Break the Chains of Cloud Databases with Data on Kubernetes
Break the Chains of Cloud Databases with Data on Kubernetes
Managed Databases are a pretty common solution for storing persistent data for today’s cloud native applications. It’s easy to see why they are popular for DevOps teams because of the perceived operational burdens that they help to overcome, such as automatic patching, backups, and scaling. Having a managed database in place allows DevOps teams to focus on application development without getting bogged down by all of the toil of typical database maintenance. Despite these advantages, managed databases that are used with a cloud provider pose some challenges to teams using Kubernetes for their application platforms. In previous posts we’ve discussed what data is best for Kubernetes, and why your CSI Drivers can’t cut it – this blog post will explore some of the challenges with cloud managed databases and explore the possibilities of using a cloud-native solution for databases that run on Kubernetes.
Cloud Managed Databases – A Simple Example
In one regard, we love managed databases from our cloud provider. Public clouds offer a lot of options that we can choose from including SQL databases, NoSQL databases, or message queues like Kafka or RabbitMQ. Managed databases seem to remove the amount of work placed on our internal teams to manage these databases, and they do in many regards. However, in a multi-cloud environment these managed databases may require more administration from your DevOps team than they prevent. Consider this situation from a Platform Engineering team trying to service many development groups and different cloud services. For this example, we have a simple application running in Kubernetes that needs to store its data in a MongoDB database. The application architectures at a very basic level look like the diagram below.
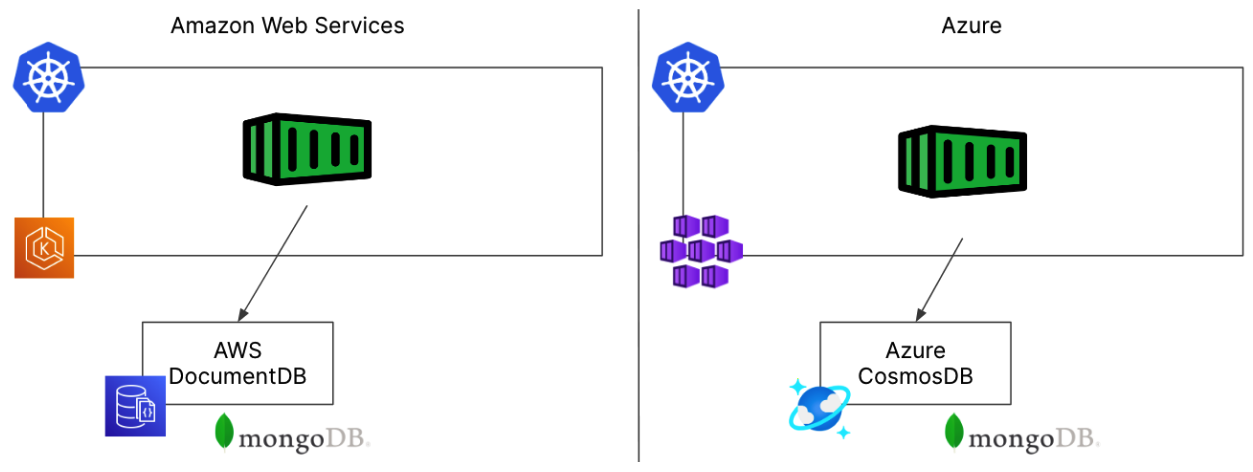
On the left side of the diagram we see our containerized app on AWS running in Amazon EKS and the MongoDB database is provided through the AWS DocumentDB service. On the right side of the diagram, we see the same application running in Azure with the app running on Azure AKS, and the MongoDB database provided by the Azure CosmosDB service. So far, these applications look pretty similar and the only real concern from our application teams seem to be that we need to understand the nuances between AWS DocumentDB and Azure CosmosDB. The commands to deploy those two applications are slightly different of course, but as seasoned DevOps professionals, we’re not really concerned about needing to maintain two different MongoDB databases in two different environments. But when we look a little deeper at what’s involved in managing our application, we come across several more areas that will require our attention, time, and effort. Beyond the basic differences with the databases, we have to configure several other items to make our databases production ready in each environment that we may not have considered initially.
From a security perspective, we need to configure access to these managed services. In AWS we would need to set up some IAM roles and policies, and in Azure we would need to configure Azure AD. Will the DevOps or Platform Engineering teams be able to configure these security items to provide access to the development teams or will they need to reach out to the cloud team(s) to provision them for us before we can deploy our applications?
From a networking perspective, we need to deploy a Virtual Private Cloud, subnets, and security groups for our AWS based environment. We’d also need to make sure that our EKS cluster can access the subnets where the DocumentDB lives. Does the EKS cluster run in the same VPC as our databases or will we need to set up some more complex routing to plumb all your VPCs together? Over on the Azure side, we’ve got similar things to configure but they use a different construct called VNets on their side so we’ll need to manage those separately.
From a data protection perspective, our AWS DocumentDB can automatically snapshot our data for storage of up to 35 days. We might need to augment this with manual snapshots to store our data for longer than this 35 day period. Over in Azure though, we’d need to learn the Azure Backup tool to handle the backups of our CosmosDB. Are we still OK learning two different backup methods across our two example clouds?
From a disaster recovery perspective, we’d need to configure snapshot replication for our DocumentDB so that our data is available in another AWS region in case we have a large geographical outage to AWS. On the Azure side, we may be using a Global Distribution of our CosmosDB so that our data is already in a second region. These are pretty different replication capabilities which will have different recovery plans should a disaster really occur. A few more items that are different across our cloud environments.
The above list is a simple example of how there are more services that need to be configured just to use managed database. Depending on your corporate policies, there may be additional services that need to be managed including audit logging, etc.
Cloud Managed Databases – A More Complex Example
In the previous example, we saw that our simple application using two different databases didn’t mean we only had to learn two different managed databases – we actually needed to learn a series of auxiliary services to properly use those databases in production. Now what if we have a more complex application that requires multiple databases and data services and we need to run it on multiple public clouds?
In this example, our application uses more than one database similar to how a microservices based application running in Kubernetes might be architected. This application still uses a MongoDB database, but also uses a message queue and mysql database.
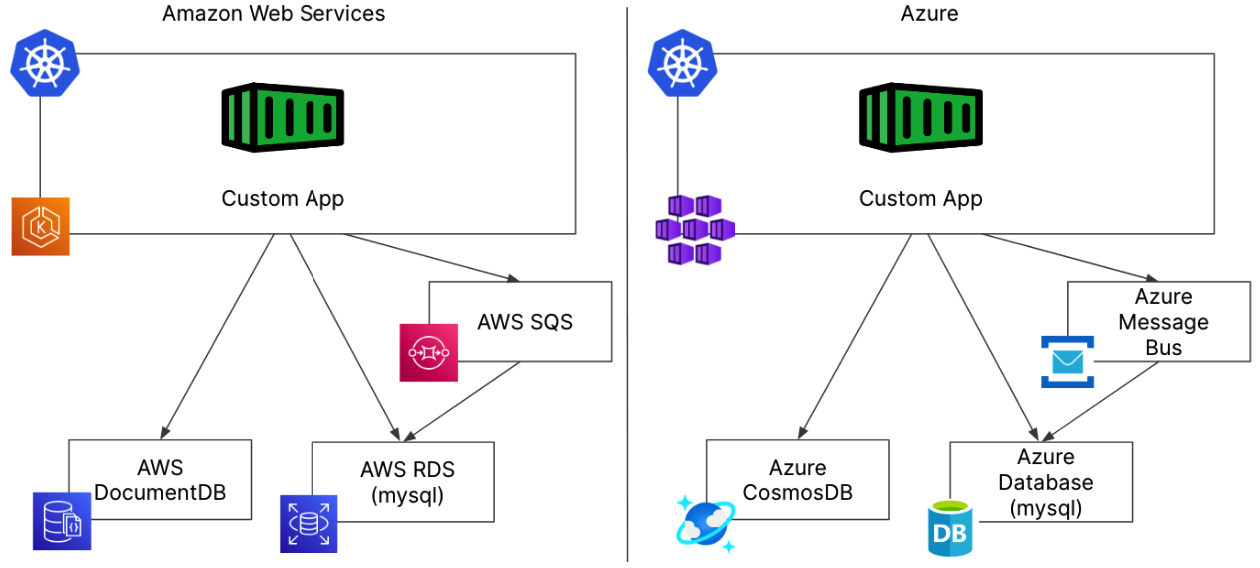
In this more complex but not uncommon example, we would face the same challenges from our previous example but all of those challenges are now amplified. Distinct configurations are necessary for each of these services to guarantee security, networking, backups, and disaster recovery requirements are met. Keep in mind this is all in addition to the way you deploy and manage the database or data service itself. You can quickly see how having a few of these applications would quickly create a lot of work for operations teams.
A multi-database application like this would cause even more complexity when using a managed service. Having three databases that may need to be in sync would be complicated to manage backups for data protection, and replication for disaster recovery could become exponentially more challenging. How would we ensure that all three databases could be restored to the same point in time? Can all of our databases be snapshotted together, or will we have to figure out which backup to restore for each database manually and just hope that it works?
The Alternative: Data on Kubernetes!
Instead of managing the bespoke complexities of each individual cloud and each individual service within that cloud, what if we could find a model that works the same across all of our environments, so that we only have to think about one configuration stack to manage?
This is precisely what Kubernetes has brought to our architectures for stateless applications already. We know that we can deploy our containerized applications consistently into any Kubernetes cluster regardless of what infrastructure (cloud or otherwise) that cluster is running on. In many cases, this is exactly what customers are doing – except those highly portable applications then become anchored to a managed database that holds their data.
What if we moved the databases into our Kubernetes cluster and managed our persistent data alongside our applications? Wouldn’t it be nice to see our applications deployed exactly the same way to two different environments? Think of all the operational toil that could be eliminated by using a consistent platform everywhere. This method also has the added benefit of letting us control our own data instead of relying on a public cloud to store it for us. For that reason, some of our compliance regulations can be more easily met.
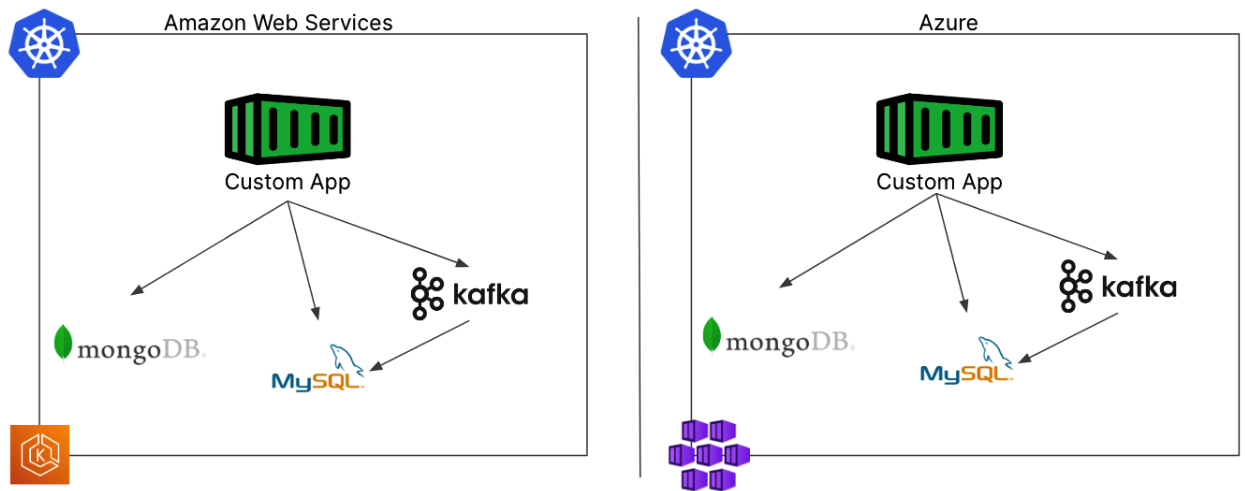
Observe how our diagram suddenly became simpler – now we only have to consider the lifecycle management of our databases one time, and they’ll work the same no matter where our Kubernetes cluster is deployed. No more custom configurations for every disparate environment, but a single deployment configuration that can be stored in version control, and managed along with your applications. Wouldn’t it be nice to manage your databases and data services with your GitOps solution like ArgoCD or Flux, instead of managing your containers with GitOps and your databases through some other method like a script or clickops?
Once our databases are deployed as containers, we can use Kubernetes native constructs to manage those databases as part of a single application configuration in Git. Database credentials can be stored as secrets which can be mounted by our application pods. Network Policies can ensure that only our front-end application has network access to the database, protecting unauthorized access. High Availability is provided by the Kubernetes scheduler and the basic desired state principles Kubernetes was designed on. But best of all is that the team managing Kubernetes can manage all of this without having to reach out to a cloud team for these requirements.
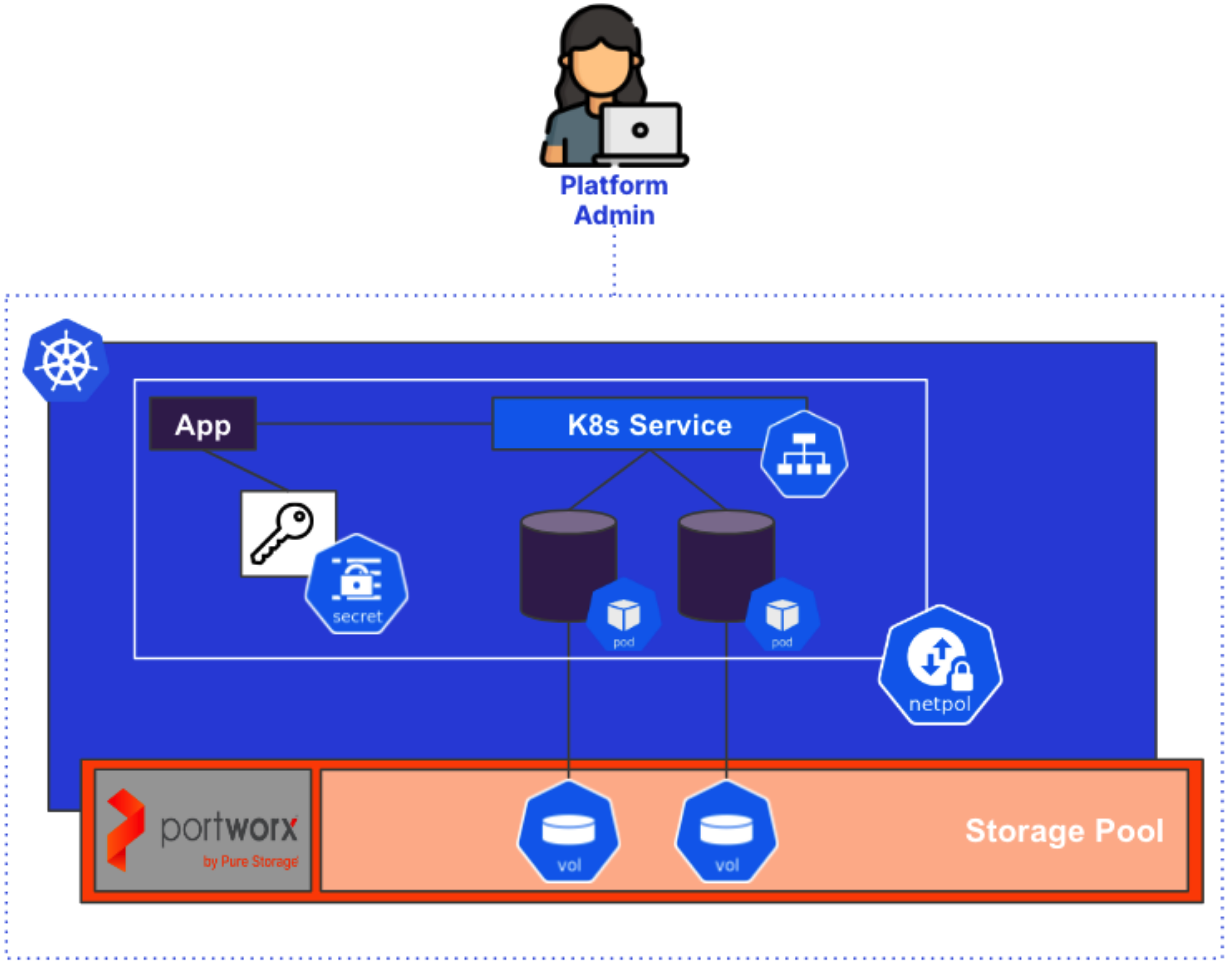
Raise the Anchors With Portworx
Even if we solve the challenge of reducing toil and becoming experts on each target cloud for our databases, we still need to take care of backups, disaster recovery, scaling, encryption and all of those individual tasks you were performing for each cloud. What if we could do this ONCE in order to reduce the cognitive load and toil for platform engineers struggling to keep up with multiple clouds? Portworx gives you all of these capabilities and provides consistency in the methods used to complete these tasks – no matter what infrastructure or public cloud you need to use.
Portworx provides the common storage services that databases need to run inside a Kubernetes cluster. Much like Kubernetes provides a consistent platform for containers to run in, Portworx provides a consistent data management platform for databases and data services. Portworx provides platform engineers with common tools for their toolbox that they need to manage persistent data within a Kubernetes cluster.
Portworx allows customers to present block devices to their Kubernetes clusters in the preferred way for the target environment during Kubernetes cluster creation. Those devices could be EBS volumes from AWS, Azure Disks from Azure, or Persistent Disks from Google Cloud, but could also be local disks in a bare metal server, or volumes presented from a hardware storage array if running on-premises. Presenting these devices becomes part of your Kubernetes cluster deployments, and once the Portworx storage cluster is running, your Kubernetes platform has just become a container storage platform as well!
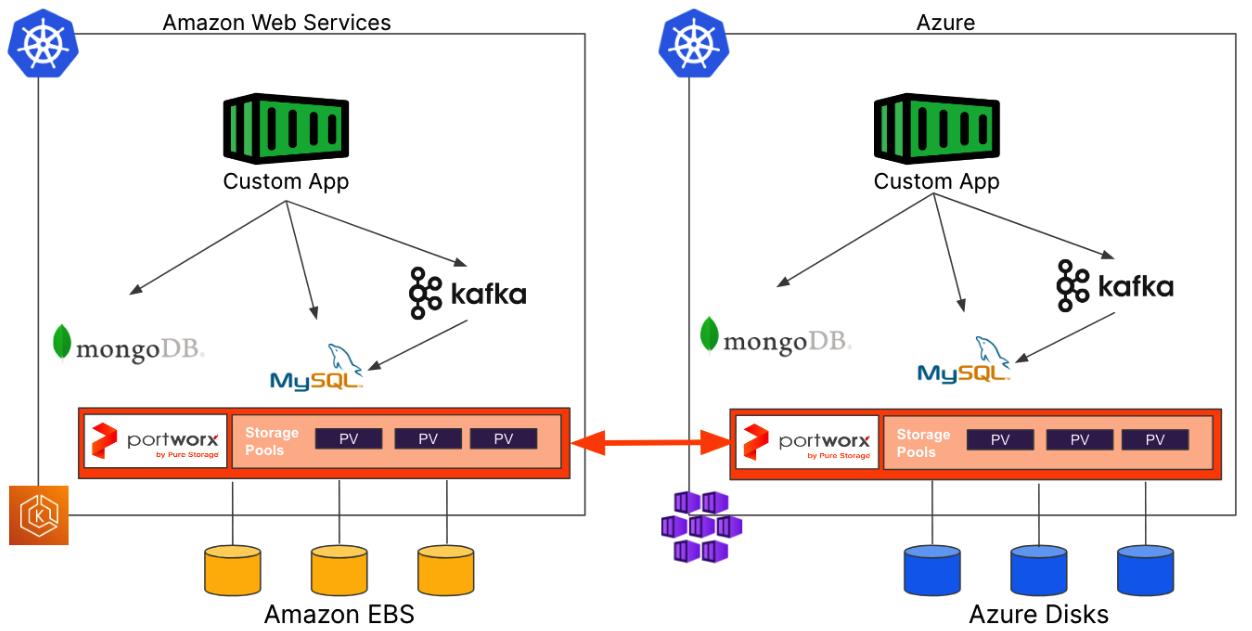
The Portworx storage platform enables teams to:
- Configure disaster recovery routines to failover applications to another cluster
- Automatically expand capacity when low on space without user intervention
- Encrypt data at rest and in transit
- Schedule backups for applications based on namespaces or tags
- Replicate data across nodes or zones for high availability
- Configure authorization rules to define what pods can access persistent volumes
- Provide performance for applications that need high throughput or IOPS
- Leverage group snapshots to take application consistent backups of multiple databases simultaneously.
The best part is that all of these capabilities can be configured with your existing Kubernetes tools like our beloved YAML manifests, making them simple to manage across a fleet using GitOps solutions in a declarative manner.
Managed Databases on Kubernetes
Some of us might not be ready to completely remove managed databases from our environments. It’s possible that we don’t have expertise to manage some of these databases and would like a more white glove approach to our database management, even if we’re running them on Kubernetes.
Portworx has you covered here as well. Portworx Data Services (PDS) is a managed database solution that is specifically designed for Kubernetes. From the PDS portal, you can choose from any of our twelve (at the time of this writing) data services to deploy right into your Kubernetes clusters. You’ll have the ability to choose the number of replicas for the database, the number of processors, amount of memory and of course storage capacities. After deployment the databases can be backed up/restored, scaled, upgraded, and resized from the same portal which is also equipped with an API if that is a preferred option.
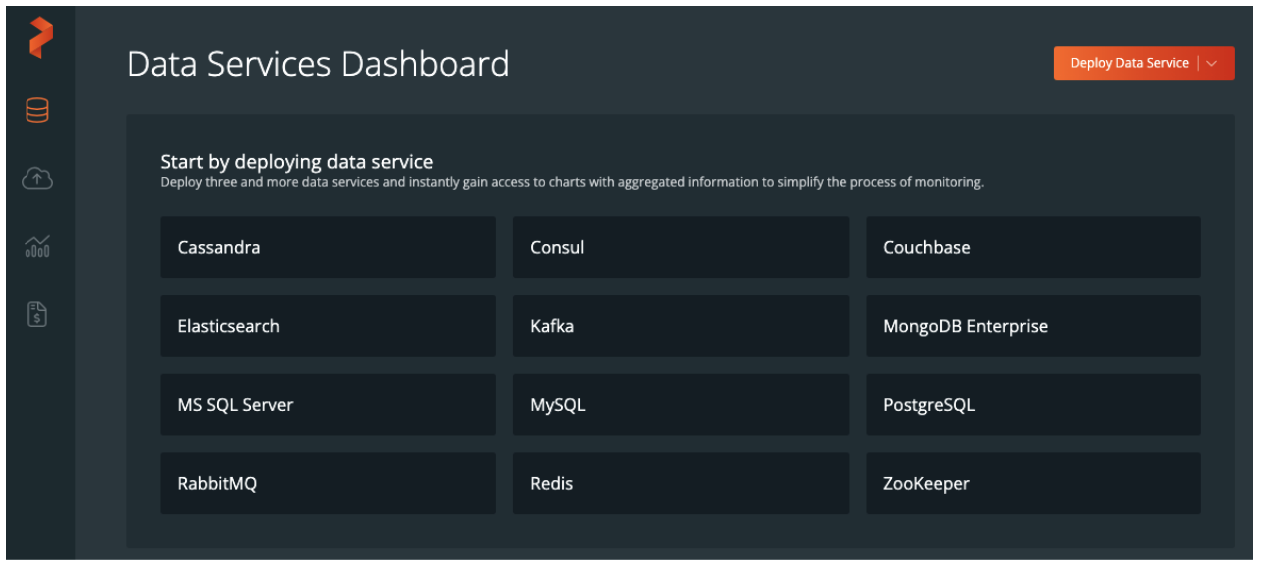
These data services can then be used across any of your Kubernetes clusters, regardless of where they are located, as long as they have outbound Internet access to our SaaS control plane.
Summary
Multi-cloud is difficult to support and we’re all just an acquisition away from having to add another new cloud environment to manage, along with all of the supporting services that come with them. Why not leverage the Portworx storage platform to turn your Kubernetes clusters into a common platform for all of your cloud-native applications and reduce the amount of attention, time, and effort you’re spending configuring bespoke cloud offerings?
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!

Eric Shanks
Principal Technical Marketing ManagerExplore Related Content:
- dynamic
- Platform Engineering
- secure