

One of the challenges of operating Kubernetes in production is “complexity.” Increased complexity can have policy, security, and cost implications, which are detrimental to any IT organization. As an IT operator, you are always on the lookout for ways to reduce complexity, which, in turn, helps increase your operational efficiency and developer agility. One such solution that helps your organization increase developer productivity and operational efficiency is VMware Tanzu Data Services. Tanzu Data Services offers an operator-based method to deploy distributed data services on your Kubernetes clusters. These services can range from database solutions like VMware Tanzu SQL with Postgres and MySQL engines, to Messaging frameworks like VMware Tanzu RabbitMQ, to caching and data warehouse solutions like VMware Tanzu GemFire and VMware Tanzu Greenplum respectively. These solutions allow developers to quickly and efficiently deploy these data services needed to support their applications.
But, with great power comes great responsibility. Even though VMware Tanzu Data Services makes it easy for developers to deploy these data services, it adds complexity from an operational perspective. Although Tanzu Data Services can consume any underlying Kubernetes storage, that doesn’t mean that you will get a reliable and high-performing solution. Portworx understands the requirements that each Kubernetes stateful application has, and it has intelligence built into the platform to ensure that you get not only the best performant solution but also one that ensures the highest level of reliability. Portworx is the gold standard in Kubernetes storage, delivering the capabilities that enterprises require in terms of performance, reliability, and security. Let’s look at a couple of these features in detail and see how Portworx can augment VMware Tanzu Data Services to deliver the best-in-class capabilities for operators and developers in your organization.
Replication and High Availability
Each Kubernetes stateful application has different requirements when it comes to replication and high availability. Depending on the service-level agreements (SLAs) defined for each application, the operator needs to ensure that the underlying infrastructure is providing the level of high availability and replication necessary to guarantee application uptime and meet those SLAs. Portworx understands that each application is different and so are its requirements. Portworx Kubernetes storage provides operators the ability to define application-specific Kubernetes StorageClass and use those to enforce HA policies while using a consistent Kubernetes storage layer for all of your applications. You can create individual storage classes for VMware Tanzu Data Services, ensuring that any data that is written by the application is stored reliably and can tolerate common failures like pod restarts, node restarts, node failures, etc.
Here are a couple of storage classes that you can leverage for your Tanzu Data Services:
- VMware Tanzu RabbitMQ
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: portworx-tanzu-rabbitmq parameters: io_priority: high repl: "2" group: "rmq_vg" provisioner: kubernetes.io/portworx-volume allowVolumeExpansion: true reclaimPolicy: Delete
- VMware Tanzu SQL – PostgreSQL
kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: portworx-tanzu-postgres provisioner: kubernetes.io/portworx-volume allowVolumeExpansion: true parameters: repl: "2" priority_io: “high” io_profile: “db_remote”
By leveraging different storage classes for each Tanzu Data Service, operators can enforce different levels of replication needed to meet pre-defined SLAs.
Application Performance
Operators can also leverage different Portworx storage class definitions to ensure that the IO from each application is handled in the best possible way. Portworx allows operators to choose the IO profile that is best suited for their application. Depending on your application’s IO pattern, you can choose from the following five IO profiles:
- db: This is for databases that result in a large number of flush operations on the disk.
- db_remote: Implements a write-back flush coalescing algorithm to coalesce multiple syncs that occur with a 50ms window into a single sync.
- sequential: Optimizes the read-ahead algorithm for sequential workloads, such as backup operations.
- random: Records the IO pattern of recent access and optimizes the read-ahead and data layout algorithms for workloads involving short-term random patterns.
- auto: If you don’t know which IO profile to select, you can use the “auto” profile. Portworx continuously analyzes the IO pattern of the traffic in the background and applies the most appropriate pattern it sees.
Portworx also allows you to set an IO priority of high, medium, or low. This is applicable in scenarios where you have different storage backends/media participating in the Portworx cluster.
In addition to letting you set IO profiles and IO priority, Portworx allows you to ensure data locality for your application pods by leveraging STORK (Storage Orchestrator Runtime for Kubernetes). STORK allows stateful applications to enjoy the benefits of storage-aware scheduling via Kubernetes in production at scale. This means that pods for your stateful applications will be deployed on the same worker node that hosts a replica of your persistent volume. And in case of node failure or pod failure, a new copy of the pod will be deployed on the other node where the second replica of the volume exists (as long as there are enough CPU/memory resources available on the node). To leverage STORK, all you need to do is use “schedulerName: stork” in your yaml file. Below is an example of the Tanzu RabbitMQ cluster deployment yaml file using STORK:
apiVersion: rabbitmq.com/v1beta1 kind: RabbitmqCluster metadata: name: tanzu-rabbitmq-stork spec: image: registry.pivotal.io/rabbitmq/vmware-tanzu-rabbitmq:2020.12 imagePullSecrets: - name: vmware-tanzu-registry replicas: 3 resources: requests: cpu: 2 memory: 4Gi limits: cpu: 4 memory: 8Gi rabbitmq: additionalConfig: | cluster_partition_handling = ignore vm_memory_high_watermark_paging_ratio = 0.99 disk_free_limit.relative = 1.0 persistence: storageClassName: portworx-rabbitmq storage: "50Gi" override: statefulSet: spec: template: spec: schedulerName: stork containers: - name: rabbitmq imagePullPolicy: Always topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: app.kubernetes.io/component: rabbitmq
Storage Capacity Management Using Portworx Autopilot
Portworx Autopilot allows operators to create rules to automatically expand persistent volumes, and Portworx storage pools, rebalance Portworx storage pools for your VMware Tanzu Data Services. We looked at Portworx Autopilot in the previous blog, and the benefits that we discussed in that blog apply to all the Tanzu Data Services that you might want to use in your VMware Tanzu Kubernetes clusters.
Data Protection and Disaster Recovery
In addition to providing enterprise-grade Kubernetes storage, PX-Backup and PX-DR from Portworx also allow operators to streamline and centralize data protection and disaster recovery for VMware Tanzu Data Services. Instead of relying on individual backup and restore options like pgBackRest for Tanzu SQL with Postgres and Percona XtraBackup for Tanzu SQL with MySQL, operators can leverage PX-Backup as a consistent solution to protect all the different Tanzu Data Services and any other containerized applications that might be running on VMware Tanzu Kubernetes clusters. In addition to Kubernetes Backup and Recovery, operators also need to deploy a solution that helps them build DR architectures for their Tanzu Data Services. PX-DR allows operators to create synchronous (zero RPO) and asynchronous DR relationships between multiple Tanzu Kubernetes clusters, so they can easily failover or migrate their Tanzu Data Services between Kubernetes clusters running in a single data center or spread across multiple data centers.
All in all, if you are looking to leverage Tanzu Data Services to offer your developers self-service access to elastic, scale-out stateful applications on Kubernetes, you should pair it up with the Portworx Kubernetes storage to get the best of both worlds. You can increase your developer productivity and improve your operational efficiency at the same time. Here is a demonstration of VMware Tanzu Data Services with Portworx running on a VMware Tanzu Kubernetes cluster in action.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Bhavin Shah
Sr. Technical Marketing Manager | Cloud Native BU, Pure Storage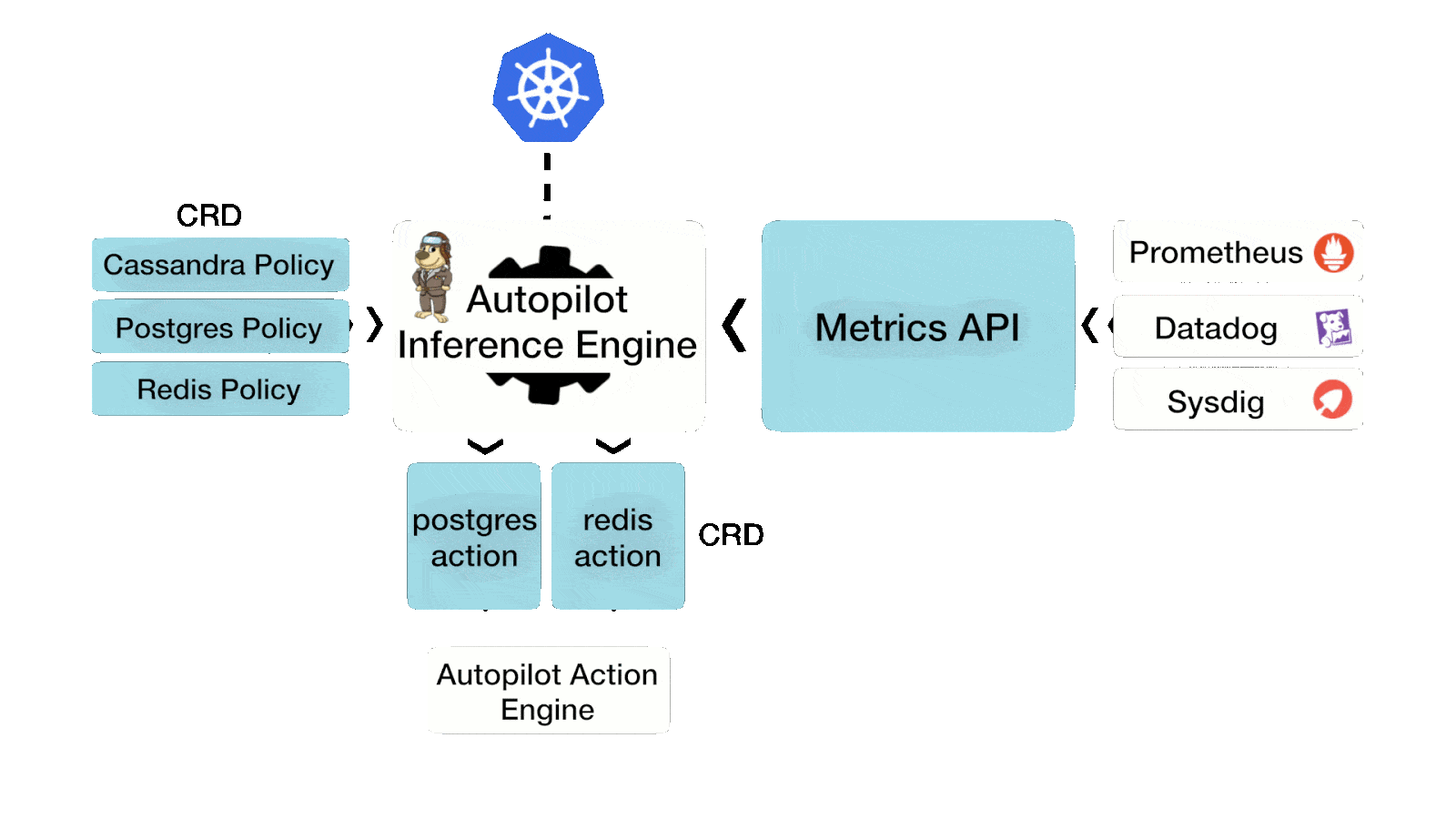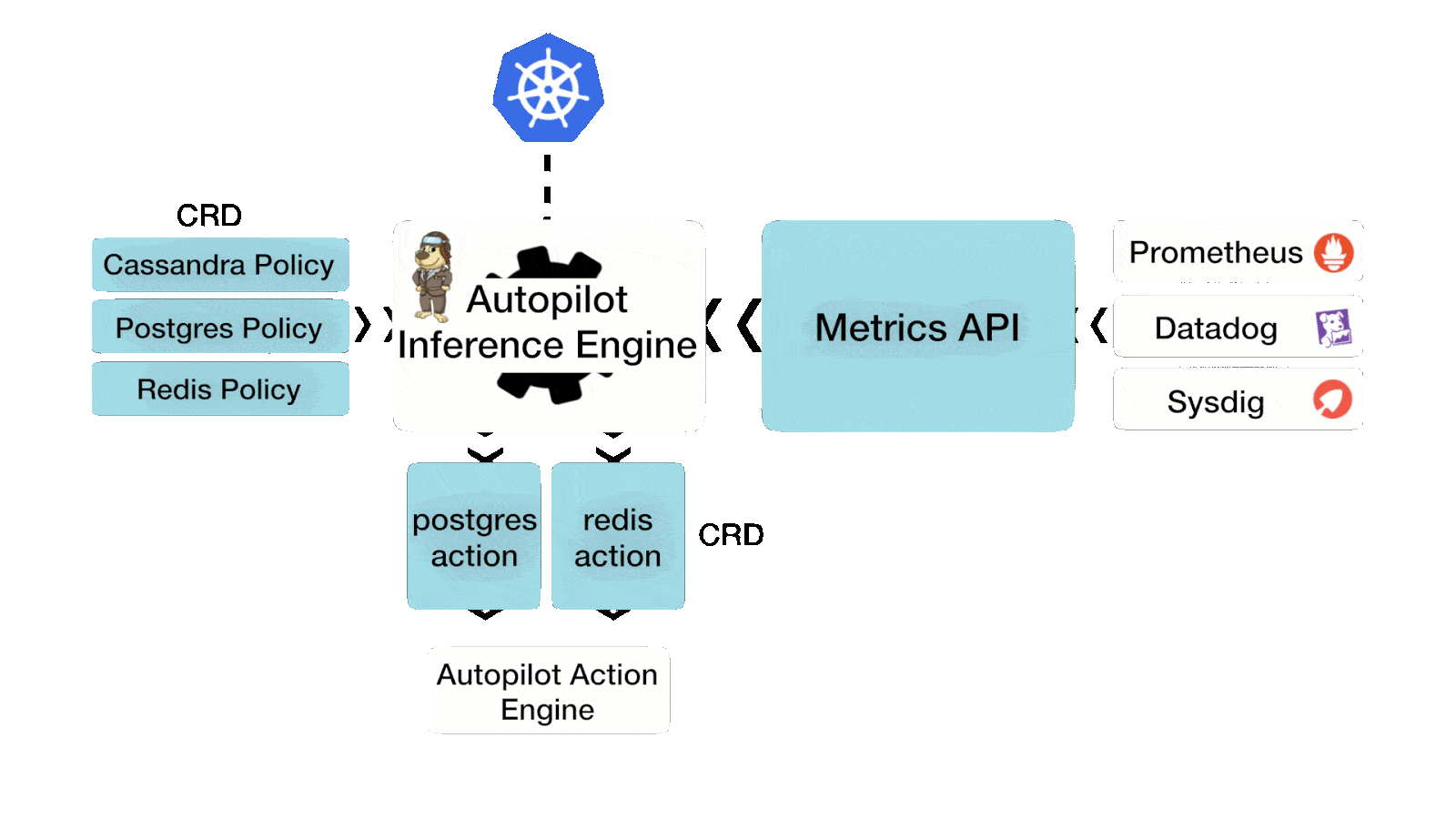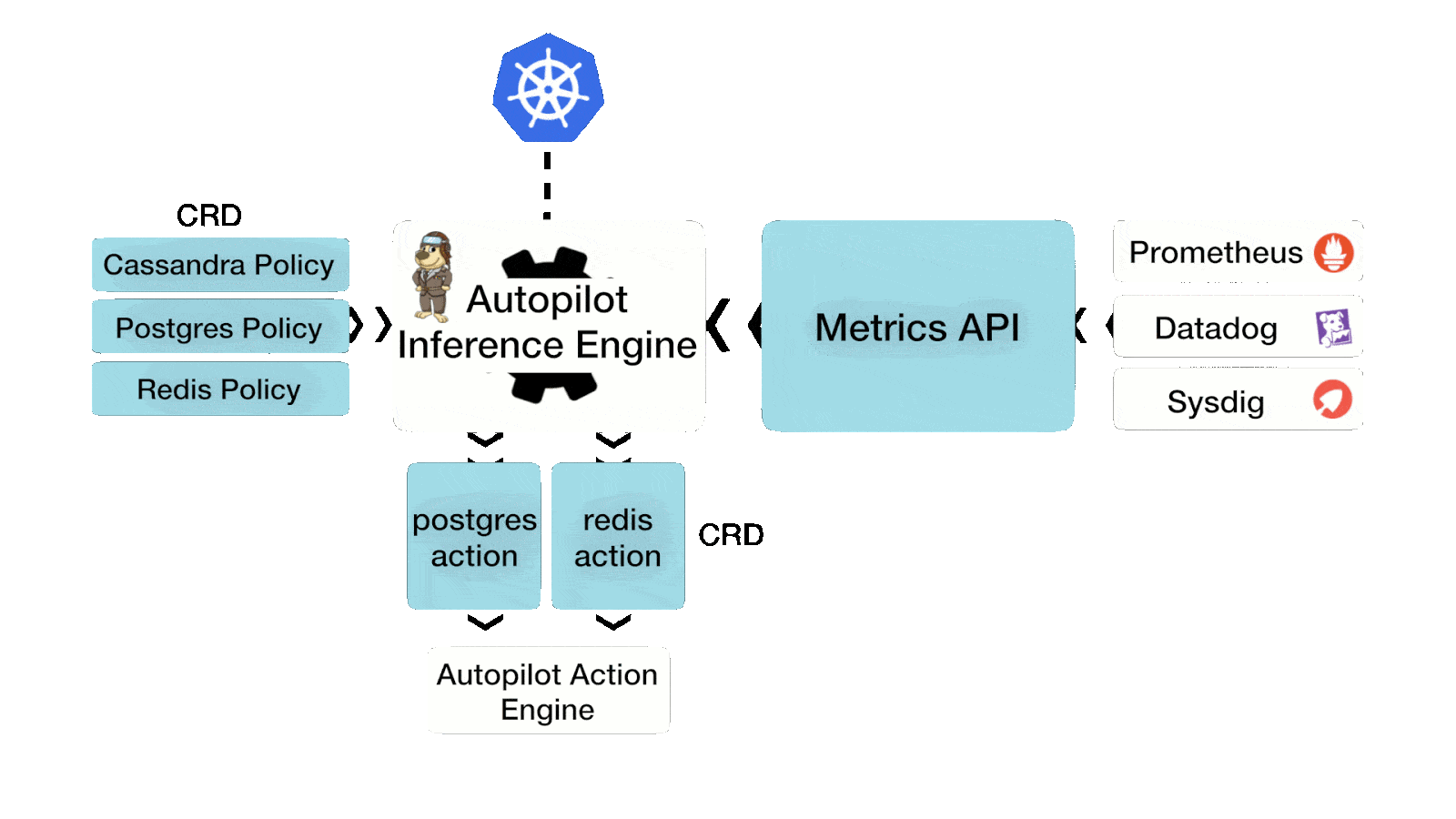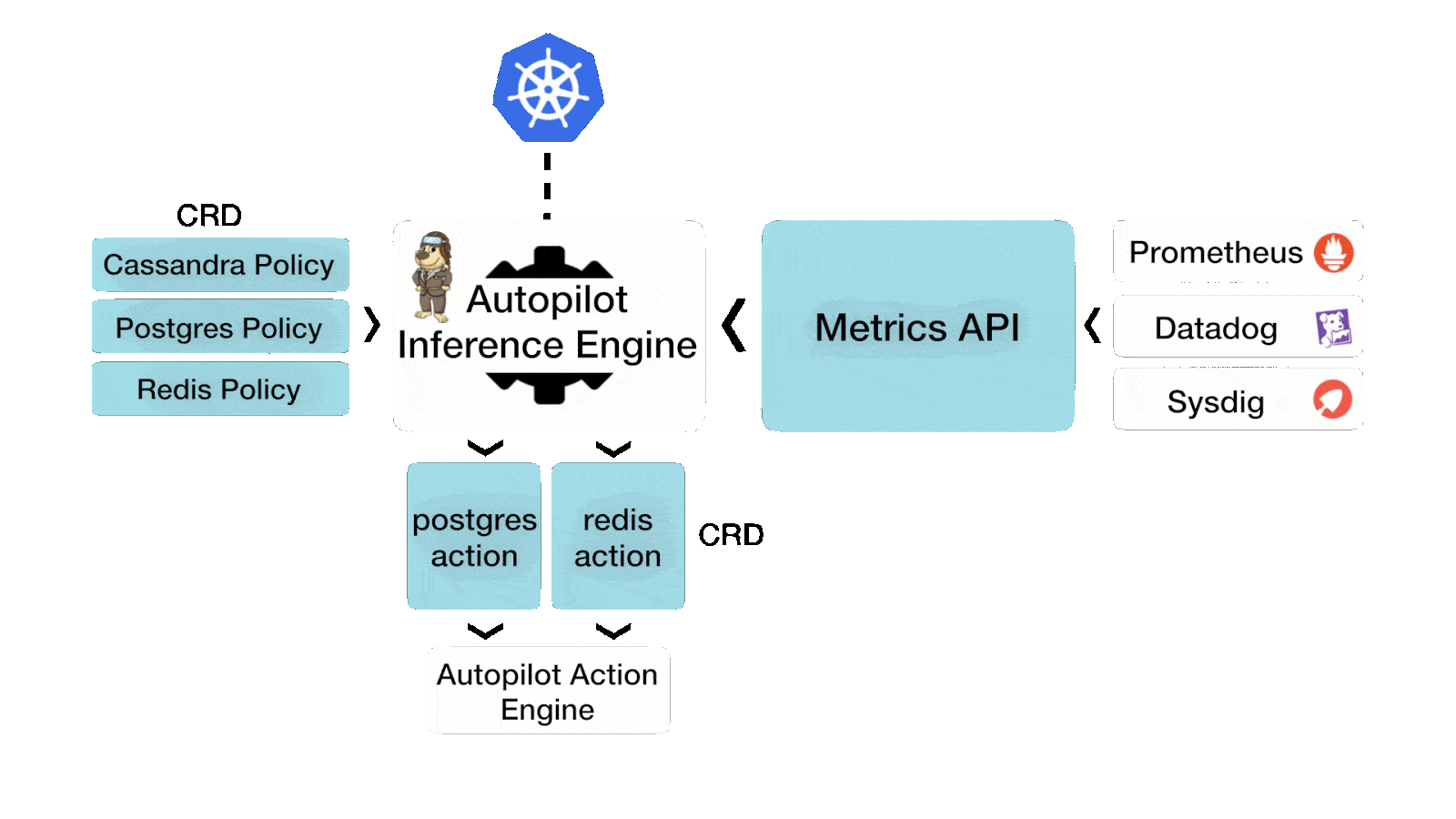
Automate storage capacity management for VMware Tanzu Kubernetes clusters using PX-Autopilot

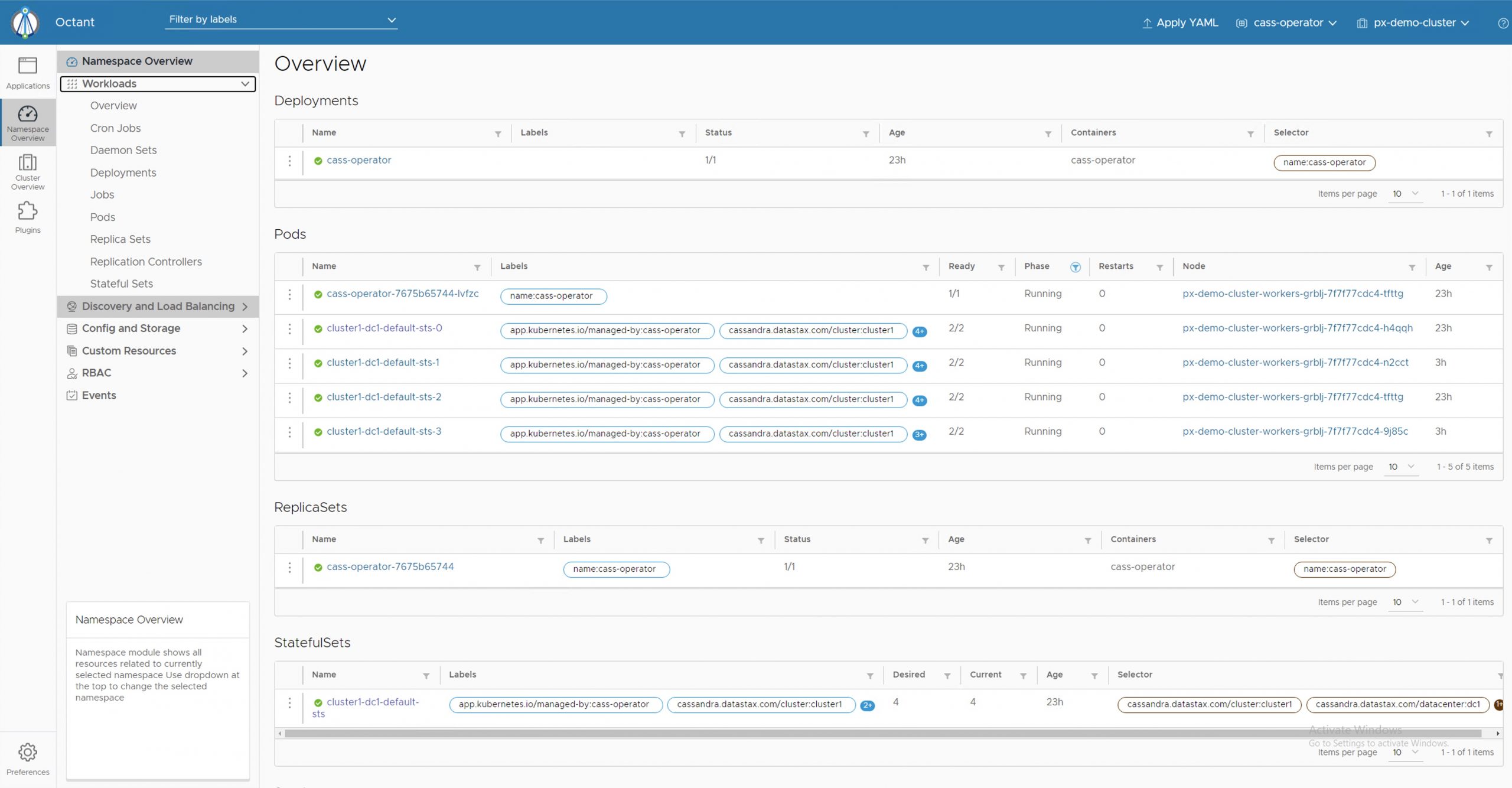
Deploying a highly available Cassandra cluster on VMware Tanzu with Portworx
Portworx Enterprise 2.8: deeper Pure integration, Tanzu support, and much more
