

The Jupyter Notebook is an open-source web application that allows data scientists to create and share documents that contain live code, equations, visualizations, comments, and narrative text. It’s a powerful integrated development environment for data exploration, data processing, data analysis, machine learning, and analytics.
The JupyterHub is a multi-user platform that brings the power of Jupyter Notebook to enterprises. It’s a scalable, portable, customizable, and flexible environment to run Jupyter Notebooks in a multi-tenant model. JupyterHub can be deployed on bare metal servers, virtual machines, public cloud infrastructure, containers, and container orchestration engines. It can be deployed and managed in Kubernetes through Helm charts.
JupyterHub is a stateful workload that depends on a reliable persistence layer. When it is deployed in Kubernetes, JupyterHub needs a cloud native, scale-out data management layer.
Portworx is a cloud native storage platform to run persistent workloads deployed on a variety of orchestration engines, including Kubernetes. With Portworx, customers can manage the database of their choice on any infrastructure using any container scheduler. It provides a single data management layer for all stateful services, no matter where they run.
This guide is a continuation of the tutorial on deploying highly-available JupyterHub in Rancher Kubernetes Engine.
Uploading a Sample Dataset for the Notebook
Before attempting to perform a fail-over, let’s populate the environment with a sample dataset and a notebook.
Through the pod associated with user admin, we will upload a dataset to the shared storage location and verify its availability in user1’s environment.
Download the Pima Indian Diabetes dataset from Kaggle and save it as diabetes.csv.
We will copy it to the admin pod with the below command:
$ kubectl cp diabetes.csv jupyter-admin:/home/shared
Login as user1 and create a new terminal window.
As shown below, the dataset—diabetes.csv—is now available to user1 in the /home/shared directory.
We will now import a Jupyter Notebook into user1 environment. This contains Python code to explore and visualize the dataset copied in the previous step. Since the code in the Notebook has some dependencies, we need to install appropriate Python modules such as NumPy, Pandas, Matplotlib, and Seaborn.
Within the terminal window of user1, run the below commands to install the Python libraries.
$ pip install numpy pandas matplotlib seaborn
Upload the Jupyter Notebook and launch it. Since the Python modules are already installed, you can execute the code in the cells.
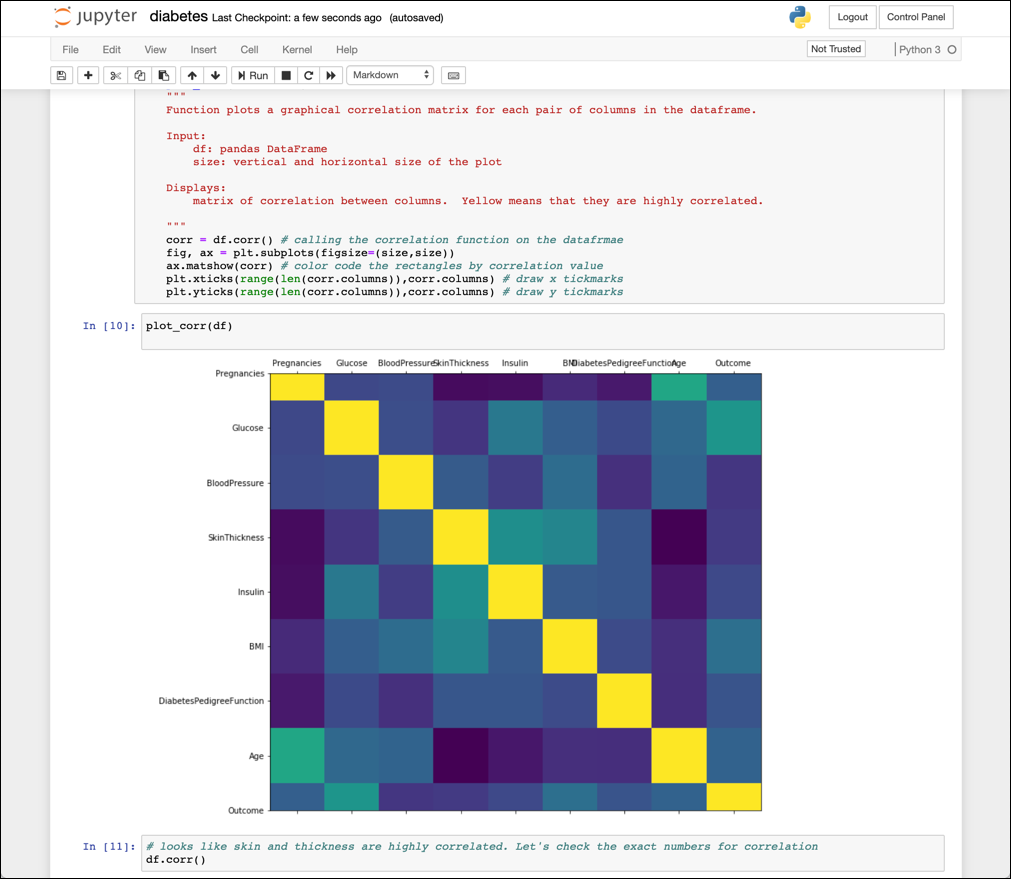
We can download the SQLite database used by JupyterHub to explore its contents.
$ HUB_POD=$(kubectl get pods -l component=hub -o jsonpath='{.items[0].metadata.name}')
$ kubectl cp $HUB_POD:/srv/jupyterhub/jupyterhub.sqlite .
Download the DB Browser for SQLite to open the JupyterHub database.
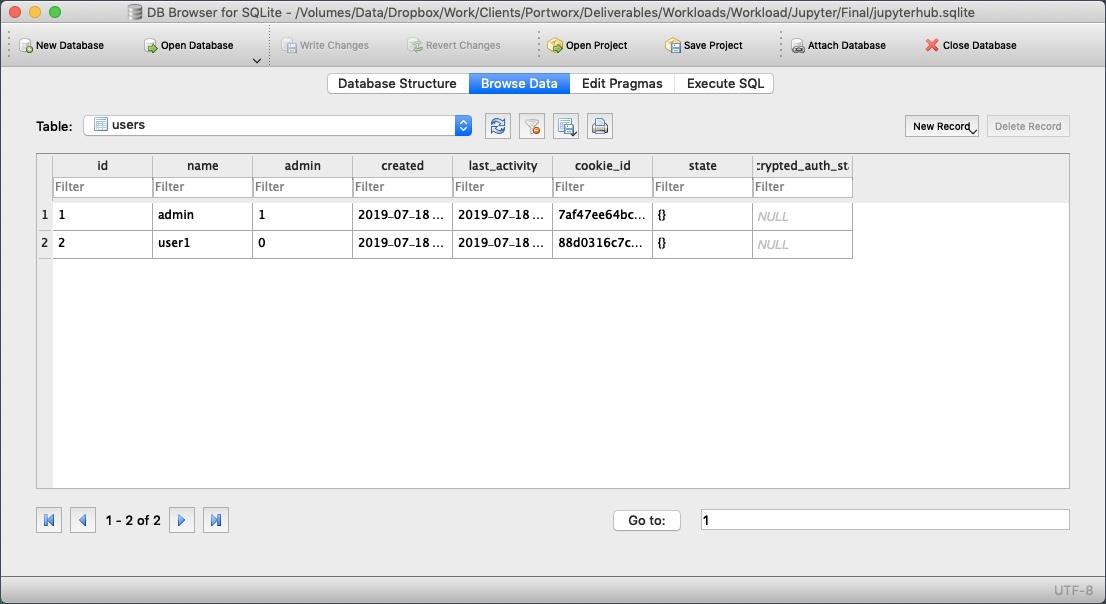
Browsing the user table shows that admin and user1 as registered users of JupyterHub.
Exploring Portworx Volumes
Since all the PVCs are based on the Portworx storage class, they are provisioned as Portworx volumes.
Let’s look at the volumes mapped to the PVCs.
PX_POD=$(kubectl get pods -l name=portworx -n kube-system -o jsonpath='{.items[0].metadata.name}')
kubectl exec -it $PX_POD -n kube-system -- /opt/pwx/bin/pxctl volume list
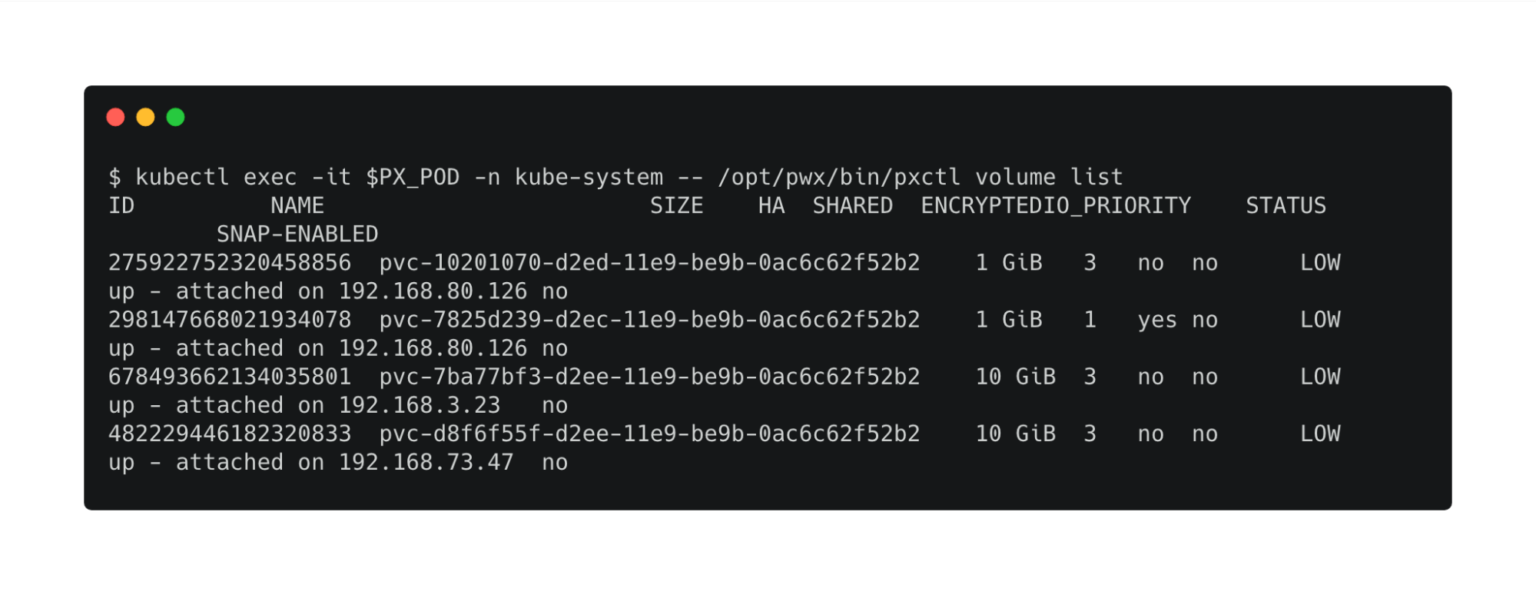
The first two volumes with size 10 GiB represent the user directories that were dynamically created by the hub. The third volume is used by the hub to persist the SQLite database file. We can identify it by the size and the replication factor, as mentioned in the storage class. The last volume is the shared volume available to all users.
We will first get the node that runs the hub pod.
$ NODE=`kubectl get pods -l component=hub -o wide | grep -v NAME | awk '{print $7}'`
echo $NODE
aks-nodepool1-12748671-1
The below command cordons it off by disabling pod scheduling.
$ kubectl cordon $NODE aks-nodepool1-12748671-1 cordoned

Let’s go ahead and delete the hub pod that’s still running on the cordoned node.
$ kubectl delete pod $HUB_POD pod "hub-599d577497-8bxh9" deleted
Performing Storage Operations on JupyterHub
After testing end-to-end failover of the hub, let’s perform StorageOps on our GKE cluster.
Currently, the Portworx shared volume that we created at the beginning is of 1Gib size. We will now expand it to double the storage capacity.
First, let’s get the name associated with the PVC of shared volume and inspect it through the pxctl tool.
$ VOL=`kubectl get pvc | grep px-jhub-shared-vol | awk '{print $3}'`
$ kubectl exec -it $PX_POD -n kube-system -- /opt/pwx/bin/pxctl volume inspect $VOL
Volume : 770078485852434339
Name : pvc-42248e71-d5f7-11e9-843e-c65ae588e837
Size : 1.0 GiB
Format : ext4
HA : 1
IO Priority : LOW
Creation time : Sep 13 07:22:35 UTC 2019
Shared : yes
Status : up
State : Attached: a9d37125-52ad-4bc5-adaf-01867e11b66d (10.240.0.5)
Device Path : /dev/pxd/pxd770078485852434339
Labels : io_profile=cms,namespace=default,pvc=px-jhub-shared-vol,repl=1,shared=true
Reads : 36
Reads MS : 8
Bytes Read : 372736
Writes : 54
Writes MS : 1296
Bytes Written : 16957440
IOs in progress : 0
Bytes used : 432 KiB
Replica sets on nodes:
Set 0
Node : 10.240.0.5 (Pool 0)
Replication Status : Up
Volume consumers :
- Name : jupyter-admin (a65476cc-d5ff-11e9-843e-c65ae588e837) (Pod)
Namespace : default
Running on : aks-nodepool1-12748671-0
- Name : jupyter-user1 (b79b52af-d600-11e9-843e-c65ae588e837) (Pod)
Namespace : default
Running on : aks-nodepool1-12748671-2
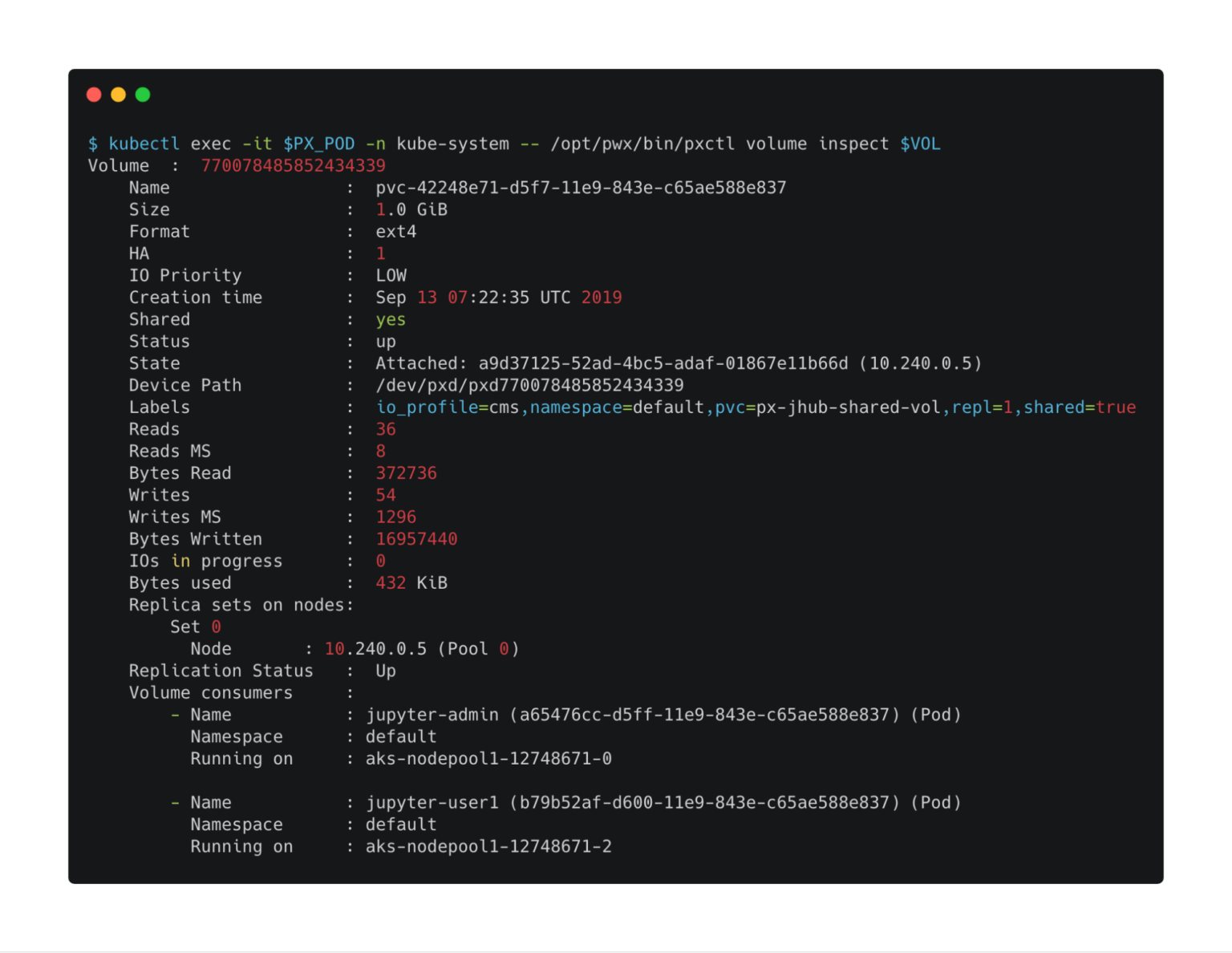
The output confirms that the shared flag is on for the volume and is being shared by two consumers—admin and user1.
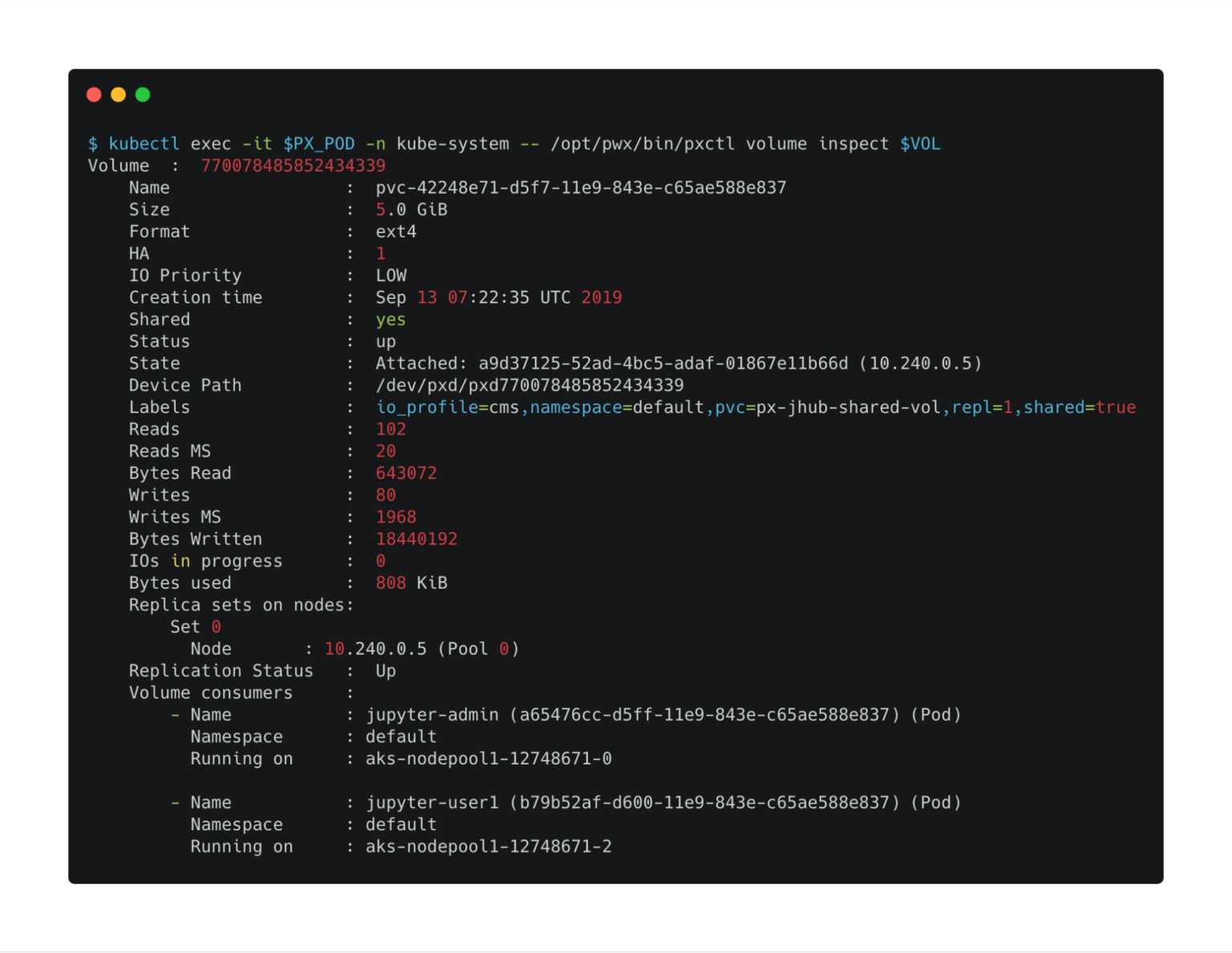
Now, let’s expand this to 5GiB to add more capacity to the shared volume. We can use the same pxctl tool to perform this operation.
$ kubectl exec -it $PX_POD -n kube-system -- /opt/pwx/bin/pxctl volume update $VOL --size=5 Update Volume: Volume update successful for volume pvc-42248e71-d5f7-11e9-843e-c65ae588e837
As a part of storage operations, it is possible to take point-in-time snapshots of volumes that can be restored as new PVCs. Through Kubemotion, the entire JupyterHub environment can be migrated to a new Kubernetes cluster along with the PVCs and configuration data. The PX-DR capability enables synchronous or asynchronous replication of volumes for disaster recovery and business continuity.
Summary
Portworx can be easily deployed on Azure Kubernetes Service to run stateful workloads in production. Through the integration of Portworx and AKS, DevOps and DataOps teams can seamlessly run highly available database clusters in Azure. They can perform traditional operations, such as volume expansion, snapshots, backup, and recovery for the cloud-native applications.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Janakiram MSV
Contributor | Certified Kubernetes Administrator (CKA) and Developer (CKAD)Explore Related Content:
- azure kubernetes service
- google kubernetes engine
- jupyter
- jupyterhub
- kubernetes



