increase the level of productivity inside your organization. Silos lead to teams having competing agendas which contributes to reduced efficiency and increased costs to operate a business. With Kubernetes becoming more prevalent across different industries and verticals, organizations are choosing Kubernetes as their next datacenter or cloud operating system, which can help them run all of their applications in a consistent way. To realize this goal, organizations are now investigating and investing their time and effort into the open-source KubeVirt project and its enterprise alternatives like Red Hat OpenShift Virtualization. According to the 2023 State of Production Kubernetes report, 86% of the respondents want to unify containerized and virtual machine (VM) workloads on a single infrastructure platform. In this blog, we will talk about how Portworx Backup provides that unified solution to protect not just your containerized applications running on Kubernetes, but also virtual machines based applications that have been migrated over to Kubernetes. But, before we talk about Portworx Backup, let’s talk about what KubeVirt is and how it can help organizations run VMs on their bare-metal Kubernetes clusters.
KubeVirt Overview
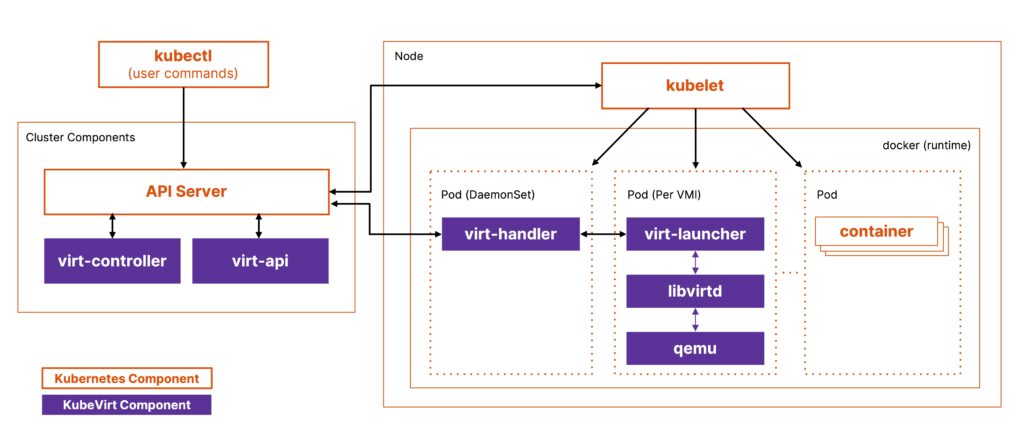
KubeVirt is a Cloud Native Computing Foundation (CNCF) incubating project that allows users to run VM objects on top of your Kubernetes clusters. These KubeVirt VMs are pods running a KVM instance on your Kubernetes clusters along with new Custom Resource Definitions (CRDs), Controllers and Agents that allow users to schedule and manage VMs using existing Kubernetes constructs. KubeVirt enables organizations to not worry about modernizing their VM-based applications and rearchitect or refactor them as containers to get the benefits of Kubernetes, but rather migrate their existing workloads into Kubernetes and still benefit from strategies like GitOps and DevSecOps.
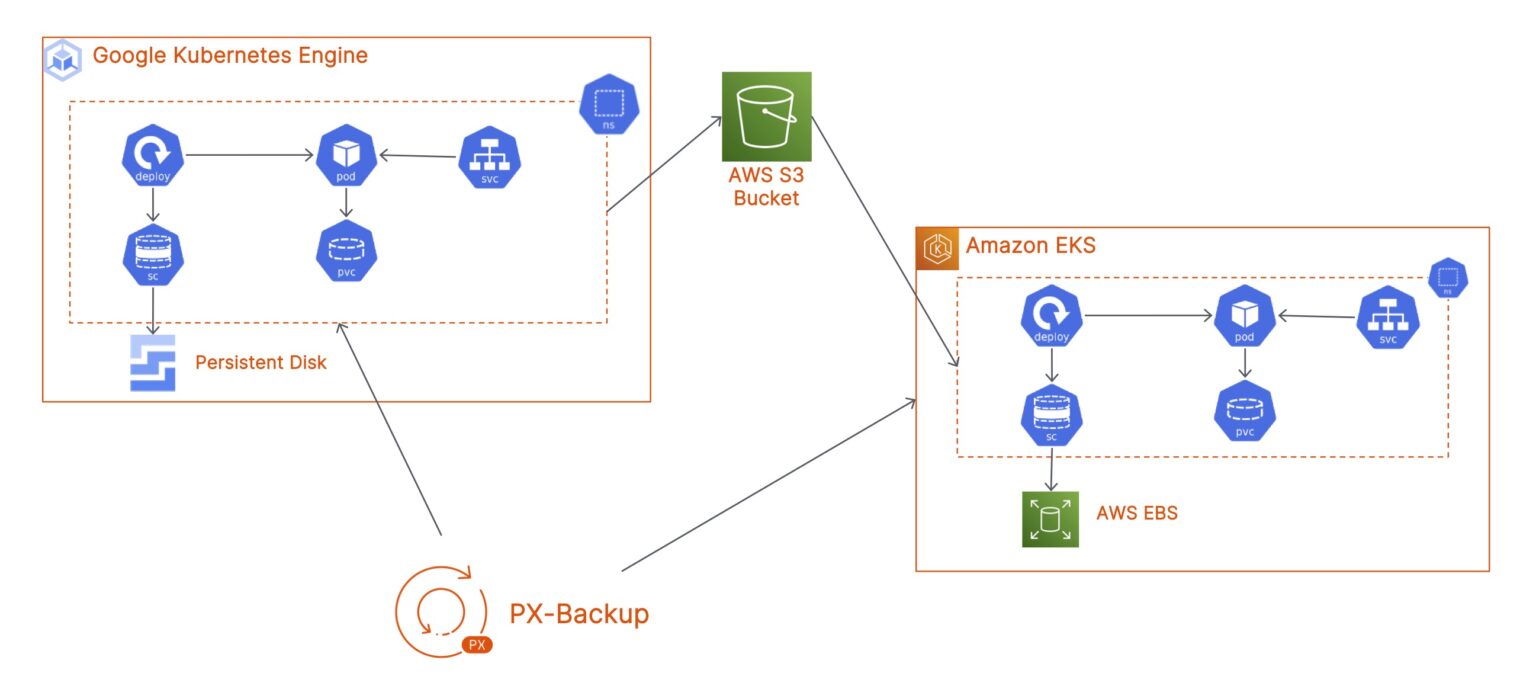
KubeVirt backup and restore
Now that we know what KubeVirt is, we need to talk about how we can protect our VMs running on Kubernetes. Although KubeVirt allows users to run VMs on top of Kubernetes, users still need to protect these VMs and ensure that they are backed up to meet organizational SLA requirements. Portworx Backup provides a Kubernetes-native backup and recovery solution that allows you to protect your VM object and all other Kubernetes resources a VM depends on, like Persistent Volume Claims, Secrets, ConfigMaps, Data Volumes, etc.
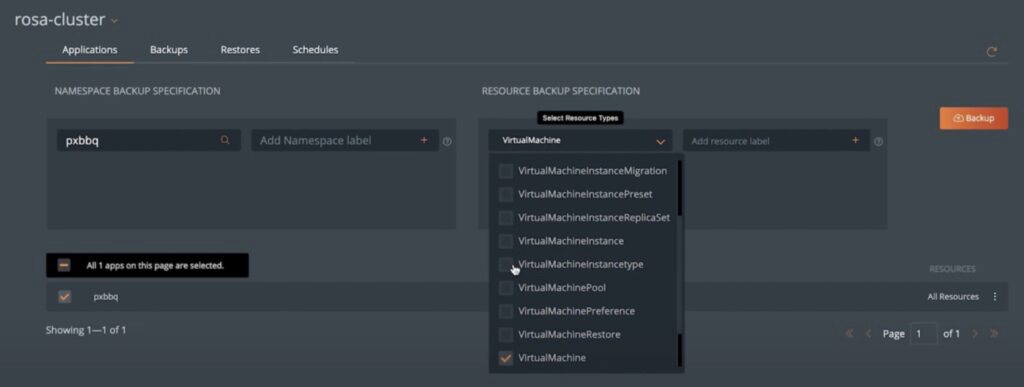
You can create backup jobs for individual VMs running on Kubernetes using labels or you can protect an entire namespace where you have multiple VMs running alongside other containers. Portworx Backup allows users to customize their backup jobs, based on namespaces, namespace labels, resource types or resource labels – giving them full ownership of how they protect their applications. Using namespace labels, platform engineers can also ensure that any future namespaces created by developers to deploy their VMs will automatically be protected as well – as long as the developers use the correct labels on their namespace definition.
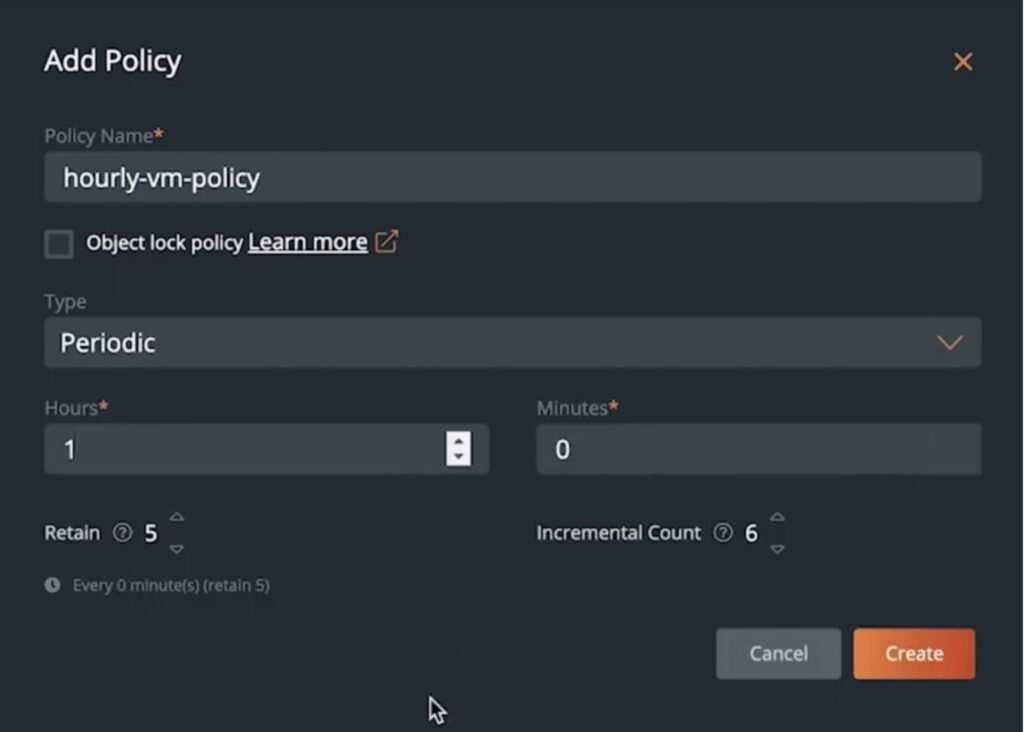
Portworx Backup allows users to either initiate a manual one-time backup of their virtual machines or it also allows them to use schedule policies to initiate regular backups for their applications. These schedule policies can either be created by the developers themselves – enabling self-service capabilities, or if the platform engineers or administrators want to create these policies to match SLA requirements, developers can just choose from a list of policies pre-created for them when creating that backup schedule.
Portworx Backup also allows users to create incremental backups, so they are not storing full copies of all of their data every time a backup job is triggered. The number of incremental backups before a full backup is taken can be controlled when creating a schedule policy.
Filesystem consistent KubeVirt backups
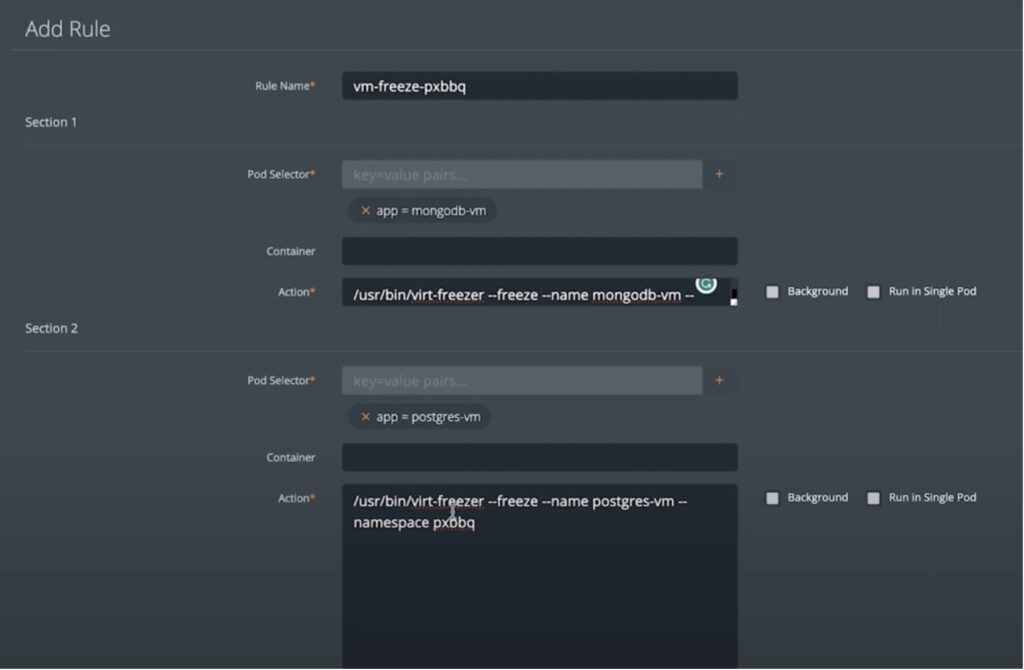
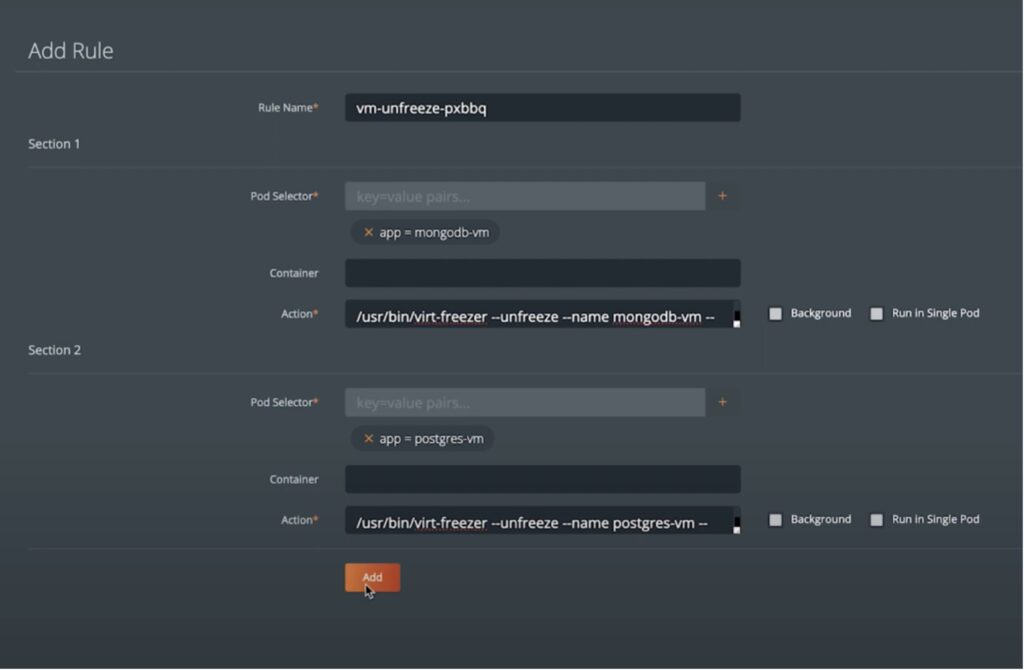
When protecting VMs running on Kubernetes, Portworx Backup allows users to quiesce the filesystem, before a backup job is executed, and then subsequently resume the I/O once the backup is complete. With Portworx Backup, users can use the pre- and post-backup rules to create file-system consistent backups for their VMs running on any Kubernetes cluster. To create these freeze and unfreeze rules, users can navigate to the Rules section from the dashboard and create new pre and post rules and share the correct resource labels and the commands to be executed as part of those pre- and post-job operations.
For VMs, Portworx Backup relies on the virt-freezer utility to create these freeze and unfreeze rules to ensure that VM backups are filesystem consistent.
Self-Service KubeVirt Backups and Restores
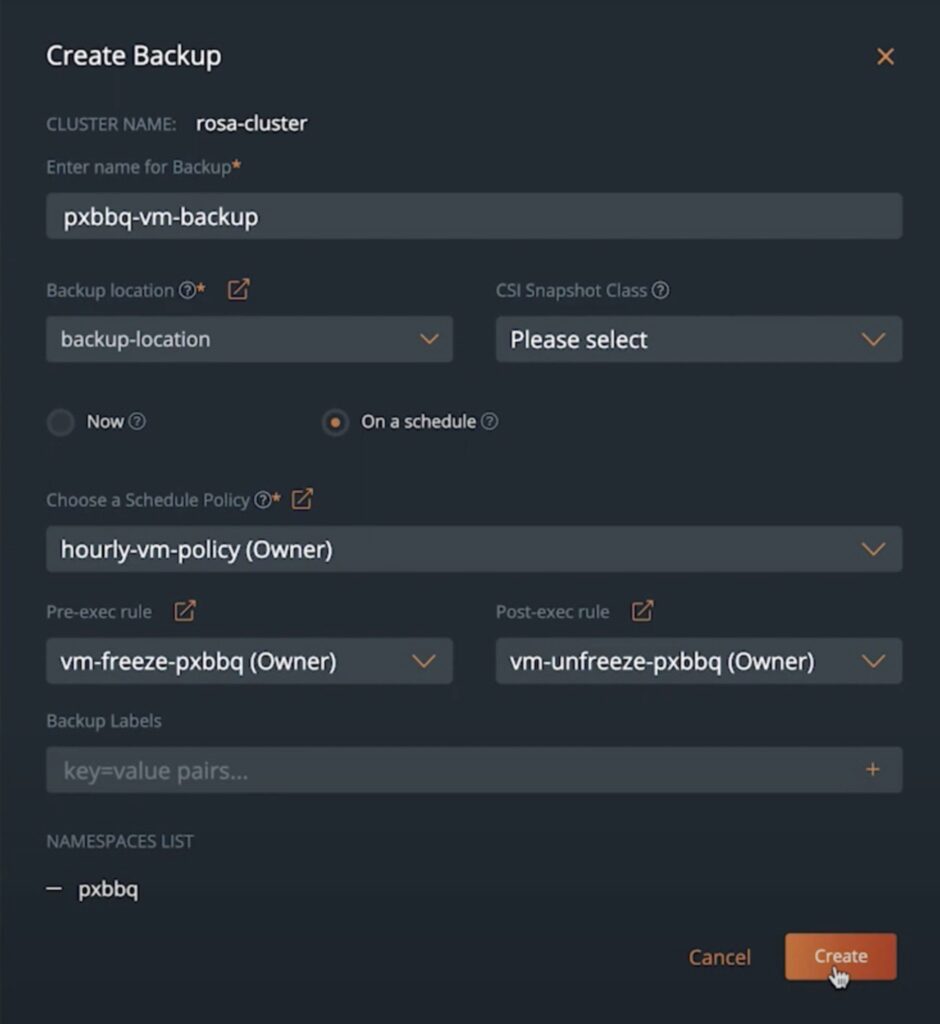
Once the administrator or platform engineer has created the pre- and post- backup rules and has created a schedule policy that can be used by individual application owners or developers, Portworx Backup enables easy self-service backups and restores of VMs running on Kubernetes. To create a new backup, the developer needs to select the Kubernetes cluster that their VMs are running on, and then select the namespace where their VMs are running, and hit Backup.
Next, they can give their backup job a name and select a backup target where they can store their backup snapshots. The backup target can either be an S3 bucket, an S3 object-lock enabled bucket for ransomware protection or an NFS share. They can then select the pre and post-backup rules and the schedule policy they want to use for their backups jobs. Once they hit Create – Portworx backup initiates the first backup and starts by first backing up the persistent volumes that belong to the VMs, and then protecting all the other Kubernetes objects that are part of that namespace.
Once the backup is complete, developers can use the Portworx Backup UI to monitor their current and previous backup jobs, and also look at additional details for each instance of the backup job.
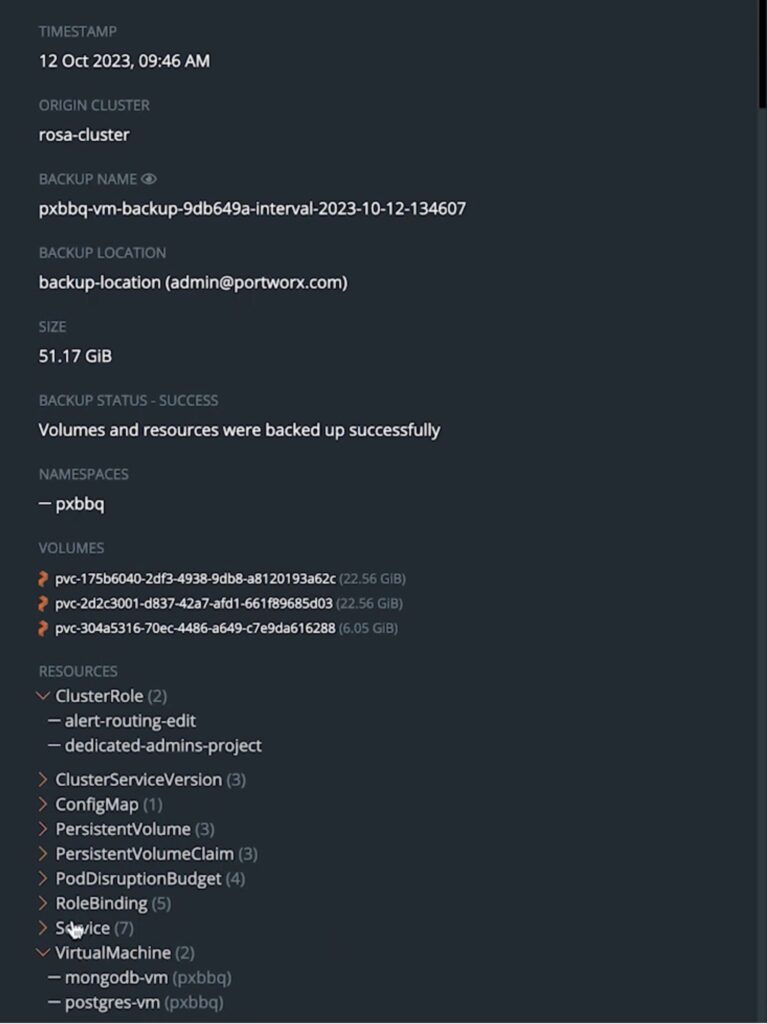
If the developers need to restore VMs from their backup snapshots due to any accidental deletion or data corruption issues, they can use the Portworx Backup UI to find the right snapshot they want to restore from, and then hit Restore. Developers can choose to restore a subset of Kubernetes objects or they can choose to restore everything that was included in the backup including Kubernetes services, ConfigMaps, PVCs, etc. Developers can either restore in the same namespace where their VMs were running or they can select a different namespace or a different cluster and a different namespace as well.
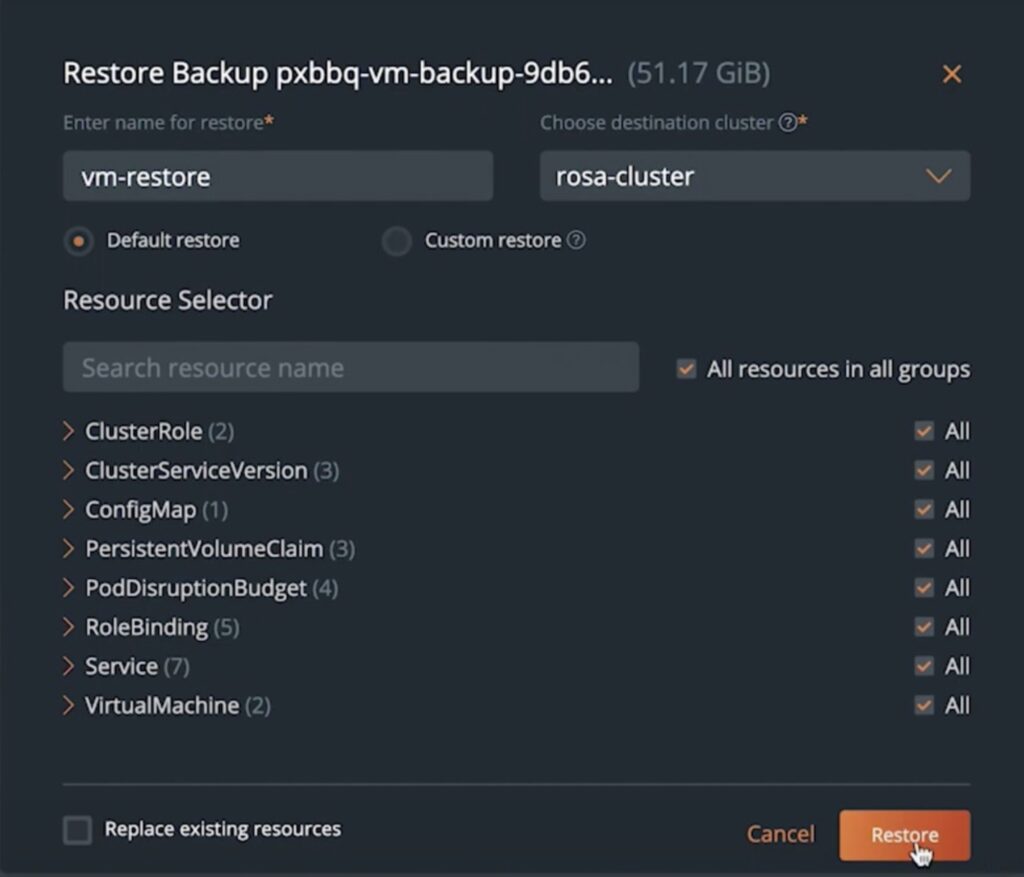
Portworx Backup allows users to migrate between different Kubernetes clusters and distributions, as long as you have KubeVirt installed and configured.
Conclusion
Portworx is the unified data platform that allows users to run virtual machines alongside containers using the KubeVirt project and with Portworx Backup, users now have a solution that can help them protect both containers and virtual machines running on their Kubernetes clusters.
We also recorded a quick demonstration of how Portworx Backup works for virtual machines running on Red Hat OpenShift clusters using OpenShift Virtualization and Portworx Enterprise. But, Portworx Backup can work with any CSI-compatible storage that supports virtual machine workloads.
If you want to try out Portworx Backup, feel free to start a free trial and deploy it on your own Kubernetes clusters.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Bhavin Shah
Sr. Technical Marketing ManagerExplore Related Content:
- KubeVirt
- Portworx Backup