I’ve spent a lot of time recently with users who are deploying storage for cloud-native applications, and here’s what I’m hearing most: These cloud-native applications don’t want volumes — they want stateful data services such as persistence across machines, across availability zones, and even across clouds. They want an object store or a global namespace. They want to be able to self-describe the specific properties of stateful services, such as needing encryption, a certain capacity, or even a class of service. And they don’t want to have to manage the underlying physical resources like SSDs versus SATA drives, or EBS provisioned IOPS volumes versus Google GCE persistent disks.
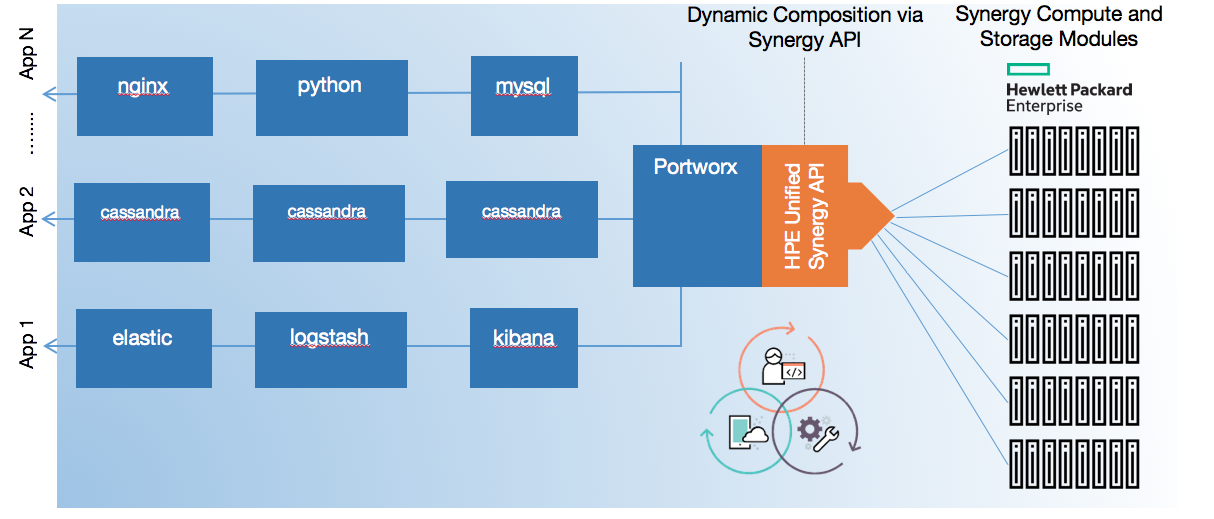
At Portworx, we’re building a data service layer for these cloud-native applications. With Portworx, any application, such as Redis, Kafka, MySQL, or even WordPress, can run on any server, in any cloud, on any scheduler, with a guaranteed SLA for the services they subscribe to.
Our key differentiation is how infrastructure is provisioned — or even thought of. In an old-school way of thinking, many of our competitors are adding connectors from containers to legacy SANs and NAS. This means users still have to provision and manage the legacy storage separately from the applications. Conversely, Portworx simply deploys the applications on a cloud of servers and each application requests the resources it needs.
What users really want is freedom from managing their infrastructure, including any specific cloud provider. The number one goal of cloud enablement is infrastructure independence, and Porworx container data services gives you the protocol to make it happen. For the first time, you get a contract between your applications and your physical resources, whether it’s in your own data center or in the cloud. And that’s a contract that frees you to manage what’s really important in your business.
Share
Subscribe for Updates
About Us
Portworx is the leader in cloud native storage for containers.
Thanks for subscribing!